2021-数据库开发-Lec6-数据库模式设计之层次结构
0.1. Lec6-数据库模式设计之层次结构
1. 处理层次结构(Hierarchical Data)
- 树状结构(Tree Structures)
- 历史
- 层次数据库
- 网状数据库:灵活但是还是存在困难
- 关系型数据库
- 在效率、灵活等方面找到了一个平衡点
- 没有必要将配置文件存储到数据库中,存储在文件系统也是很好的一个选择
- 直到关系理论出现,数据库设计是"科学(science)“而非"工艺(craft)”
- 层次性数据广泛存在(XML,LDAP,BOM…)
- 层次结构复杂度在于
- 访问树的方式
- 历史
2. 树状结构 VS. 主从结构
- 父子结构(parent/child link)–tree structure
- 主从结构(master/detail relationship):通过外键,来形成主从结构
- 差异
- 树状结构保存只需要一张表:代表层次的树。所有节点的类型都相同,节点的属性都相似,表(节点)和自己有主从关系而不是其他表
- 深度:主从结构没有深度的概念
- 所有权:主从结构可以明确外键完整性约束,但是树状结构不需要定义所有权
- 多重父节点:单一父节点描述父子关系(子节点引用父节点),先解决单一父节点的树
- 参考书籍:Fabian Pascal:Practical Issues in Database Management(Addion Wesley)
3. 层次结构的实际案例
- Risk exposure
- 档案位置
- 原料使用
- ……
- 不同的案例具有不同的基本特征
- 通常,树中的节点数量偏小。实际上,这也是树的优点,便于高效检索
1 | |
4. 用SQL数据库描述树结构
- 只要对象的类型相同,而对象的层树可变,其关系就应该被建模为树结构
- 在数据库设计中,树通常三种模型
- Adjacency model 邻接模型
- 层次中父节点id作为子节点id的一个属性pid,不能确定兄弟节点的排序
- 难以处理的,是递归的
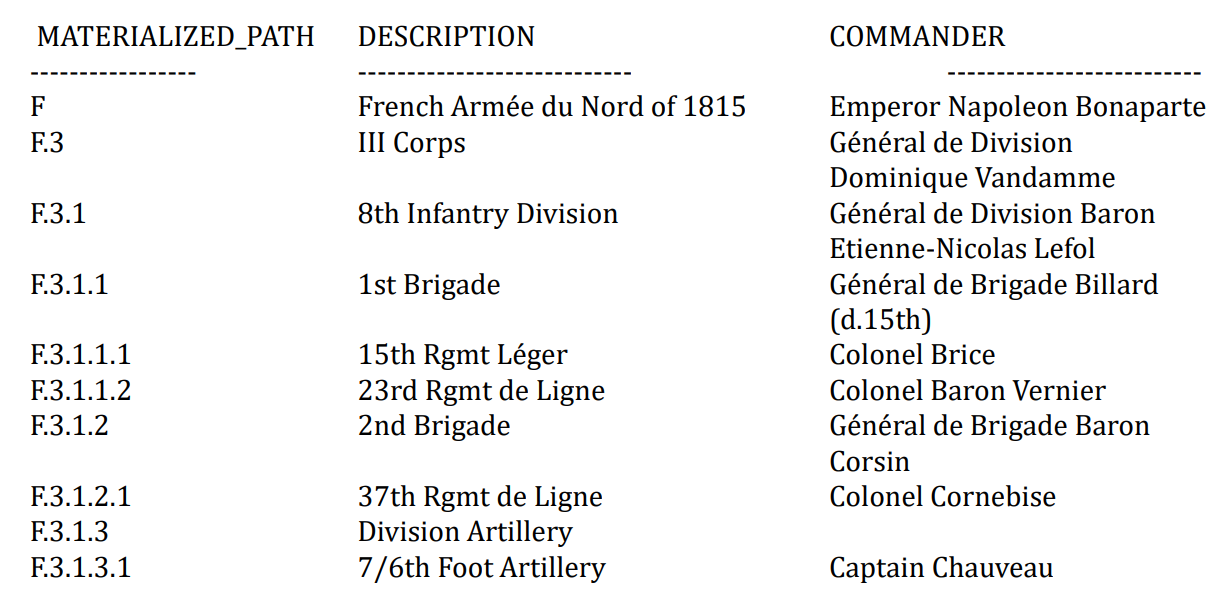
- Materialized path model 物化路径模型
- 将树中间的每一个节点和在树中的位置描述成数据的结合
- 是所有子节点的祖先节点的id的串联(1.2.3)
- 能够知道兄弟节点之间的排名,家谱
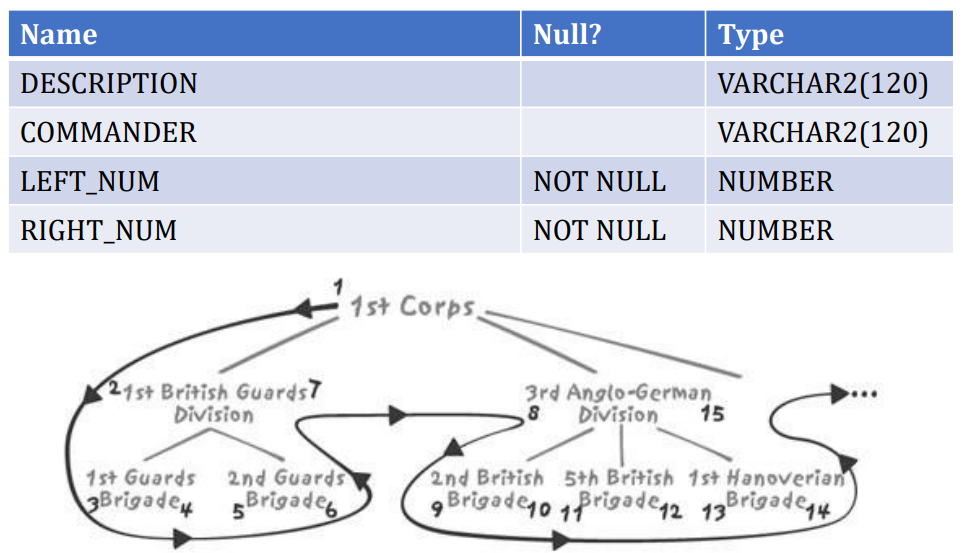
- Nested set model 嵌套集合模型 1996
- 每一个节点被赋予了一对数字(left number, right number)
- 父节点的左数字和右数字之间包含了它所有的子节点的左数字、右数字
- Adjacency model 邻接模型
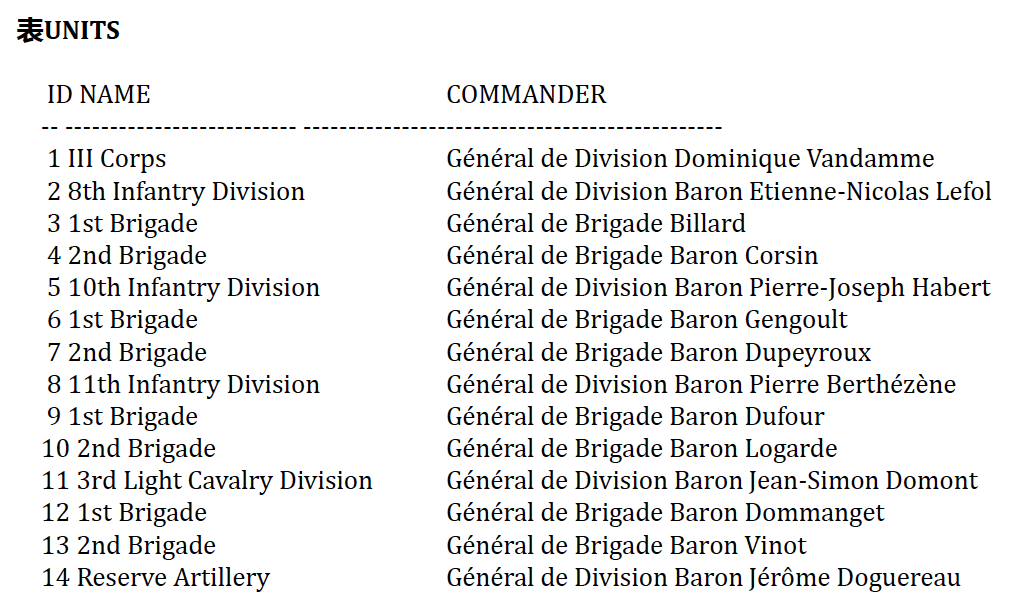
- 数据来源
5. 树的实际实现
5.1. 邻接模型
- ADJACENCY_MODEL
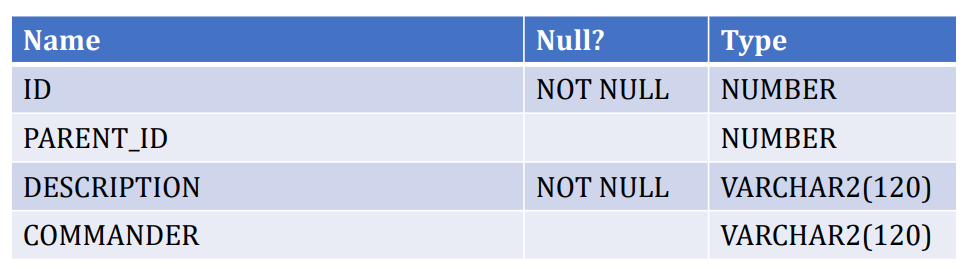
- 表的每一行描述一个部队,parent_id指向树中的上级部队

5.2. 物化路径模型
- MATERIALIZED_PATH_MODEL
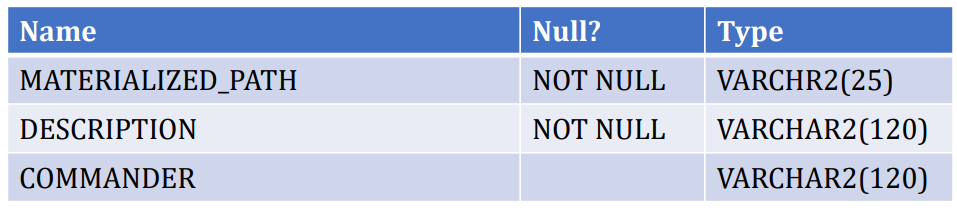
- 表中有两个索引,在materialized_path上的唯一性索引以及在commander上的索引,正确的设计应该增加id字段。
5.3. 嵌套集合模型
- NESTED_SETS_MODEL
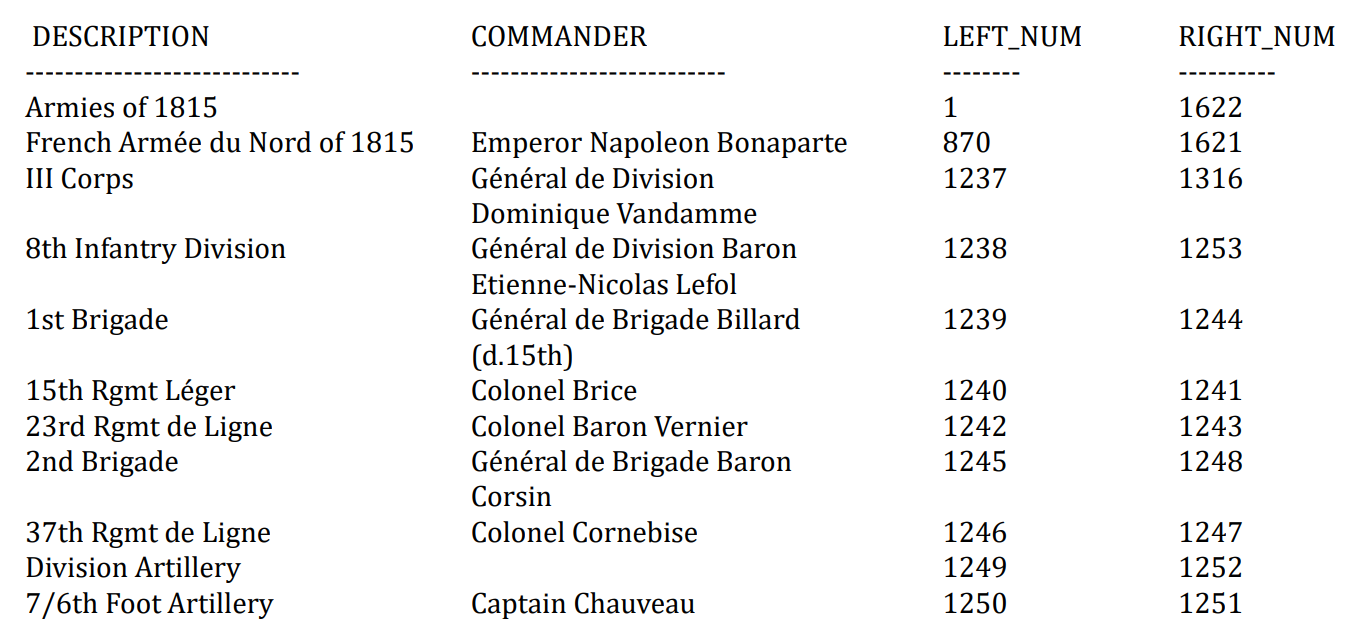
6. 用SQL访问树的结构
- 为了检查效率和性能,分别用不同模型解决如下两个问题:
- 法国将军Dominique Vandamme指挥哪些部队,以缩排方式或简单列表的方式显示他们。注意,所有的commander字段都构建了索引 (简称Vandamme查询)
- Scottish Highlanders的每个团各属于哪个部队(自底向上的查询)。在部队的名称.(description字段).上没有索引, 唯- -的方法是在description字段中查找"Highland" 字符串,在没有任何全文索引的情况下,这个问题简称highland问题
- 注:层次结构Corp-division-brigade regiment
- Oracle
6.1. 自顶向下查询:Vandamme 查询
6.1.1. 邻接模型
connect by < a column of the current row > = prior a column of the previous rowconnect by < a column of the previous row > = prior a column of the current row
1 | |

- 邻接矩阵:递归实现


- 添加排序:加粗部分完成排序(优化器会避免出现重复计算)

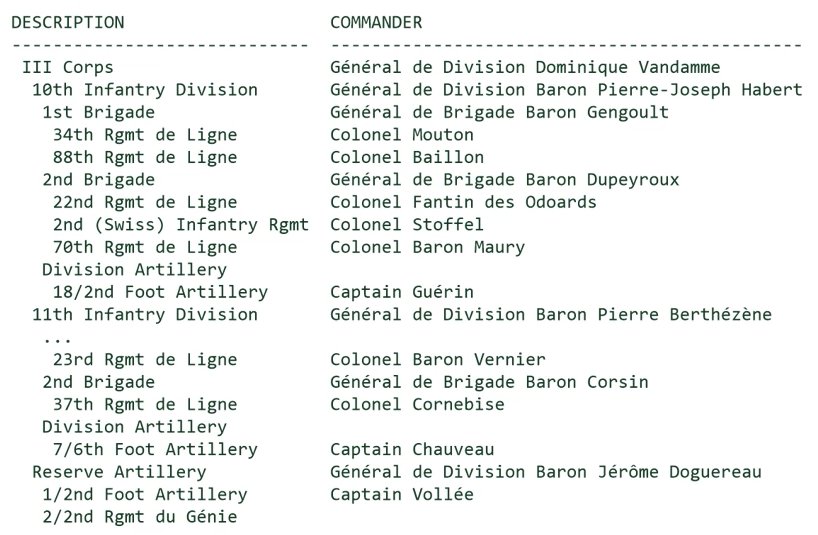
- 那么MySQL呢?两个方法
- 手动union
- 在一个查询汇总多次连接
- 前提都是已知深度(人工获取)

6.1.2. 物化路径模型
- 查询编写不困难
- 计算由路径导出的层次不方便
- 假设mp_depth()函数返回当前节点深度

6.1.3. 嵌套集合模型
- 很简单,某节点的后代的 left_num 和 right_num 都会在该节点的 left_num 和right_num 范围内

- 缩排怎么办?

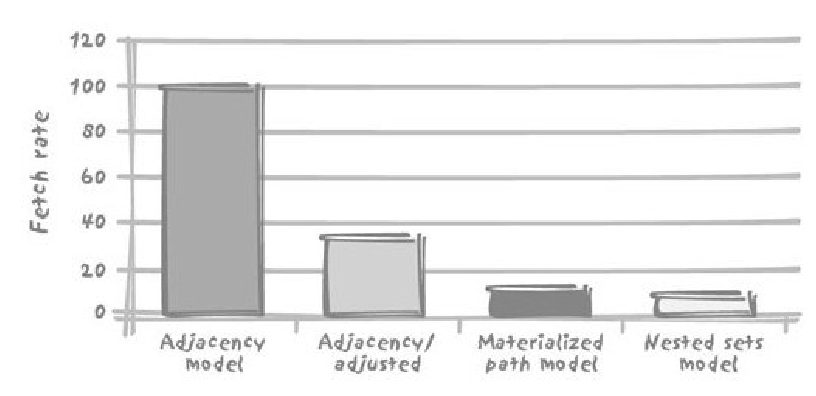
6.1.4. 比较各模型下的Vandamme模型
- 返回40条记录,循环执行各个查询5000次,比较每秒返回的记录数
- 邻接模型最高:parentId
- 物化路径模型
- 计算深度:字符串相关操作效率低
- 缩排:反复处理字符串效率低
- 嵌套集合模型:
- 查找子代完胜其他模型
- 缩排成本太高了
- 改进:每个节点都冗余存储深度,但是维护成本高:树结构不改变、不需要所有节点排序时最好。

6.2. 自底向上访问:Highland查询
- 在 description 字段中查找“ Highland ”字符串
- 必然导致完整的表扫描:无法使用索引
- 不同模型下 Highland 查询的差异
6.2.1. 邻接模型
Connect by 非常容易实现:Connect by不是关系操作


6.2.2. 物化路径模型
- 仅找出适当的记录并缩排显示算容易
- 重复记录的问题
- 顺序的问题



6.2.3. 嵌套集合模型
- 动态计算深度依旧是个问题
- 不要显示人造根节点
- 硬编码最大深度(为了缩排显示)

6.2.4. 比较各种模型下的Highland查询
由于邻接模型中会有重复语句,我们可以使用有效结果的行数来衡量
6.2.5. 一些问题
- 物化路径不该是KEY,即使他们有唯一性:主键最好不要经常被更新
- 物化路径不该暗示任何兄弟节点的排序
- 所选择的编码方式不需要完全中立
7. 聚合来自树的值
- 一共有2个大部分
- 保存叶节点的值
- 计算某个值散布在整个树中的百分比
7.1. 对保存于叶节点的值做聚合

7.2. 计算每一层的人数
7.2.1. 计算每一层的人数(邻接模型)

7.2.2. 计算每一层的人数(物化路径)

7.2.3. 不同模型的性能
- 执行查询5000次,比较单位时间返回的记录数
7.3. 散布在各层的百分比
- 假设我们经营魔药。每种魔药由多种成分( ingredient )组成,处方 recipe 列出成分及百分比。处方可以共享某种“基础魔药”,以复合成分 compound ingredient )的形式表示。
- 百分比被分到了每一个部分中
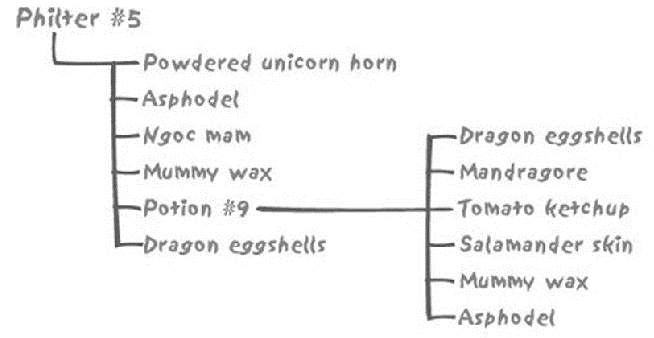
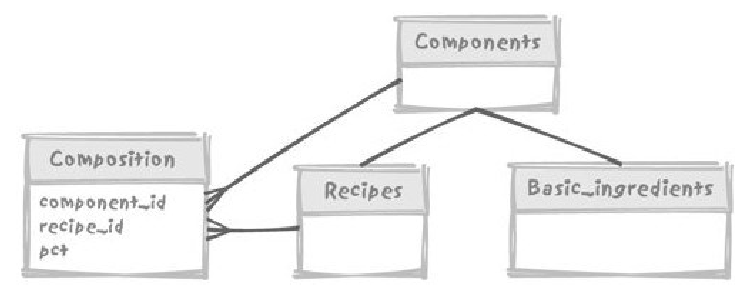
- 某一种可以选择的建模方法
- Components 表为通用类型
- 它有 recipes 和 basic_ingredients 两种子类型
- Composition 表保存处方成分(可以是处方或基本成分及其数量)


7.4. 树状结构的问题
- 本章的方法,在数据量很少的情况下效果令人满意
- 对大数据量的处理“像老爷车一样慢”
- 同样可以采用非规范化模型、或基于触发器的扁平化数据模型。
- 不建议对关系模型“屡遭诟病的缓慢本性”反规范化,这很容易遮掩程序设计中的问题。
- 不过, SQL 确实缺乏处理树结构的强大的、可伸缩的手段。
2021-数据库开发-Lec6-数据库模式设计之层次结构
https://spricoder.github.io/2021/05/02/2021-Database-Development/2021-Database-Development-Lec6-%E6%95%B0%E6%8D%AE%E5%BA%93%E6%A8%A1%E5%BC%8F%E8%AE%BE%E8%AE%A1%E4%B9%8B%E5%B1%82%E6%AC%A1%E7%BB%93%E6%9E%84/