2021-数据库开发-Lec7-对冗余的控制(反范式模式)
Lec7-对冗余的控制(反范式模式)
- 第一范式是一个字段只有一个值:存储和使用上的要求。比如身份证号的里面的年龄不能使用(拆分字段来使用不满足第一范式)
- 第二范式是一条记录只能被唯一主键标识
- 第三范式是一个字段全部和一个字段是没有函数依赖,比如年龄和出生日期
- 打破范式是为了引入可控制的冗余
1. Consider the Introduction of Controlled Redundancy
- Determine whether introducing redundancy in a controlled manner by relaxing the normalization rules will improve system performance.
- 放弃规范化,来控制冗余
- 打破规范
- 规范的打破导致实现的复杂化
- 规范的弱化会降低灵活性
- 规范的弱化会让更新变慢、查找变快
- 系统有低修改性和高查询率则选择打破规范是很好的选择。
2. Denormalization
- Refinement to relational schema such that the degree of normalization for a modified table is less than the degree of at least one of the original tables.
- Also use term more loosely to refer to situations where two tables are combined into one new table, which is still normalized but contains more nulls than original tables.
3. Consider the Introduction of Controlled Redundancy
- Consider denormalization in following situations, specifically to speed up frequent or critical transactions:
- Pattern 1 Combining 1:1 relationships 合并一对一关系
- Pattern 2 Duplicating nonkey columns in 1:* relationships to reduce joins 一对多复制非关键字属性
- Pattern 3 Duplicating FK columns in 1:* relationships to reduce joins 一对多复制外部关键字
- Pattern 4 Duplicating columns in : relationships to reduce joins 多对多关系复制属性
- Pattern 5 Introducing repeating groups 引入重复组
- Pattern 6 Creating extract tables 合并基本表和查找表,创建提取表
- Pattern 7 Partitioning tables 分区
- 逆规范化是违反三范式的
3.1. Pattern 1 Combining 1:1 relationships
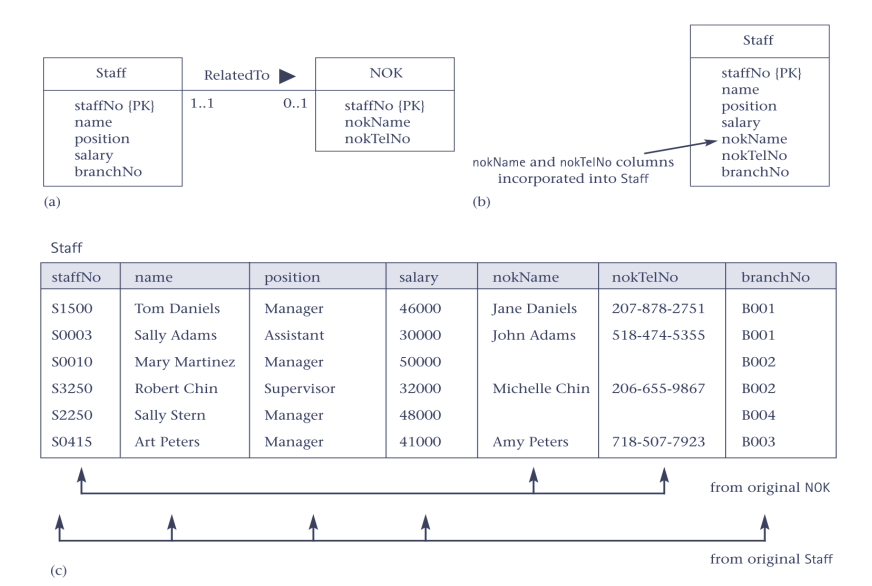
- 大量的空间浪费
- Null的问题
3.2. Pattern 2 Duplicating nonkey columns in 1:* relationships to reduce joins
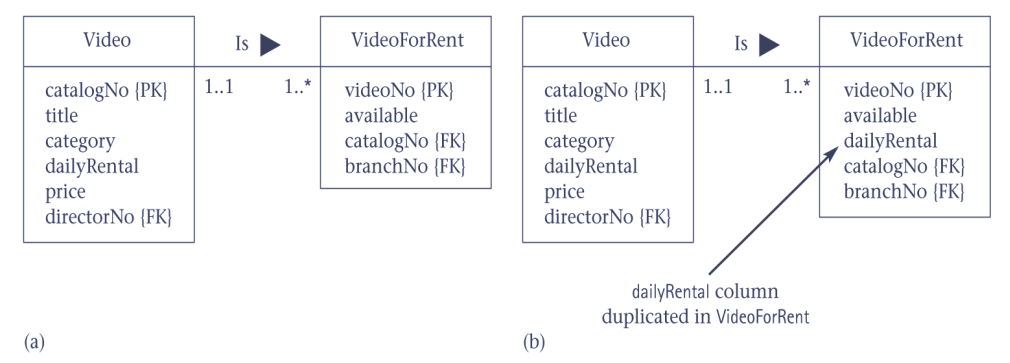
- 可能需要触发器来同步修改属性
- 额外注意
- 钱的属性一般都要打破范式存储:订单应该是实际的价格
- 历史价格的计算
3.3. Pattern 3 Duplicating FK columns in 1:* relationship to reduce joins
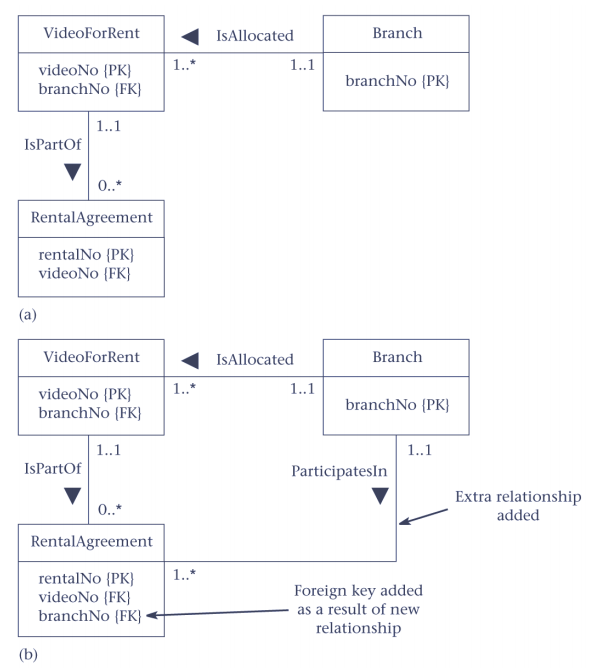
- A要访问C,需要通过B,那么可以使用这个模式来避开B表
3.4. Pattern 4 Duplicating columns in : relationships to reduce joins
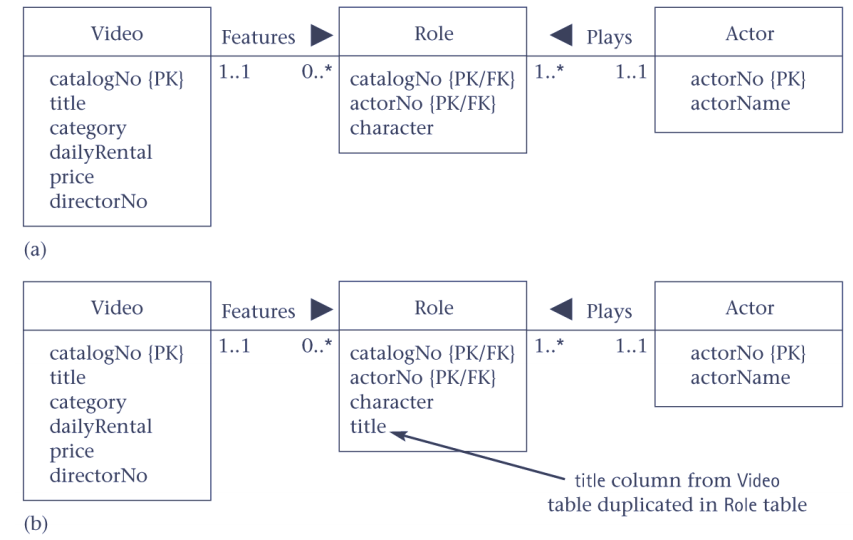
3.5. Pattern 5 Introducing repeating groups
- 引入地址、电话号码
- 将重复组到放到原表中:重复组数量不大、静态的
- 主表中存放缺省的一个地址和电话号码,避开连接查询
3.6. Pattern 6 Creating extract tables
- Reports can access derived data and perform multitable joins on same set of base tables. However, data report based on may be relatively static or may not have to be current.
- Can create a single, highly denormalized extract table based on tables required by reports, and allow users to access extract table directly instead of base tables.
3.7. Pattern 7 Partitioning tables
- Rather than combining tables, could decompose a table into a smaller number of partitions.
- Horizontal partition: distribute records across a number of (smaller) tables.
- Vertical partition: distribute columns across a number of (smaller) tables. PK duplicated to allow reconstruction.
- Partitions useful for applications that store and analyze large amounts of data.
2021-数据库开发-Lec7-对冗余的控制(反范式模式)
https://spricoder.github.io/2021/05/02/2021-Database-Development/2021-Database-Development-Lec7-%E5%AF%B9%E5%86%97%E4%BD%99%E7%9A%84%E6%8E%A7%E5%88%B6(%E5%8F%8D%E8%8C%83%E5%BC%8F%E6%A8%A1%E5%BC%8F)/