2020-数据管理基础-ch10-更新事务
ch10-更新事务
1. 事务
1.1. 什么是事务
- 事务是将一个进程执行的许多数据库操作打包在一起的一种方式,因此数据库系统可以提供几种保证,称为ACID属性。
- 当现实世界中发生更改企业状态的事件时,将执行程序以相应的方式更改数据库状态。
- 这样的程序被我们称为事务。
- 每一个事务的运行必须要保证数据库状态和企业状态的一致。
1.2. 事务编码
1 | |
- 开始事务
- 结束事务:
exec sql commit work;orexec sql rollback work;
1.3. 事务的例子
- RequestBalance交易:在数据库中读取客户的余额并将其输出
- 在用户转账的时候,账户的金额会出现短暂的不一致现象
- 不一致结果:钱转出但是没有转入(中间状态)
- 当前状态检查错误,在上面的中间状态,柜员1将钱从同一客户的帐户A转移到帐户B,而柜员2通过添加A和B的余额来进行信用检查,如果此时状态为A刚转出,B还没有转入,则会出现问题
- 不确定何时将变为永久性:至少,我们想知道什么时候可以安全发放资金:如果系统崩溃,不要忘记我们这样做了,那么只有磁盘上的数据才是安全的。
1.4. 事务的特点
- 因此,除了执行普通程序外,还对执行事务提出了其他要求:(ACID 属性)
- Atomicity 原子性
- Consistency 一致性
- Isolation 隔离性
- Durability 持久性
1.4.1. 原子性
- 作为事务一部分的记录更新集是不可分割的(要么全部发生,要么全部不发生)。
- 即使发生崩溃也是如此。
1.4.2. 一致性
- 对数据元素的完整事务转换将数据库从一种一致的状态转变为另一种一致的状态。
- 而不会出现破坏一致性状态的状态
1.4.3. 隔离性
- 即使事务同时执行,对于每个成功的事务,它似乎也已与其他事务按串行计划执行。
- 事务不可以被混行操作
1.4.4. 持久性
- 事务提交后,对数据所做的更改将在任何计算机或系统故障中幸免。
1.5. 数据库上的操作
- 读操作:Ri(A):标识号为i(Ti)的事务读取数据项A。
- 写操作:Wj(B):事务Tj写B。
- 更新语句将导致很多操作:
Rj(B1) Wj(B1) Rj(B2) Wj(B2) . . . Rj(Bn) Wj(Bn)
1.6. 历史和调度
- 通过有时会延迟某些操作并偶尔坚持某些事务中止来提供隔离保证。
1.6.1. 串行调度
- Tx的所有操作均按顺序执行,而不会与其他事务交织。
1.6.2. 调度器
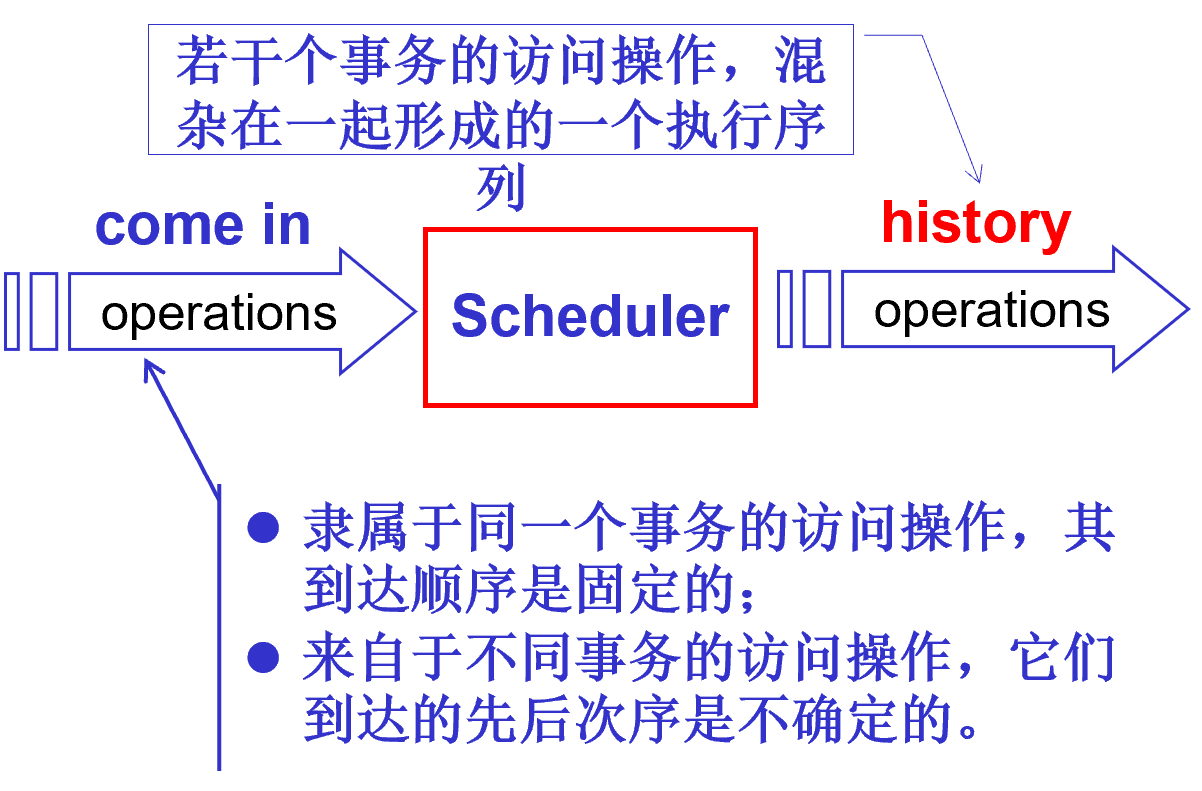
- 输入输出
- 达到调度器的操作是确定的
- 但是在调度器调度后的操作是不确定的
- 调度器可确保历史记录中的操作顺序等效于某些串行调度。
- 调度器可能会延迟某些操作
- 有些事务可能被中止
1.6.3. 调度例10.1.1
- 账户A和B中各有50
- 从账户A转账30到50
- 状态:20 + 50 -> fail check
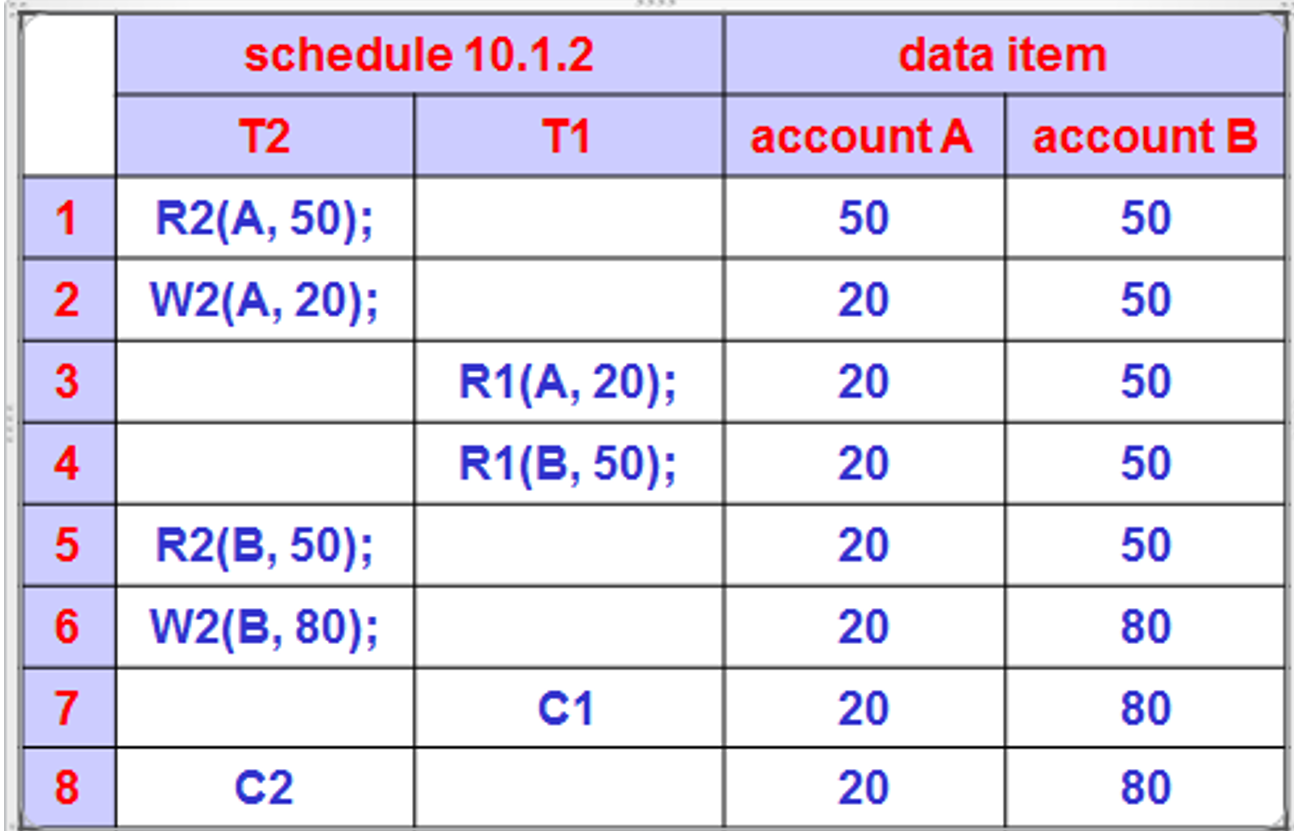
- 但是这种情况不会在串行调度中出现
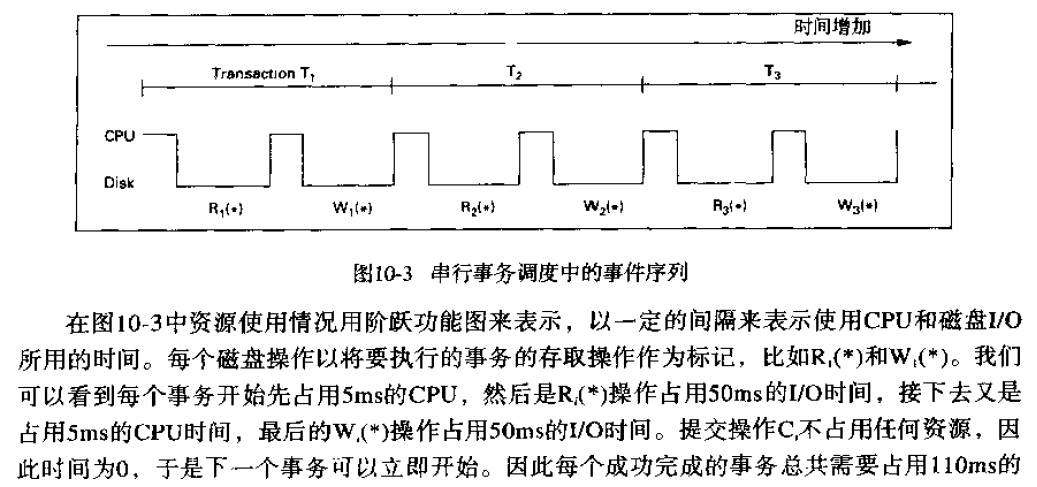
1.6.4. 如果序列历史始终保持一致,那么为什么不执行序列历史呢?
- 串行事务调度的情况

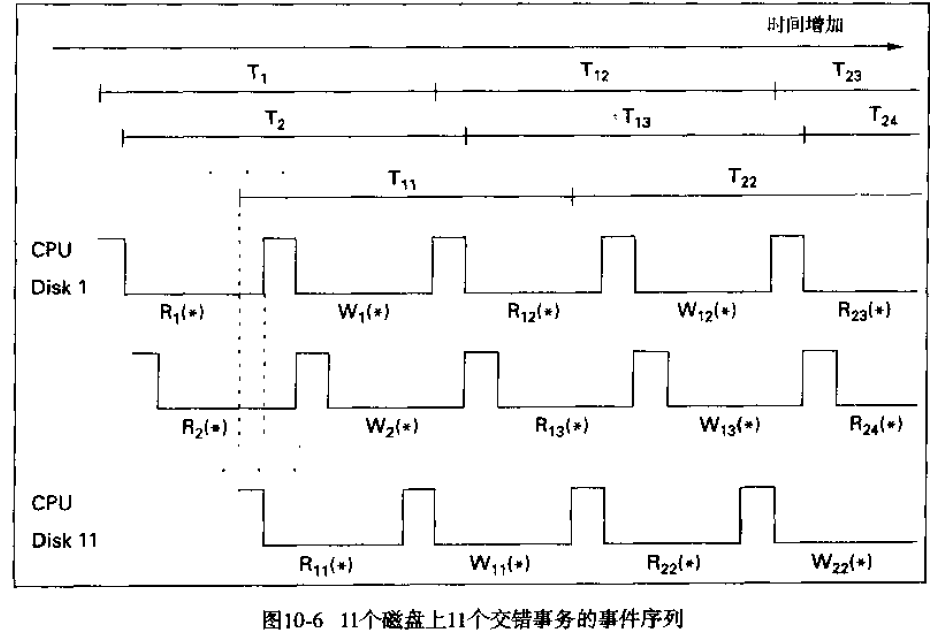
- 双事务的交叉执行:提高效率

- 更多事务的交叉执行:CPU的利用率逐渐提高
2. 可序列化性和优先级图
2.1. 可串行化调度
- 该系列操作与序列计划等效
- 调度器的工作:为调度程序找到一组规则,以允许通过交错事务进行操作并保证可串行性。
2.2. 可串行化理解
- 如果两个事务不访问同一个数据单元,那么
- 我们可以在调度程序允许的请求历史中对操作进行通勤,直到一个Tx的所有操作都在一起(串行历史)为止。
- 操作不会互相影响,顺序也无关紧要。
- 如果两个事务访问同一个数据单元,那么
- 如果…R1(A)…R2(A):则可并行化
- 如果…R1(A)…W3(A)…R2(A):则不可以并行化
2.3. 冲突操作
- 当且仅当以下三个条件成立时,历史中的两个运算Xi(A)和Yj(B)才发生冲突(即顺序重要):
- A就是B:对不同数据项的操作永远不会发生冲突。
- i不等于j:仅当操作由不同的事务执行时才会发生冲突。但是同一个事务操作中的顺序也是重要的。
- X操作和Y操作中一个为写入操作,另一个为是读出或写入操作(至少有一个是写入操作)
2.3.1. 三种冲突类型
- Ri(A) -> Wj(A):在一个事务中,写操作在读操作后(不可颠倒)
- Wi(A) -> Rj(A)
- Wi(A) -> Wj(A)
2.4. 经历H的解释
- 任意经历H的解释包括3部分
- 经历中关于事务的逻辑目的的描述,应该足以证明事务对数据写入的值和事务对统一数据对象读取的值有关系。
- 经历中读写操作的值要给出具体的说明。
- 一致性规则。具有隔离性的事务执行过程中必须保持的某种逻辑属性,这些事务具有第1点中所陈述的逻辑属性。
- 经历的例子(下面这个例子是不可并行化的)

2.5. 不可串行化的例子
- 查看课本P467-Pxxx
- 证明不可串行化只需要证明一个事务必须先于另一个事务,或另一个事务必须先于当前事务(一般是从R/W顺序下手,主要是W)
2.5.1. 简单例子

- S(H):等价经历
2.5.2. 脏写

2.5.3. 盲写

2.6. 前趋图
- 历史H的前趋图是由PG(H)表示的有向图。
- PG(H)的顶点对应于H中已提交的事务(未提交事务不影响)
- 每当在H中按顺序发生两个冲突的操作Xi和Yj时,PG(H)中就会存在一条Ti->Tj边。
- 因此,应将Ti -> Tj解释为意味着Ti必须在任何等效的串行历史记录S(H)中位于Tj之前。
- 不可串行的操作的图就是含有环状结构的图。
2.7. 可串行性定理
- 历史记录H具有等效的串行执行S(H),前提是优先级图PG(H)不包含回路。
- 证明
- 假定涉及m个事务,并将它们标记为T1,T2,…。 。 。, Tm值。
- 因为在没有回路的任何有向图中,总是有一个没有边进入的顶点,因此有一个顶点或事务Tk,没有边进入。 我们选择Tk为Ti(1)。
- 请注意,由于Ti(1)没有边沿进入,因此H中没有冲突,这迫使其他事务更早进行。
- 现在,从PG(H)中删除此顶点Ti(1),并保留所有留下的边缘。 调用没有电路的结果图形PG1(H)。
- 以这种方式继续,从PG1(H)中删除Ti(2)及其所有边缘,依此类推,从PG2(H)中选择Ti(3)。 。 PGm-1(H)中的Ti(m)。


3. 加锁保证可串行性
3.1. 封锁:Lock
- 使用封锁技术的前提:在一个事务访问数据库中的数据时,必须先获得被访问的数据对象上的封锁,以保证数据访问操作的正确性和一致性。
- 封锁的作用:
- 在一段时间内禁止其它事务在被封锁的数据对象上执行某些类型的操作(由封锁的类型决定)
- 同时也表明:持有该封锁的事务在被封锁的数据对象上将要执行什么类型的操作(由系统所采用的封锁协议来决定)
3.2. 封锁类型
- 排它锁(eXclusive lock,简称X锁),又称"写封锁",WL(Write Lock)
- 共享锁(Sharing lock,简称S锁),又称"读封锁",RL(Read Lock)
3.2.1. 排它锁(X锁)
- 特性:
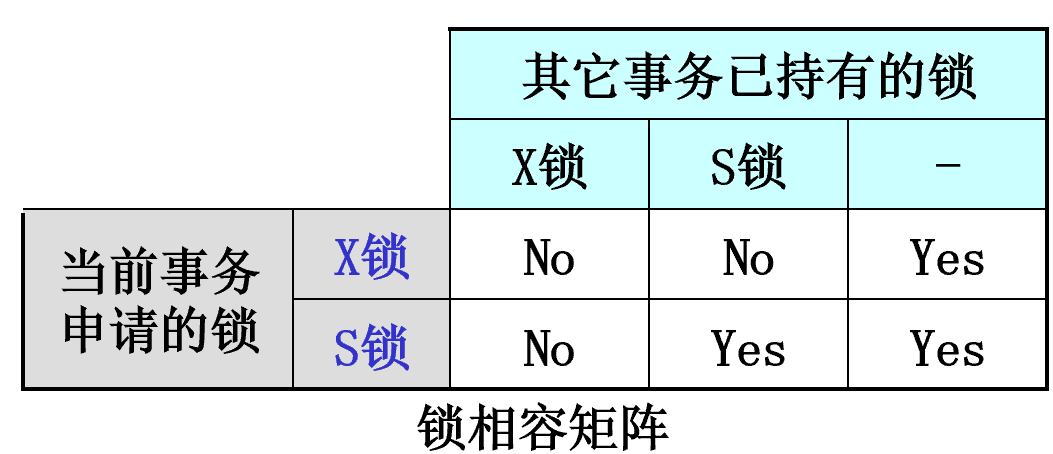
- 只有当数据对象A没有被其它事务封锁时,事务T才能在数据对象A上施加"X锁";
- 如果事务T对数据对象A施加了"X锁",则其它任何事务都不能在数据对象A上再施加任何类型的封锁。
- 作用
- 如果一个事务T申请在数据对象A上施加"X锁"并得到满足,则:事务T自身可以对数据对象A作读、写操作,而其它事务则被禁止访问数据对象A
- 这样可以让事务T独占该数据对象A,从而保证了事务T对数据对象A的访问操作的正确性和一致性
- 缺点:降低了整个系统的并行性
- "X锁"必须维持到事务T的执行结束
3.2.2. 共享锁(S锁)
- 特性:如果数据对象A没有被其它事务封锁,或者其它事务仅仅以"S锁"的方式来封锁数据对象A时,事务T才能在数据对象A上施加"S锁";
- 作用:
- 如果一个事务T申请在数据对象A上施加"S锁"并得到满足,则:事务T可以‘读’数据对象A,但不能"写"数据对象A
- 不同事务所申请的"S锁"可以共存于同一个数据对象A上,从而保证了多个事务可以同时"读"数据对象A,有利于提高整个系统的并发性
- 在持有封锁的事务释放数据对象A上的所有"S锁"之前,任何事务都不能"写"数据对象A
- "S锁"不必维持到事务T的执行结束(依封锁协议而定)
3.2.3. 锁相容矩阵
3.3. 合适事务
- 如果一个事务在访问数据库中的数据对象A之前按照要求申请对A的封锁,在操作结束后释放A上的封锁,这种事务被称为合适事务。
- "合适事务"是保证并发事务的正确执行的基本条件。
3.4. 二段锁协议(2PL)

- 在Ti可以读取数据项Ri(A)之前,调度程序会尝试代表其RLi(A)读取该项目。在Wi(A)之前,请尝试写锁定WLi(A)。
- 如果出现冲突锁,则事务Ti必须等待
- 锁冲突和操作冲突时同步的
- 如果数据项的两个锁是由不同的Ti尝试的,则它们将冲突,并且其中至少一个是WL。
- 封锁阶段
- 增长阶段
- 收缩阶段
- 当锁被释放:RUi(A)
- 调度程序必须确保不能收缩(删除锁)然后再次增长(获取新锁)。
- 这部分保证了在Commit前能释放所有的锁
- 通常在Commit上一次释放所有锁,我们将在随后的内容中对此进行假设。
3.5. 锁冲突
- 一个事务不可能和自己拥有的锁冲突
- 如果Ti在A上保持读锁(RL),只要没有其他Tx在A上锁定(必须是RL),就可以在A上获得WL。
- 一个有写锁(WL)的事务不需要读锁(RL),WL比RL更强
- 明确定义了锁定,以确保优先级图中的环路永远不会发生。
- 第一个锁定的事务Tx会强制到达的所有其他事务Tx在任何SG中"稍后出现"。
- 死锁
- 如果后到达的事务Tx已经持有了第一个到达需要的锁,这就会导致第一个到达的无法获取到锁,从而导致死锁
3.6. 锁和串行化的例子
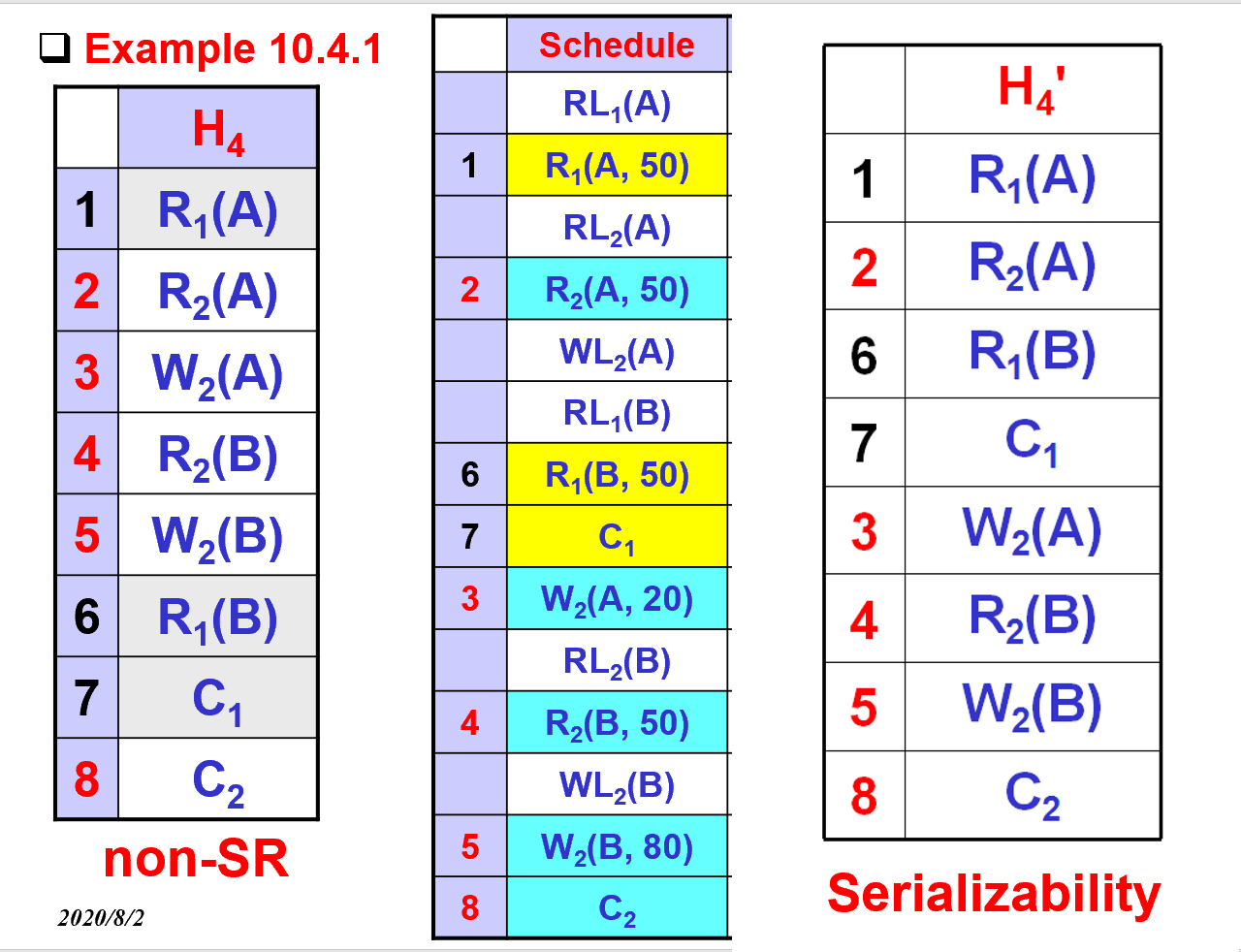

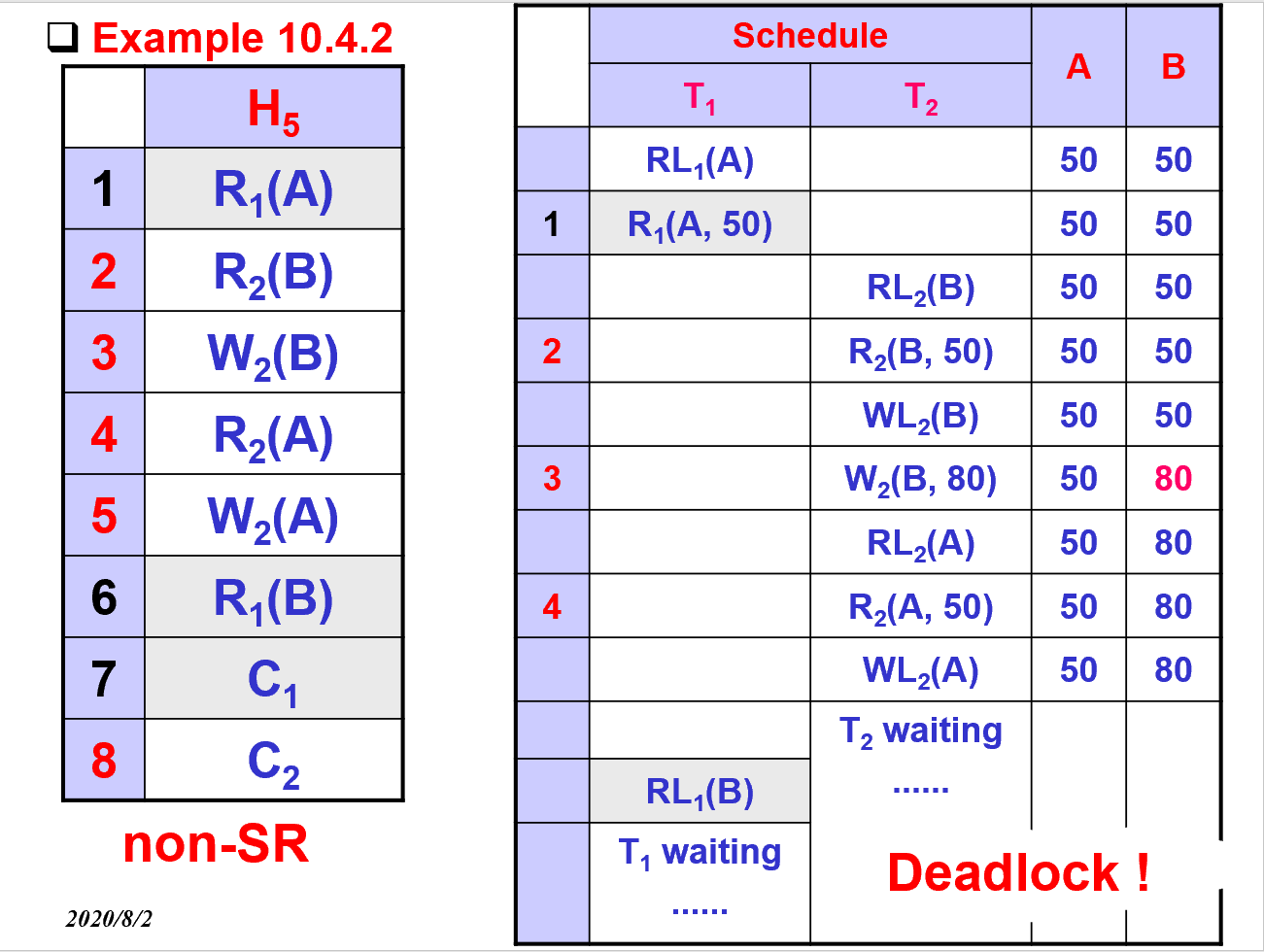
3.7. 加锁定理
- 遵循2PL准则的操作的经历就是SR(可串行化)。



4. 隔离级别
- 每一个事务都可以自主选择,它自己与其它并发事务之间的隔离级别。
- 一个事务所选择的隔离级别,决定了它在运行过程中(调度器)所采用的封锁策略。
4.1. 四种隔离级别
1 | |
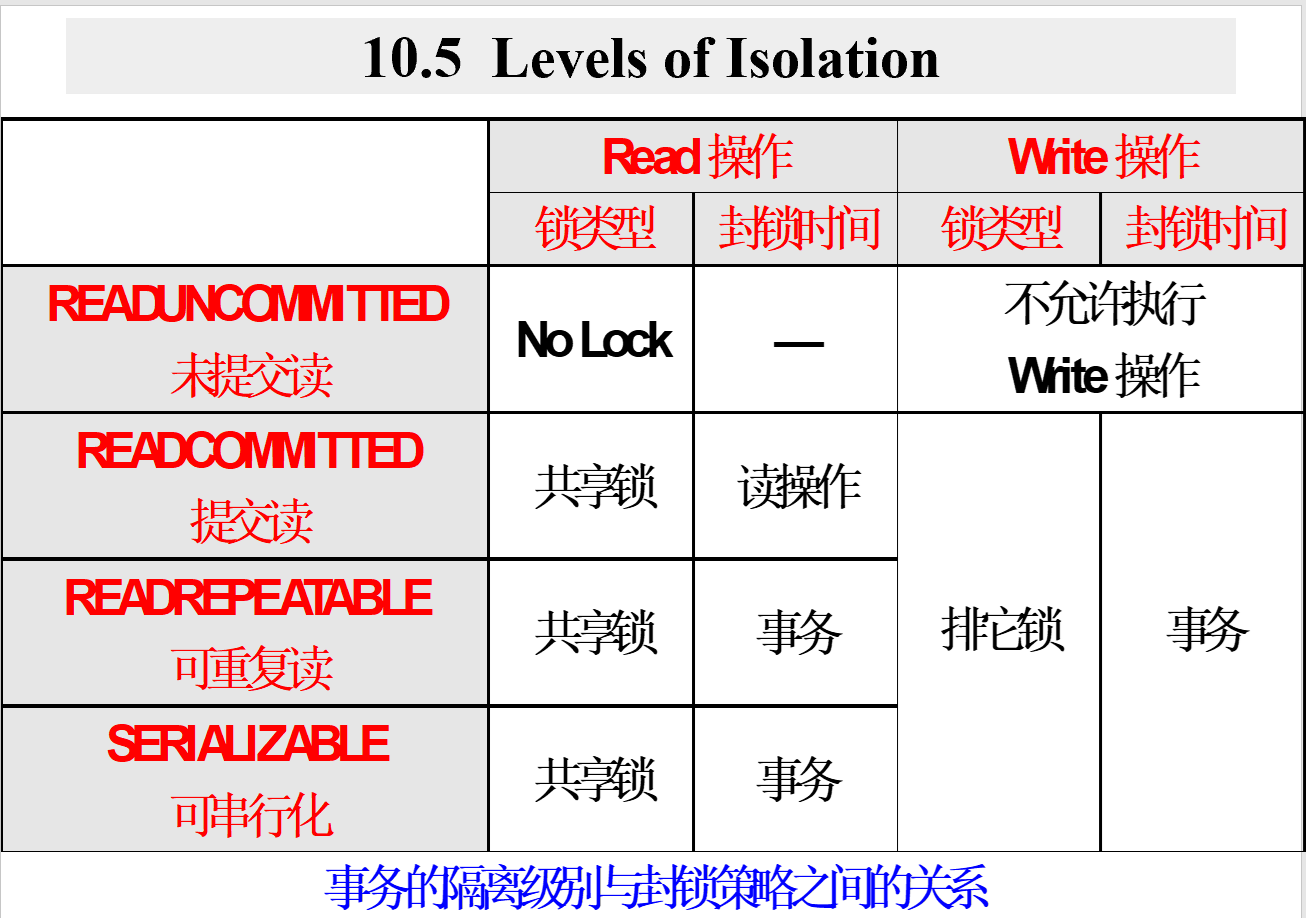
4.1.1. READUNCOMMITTED:未提交读
- 在该方式下,当前事务不需要申请任何类型的封锁,因而可能会"读"到未提交的修改结果
- 禁止一个事务以该方式去执行对数据的"写"操作,以避免"写"冲突现象。
4.1.2. READCOMMITTED:提交读
- 在"读"数据对象A之前需要先申请对数据对象A的"共享性"封锁,在"读"操作执行结束之后立即释放该封锁。
- 以避免读取未提交的修改结果。
4.1.3. READREPEATABLE:可重复读
- 在"读"数据对象A之前需要先申请对数据对象A的"共享性"封锁,并将该封锁维持到当前事务的结束。
- 可以避免其它的并发事务对当前事务正在使用的数据对象的修改。
4.1.4. SERIALIZABLE:可序列化(可串行化)
- 并发事务以一种可串行化的调度策略实现其并发执行,以避免它们相互之间的干扰现象。
4.1.5. 通用备注
- 不管采用何种隔离级别,在事务"写"数据对象A之前需要先申请对数据对象 A 的"排它性"封锁(write-lock),并将该封锁维持到当前事务的结束。
4.1.6. 不同隔离级别在不同操作申请的锁和封锁时间
4.2. 封锁时间
- 短期封锁:在操作(R或W)之前已取得锁定,并在随后立即释放。
- 长期封锁:锁会持续到事务结束(EOT, End Of Trans)
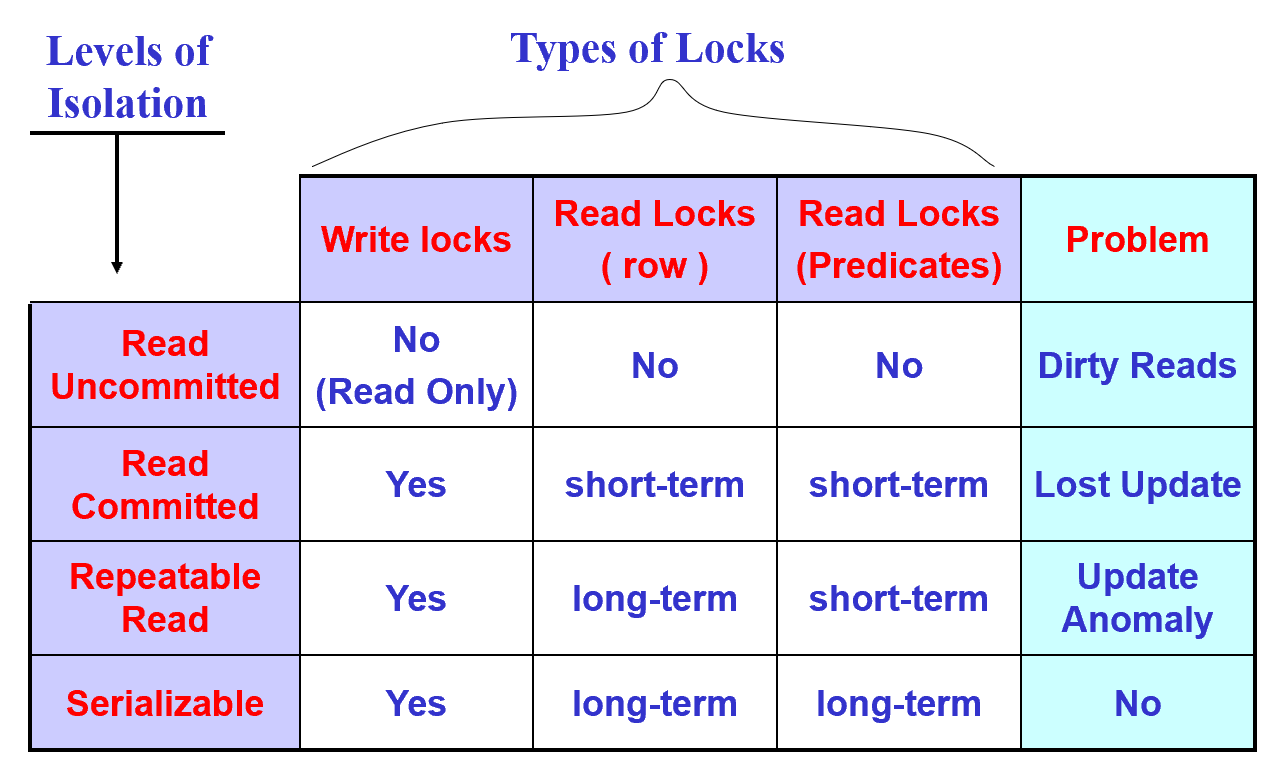
- Predicates:谓词上的读锁和写锁,约束,比如city=xxx
- row:记录上的读锁和写锁
5. 事务恢复机制
- 日志:日志条目包含事务进行的每个更新的"镜像前"和"镜像后"。
- 使用日志的优点:日志可以保证系统能够将数据库恢复到系统在崩溃这一刻应该具有的状态
5.1. 事务恢复类别
5.1.1. 镜像前
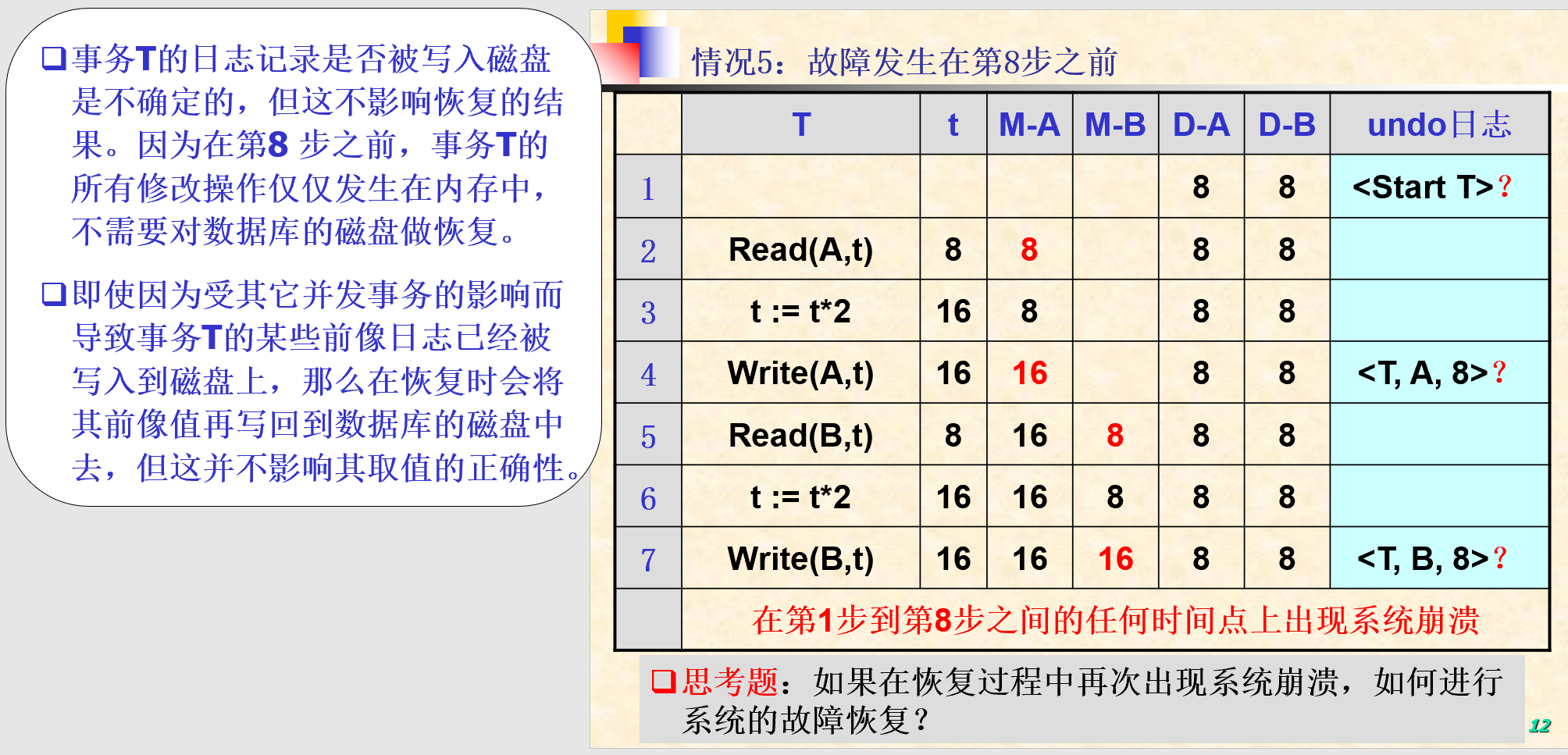
- 在恢复中,我们可以通过应用"镜像前"来备份不应该写入磁盘(事务未提交)的更新。
5.1.2. 镜像后
- 在恢复中,我们可以应用"镜像后"来纠正应该已经进入磁盘(事务确实已提交)但从未成功进入磁盘页面。
5.2. 不同日志类型
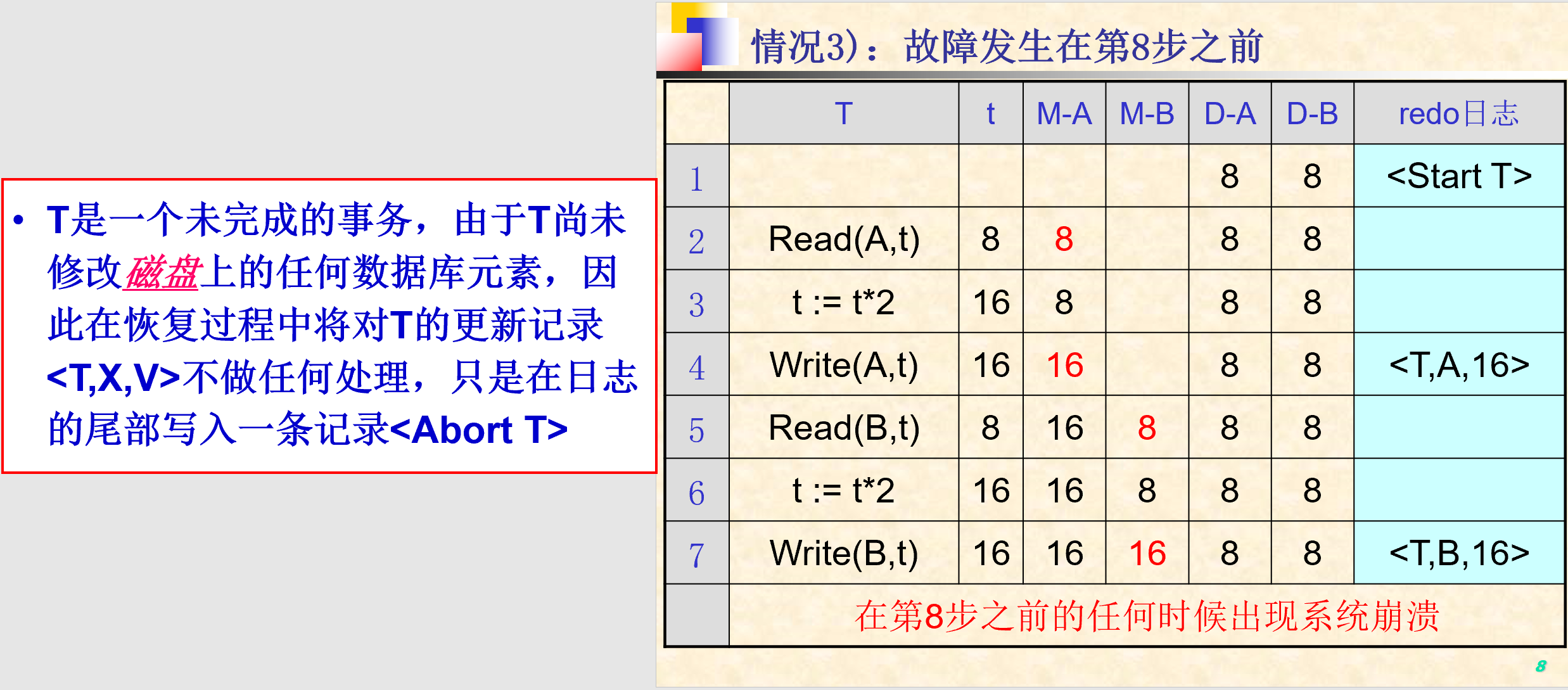
5.2.1. UNDO 日志
- 只有镜像前
- 恢复没有提交的事务
- UNDO日志记录格式:
- 开始事务:
<Start T> - 提交事务:
<Commit T> - 放弃事务:
<Abort T> - 更新记录:
<T, X, V>:事务T修改了数据库元素X的值,而X原来的旧值是V
- 开始事务:
- 记载规则:
- U1:如果事务T修改数据库元素X,则更新日志
<T, X, V>必须在X的新值写到磁盘前写到磁盘 - U2:如果事务T提交,则日志记录
<Commit T>必须在事务T改变的所有DB元素已写到磁盘后再写到磁盘。
- U1:如果事务T修改数据库元素X,则更新日志
- 其他操作:
- Flush log:将内存中的日志记录全部写入磁盘
- Output(A):将数据对象A的值写入到磁盘
- 其他值符号:
- D-A:数据库元素A在计算机磁盘中的值
- M-A:数据库元素A在内存缓冲中的值
- t:内存变量

- 恢复过程:
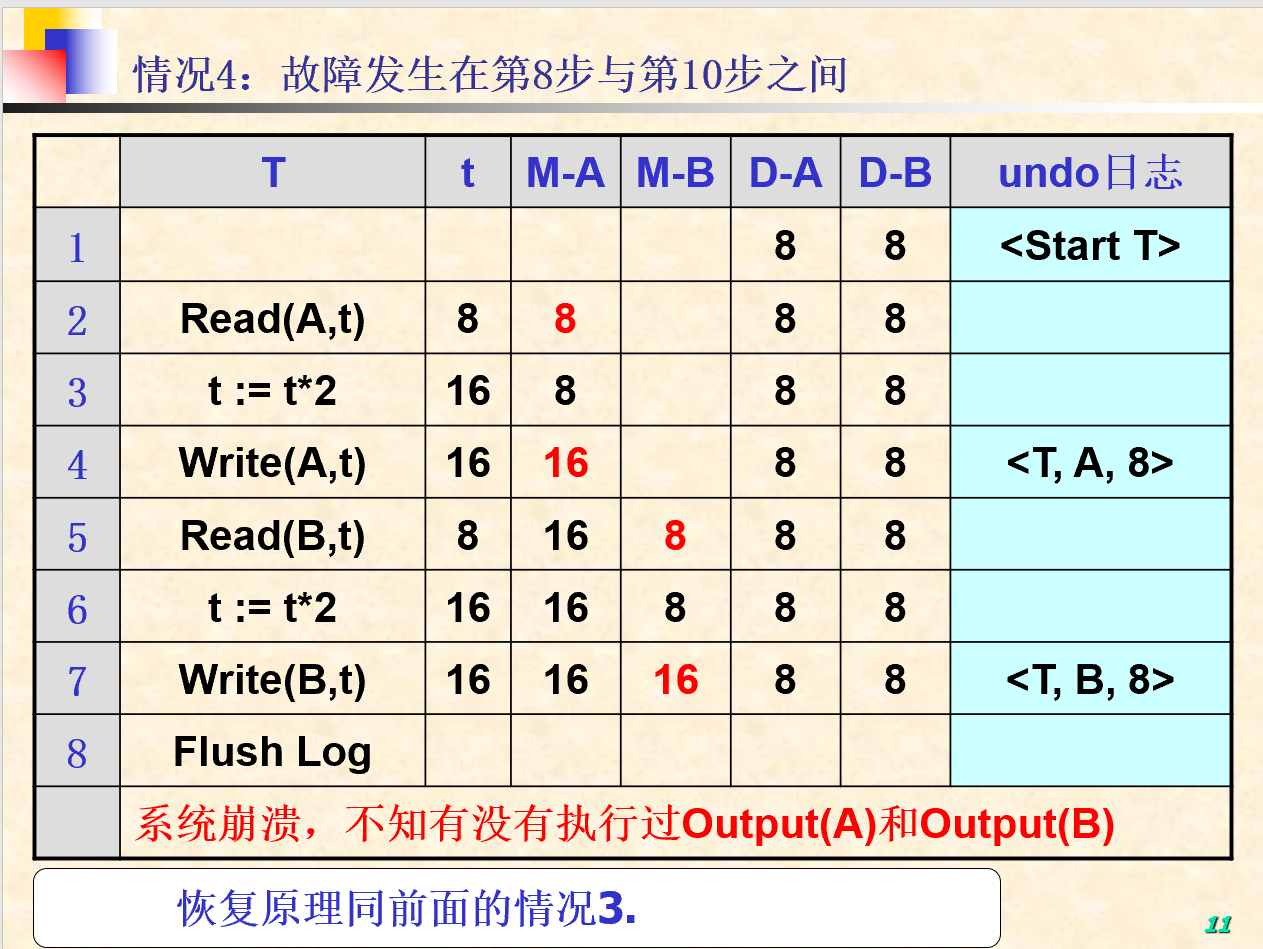
- 划分事务为已提交事务和未提交事务两类
- 从undo日志尾部开始向头部扫描日志,对每一个更新记录
<T, X, V>进行如下处理- T为已提交事务(已经扫描到Commit):继续扫描下一条日志记录(规则U2)
- T为未提交事务:由恢复管理器将数据库中的X的值改为V(规则U1)
- 日志尾部为每一个未结束事务写入一个日志记录
<Abort T>,并刷新日志:Flush Log
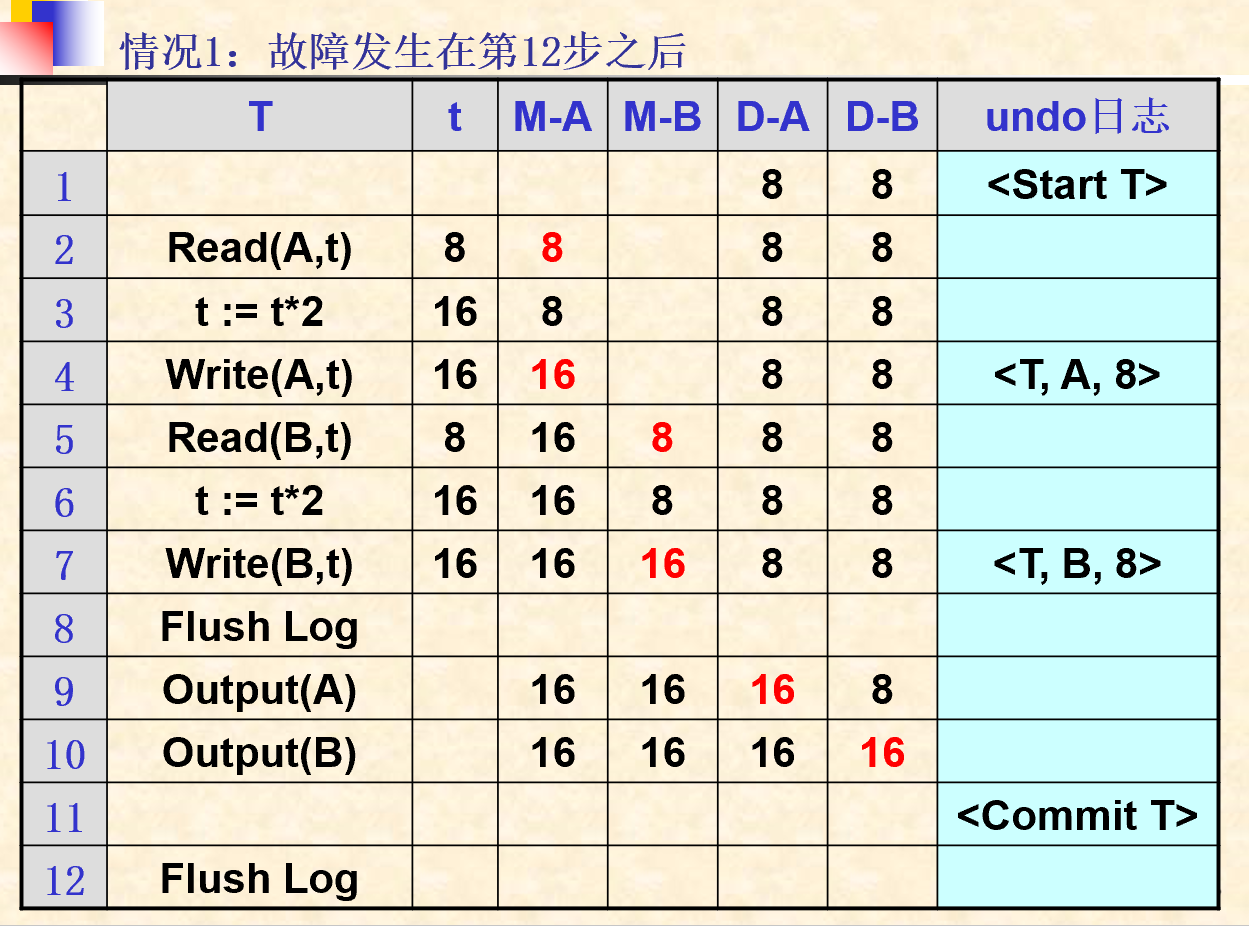
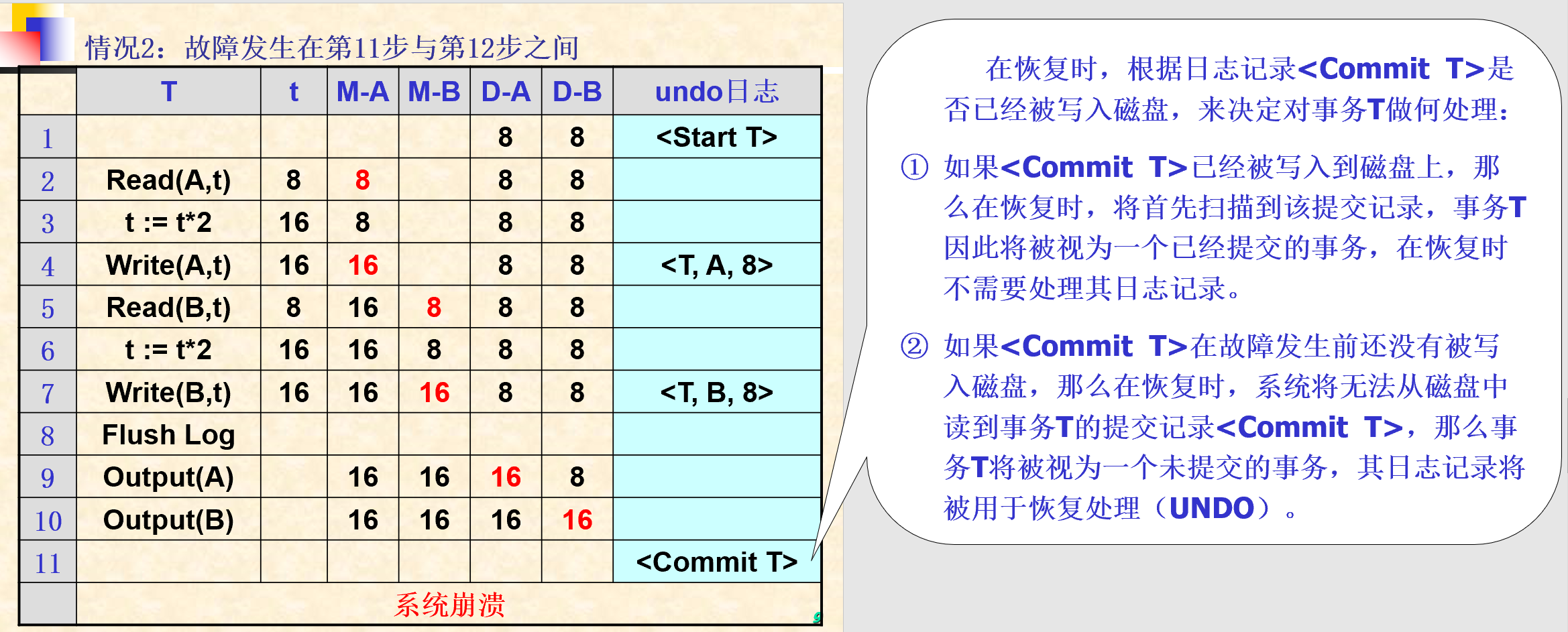
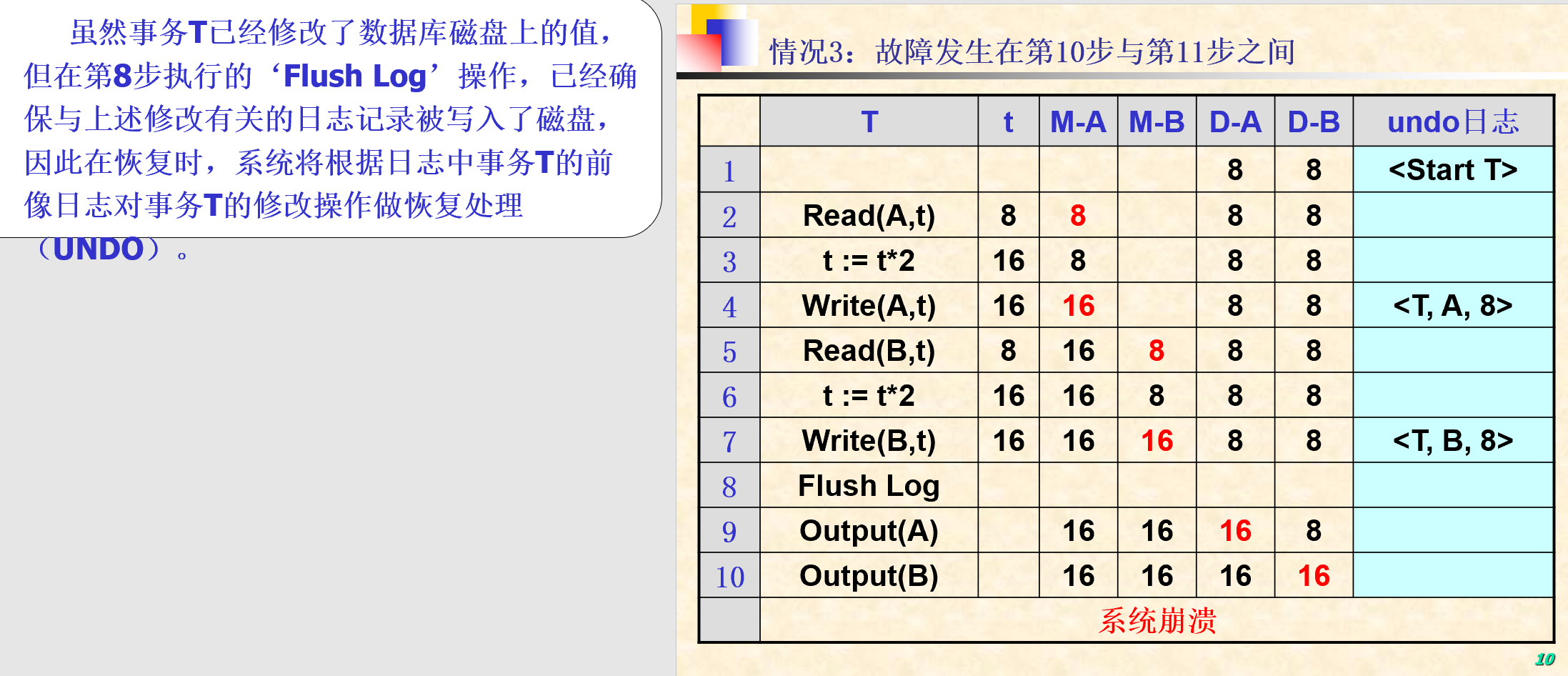
- 不足:
- 在将事务改变的所有数据写到磁盘前不能提交该事务;
- 在事务的提交过程中需要执行许多‘写’磁盘操作,从而增加了事务提交的时间开销。
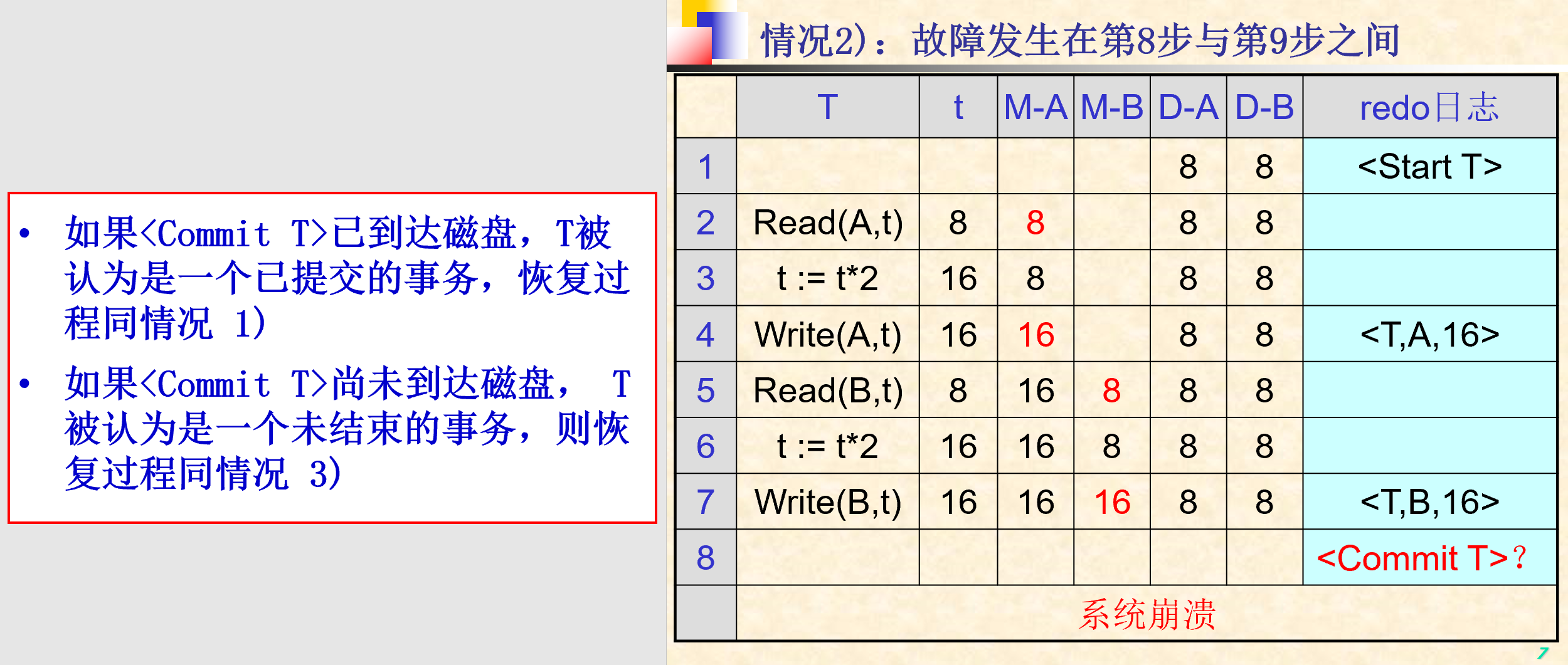
5.2.2. REDO日志
- 之后镜像后
- 恢复已经提交的事务
- REDO日志记录格式:
- 开始事务:
<Start T> - 提交事务:
<Commit T> - 放弃事务:
<Abort T> - 更新记录:
<T, X, V>:事务T修改了数据库元素X的值,而X的新值是V
- 开始事务:
- 记载规则
- R1:在修改磁盘上的任何数据库元素X之前,要保证所有与 X 的这一修改有关的日志记录 (包括更新记录
<T,X,V>和提交记录<Commit T>) 都必须出现在磁盘上。
- R1:在修改磁盘上的任何数据库元素X之前,要保证所有与 X 的这一修改有关的日志记录 (包括更新记录
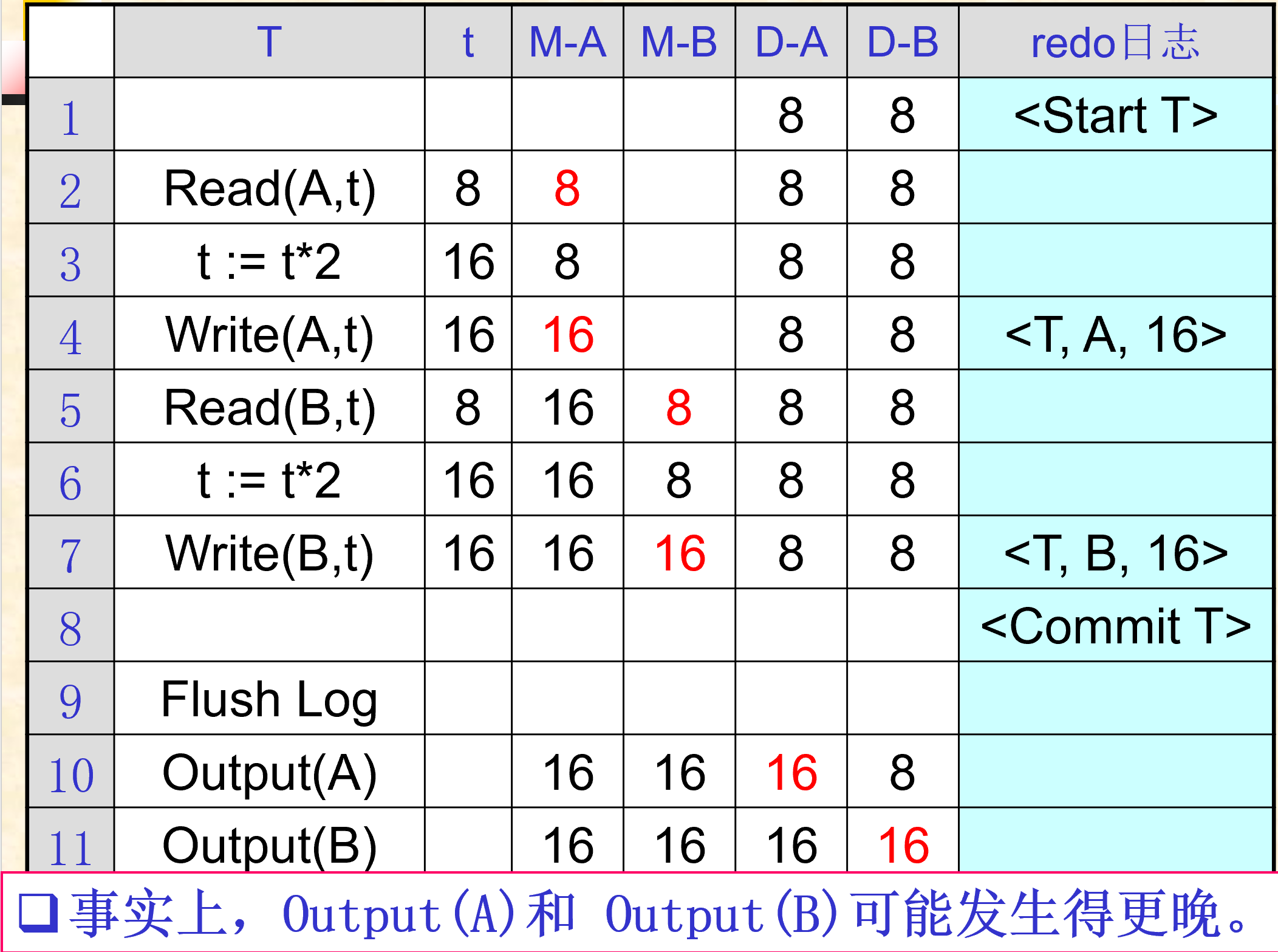
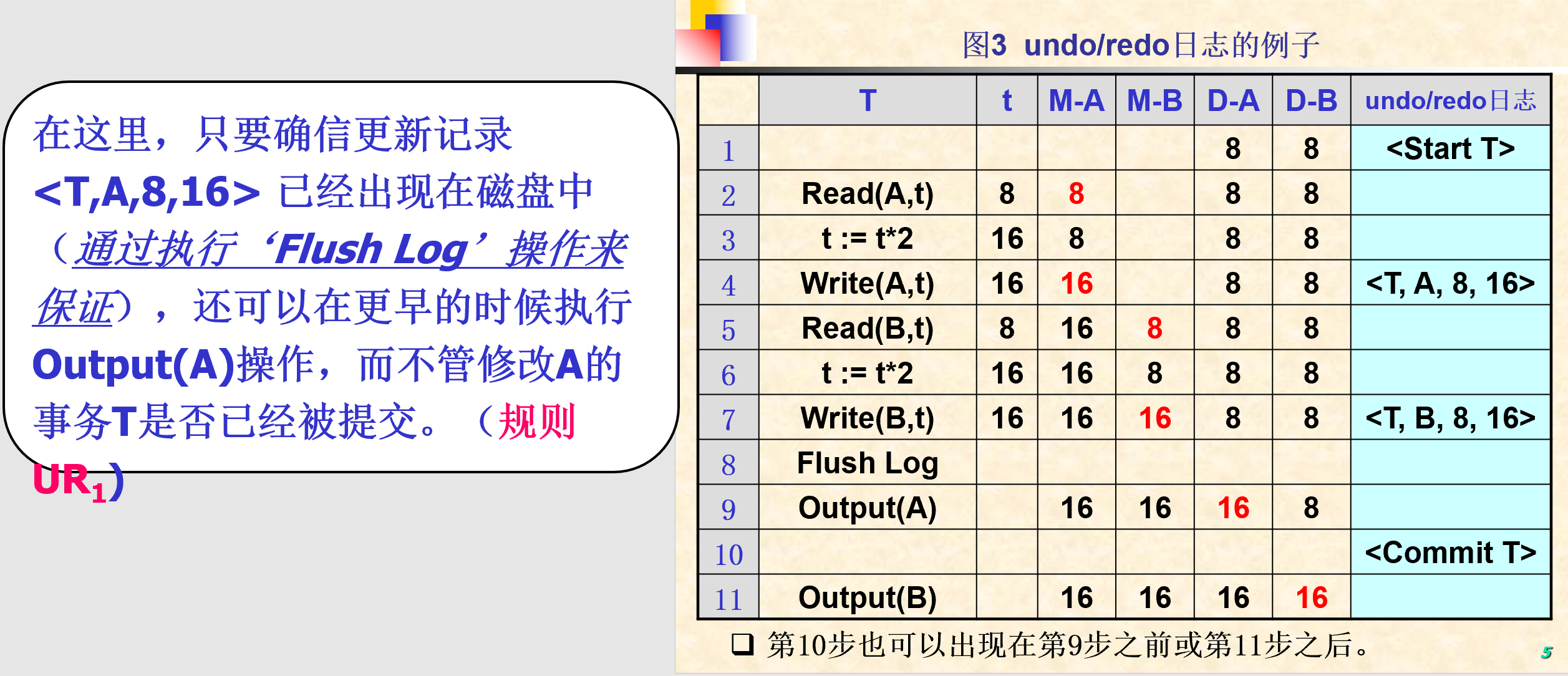
- 执行‘Flash Log’操作的目的是为了确保与事务T有关的日志记录(包括后像日志和提交日志)能够及时被写入磁盘,一方面是保证事务T的真正提交,另一方面也为今后的Output操作提供保证(规则R1)
- 恢复过程
- 确定所有已提交的事务
- 从日志文件的首部开始扫描日志,对于遇到的每一条更新记录
<T, X, V>- 如果T是未提交的事务,则继续扫描
- 如果T是已提交的事务,则为数据库元素X写入新值V
- 对每个未完成的事务T,在日志的尾部写入结束标志
<Abort T>并刷新日志
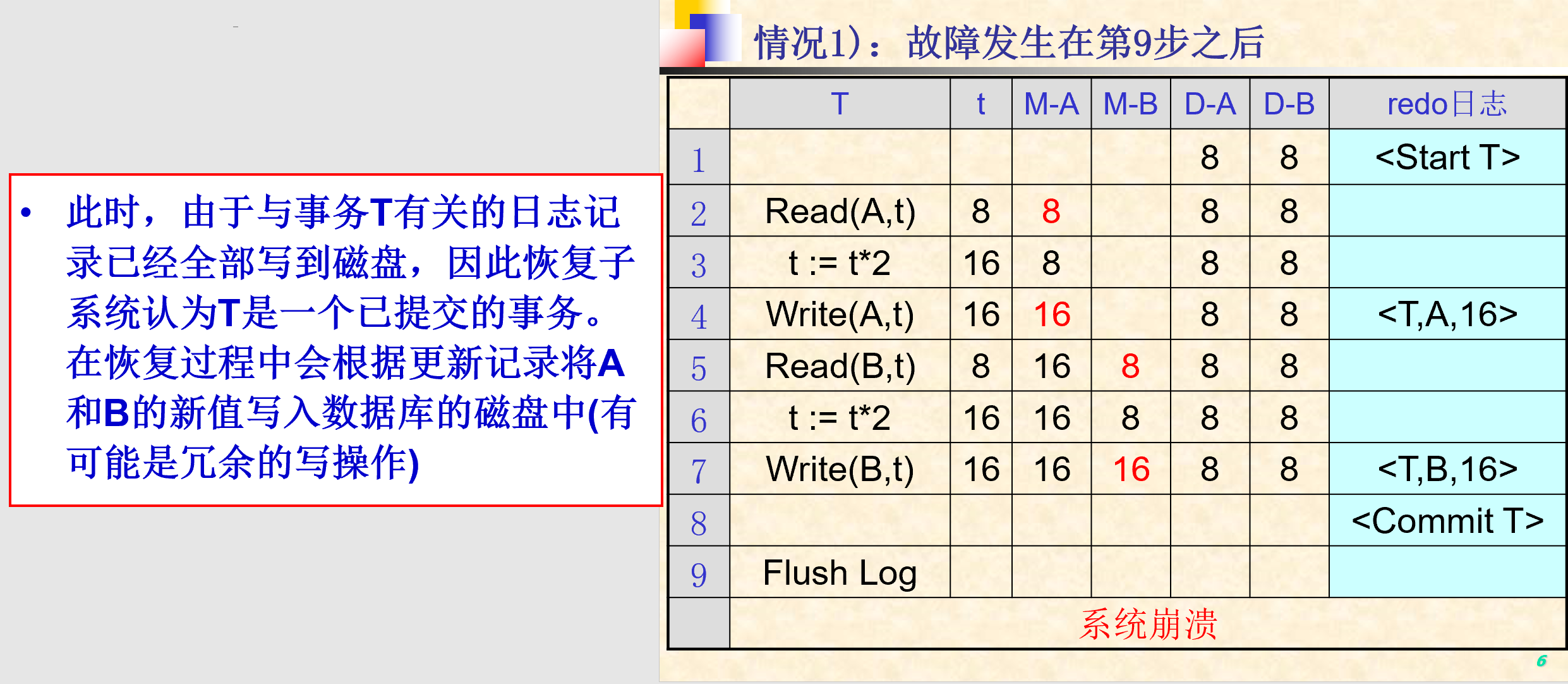
- 和UNDO日志主要区别
- 恢复目的不一样
- 提交记录
<Commit T>写入日志的时间不一样- undo日志:在事务T的所有数据库磁盘修改操作(Output)结束后才能在日志中写入提交记录
<Commit T> - redo日志:在提交记录
<Commit T>被写入日志文件的磁盘后才能将事务T更新后的值写入数据库的磁盘中
- undo日志:在事务T的所有数据库磁盘修改操作(Output)结束后才能在日志中写入提交记录
- 在更新记录
<T,X,V>中保存的值V不一样
5.2.3. UNDO/REDO日志
- 镜像前和镜像后
- 恢复全部事务
- UNDO 和 REDO 日志的不足:
- Undo 日志要求数据在事务结束后立即写到磁盘,可能增加需要执行磁盘I/O的次数;
- Redo 日志要求事务提交和日志记录刷新之前将所有修改过的数据保留在内存缓冲区中,可能增加事务需要的平均缓冲区的数量;
- 如果被访问的数据对象X不是完整的磁盘块,那么在undo日志与redo日志之间可能产生相互矛盾的请求。
- UNDO/REDO日志记录的格式
- 开始事务:
<Start T> - 提交事务:
<Commit T> - 放弃事务:
<Abort T> - 更新记录:
<T, X, v, w>:事务T修改了数据库元素X的值,而X原来的值是v(before image),更新后的值是w(after image)
- 开始事务:
- 记载规则:
- UR1:在由于某个事务T所做的改变而修改磁盘上的数据库元素X之前,更新记录
<T,X,v,w>必须出现在磁盘上。 - UR2:在每一条
<Commit T>后必须紧跟一条Flush Log操作,为了确保已经在日志中写入<Commit T>记录的事务T确实被提交,为 undo/redo日志新增加了一条记载规则
- UR1:在由于某个事务T所做的改变而修改磁盘上的数据库元素X之前,更新记录
- 故障恢复过程
- 根据
<Commit T>是否已经出现在磁盘中来决定事务T是否已经被提交,然后:- 先按照从后往前的顺序,撤消(undo)所有未提交的事务
- 再按照从前往后的顺序,重做(redo)所有已提交的事务
- 根据
5.3. 例子
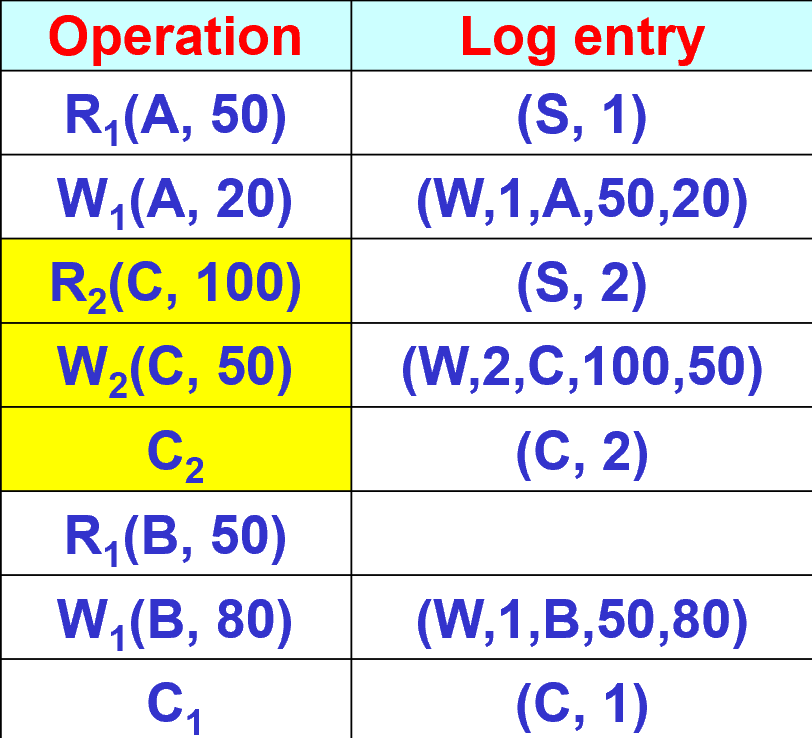
- (S, 1)和(S, 2)都是用来记录日志开始的。
- 读操作不写日志
- 写操作需要记录日志
- BI(Before Image) 和 AI(After Image)
- (C, 2)和(C, 1)是用来记录日志退出的。
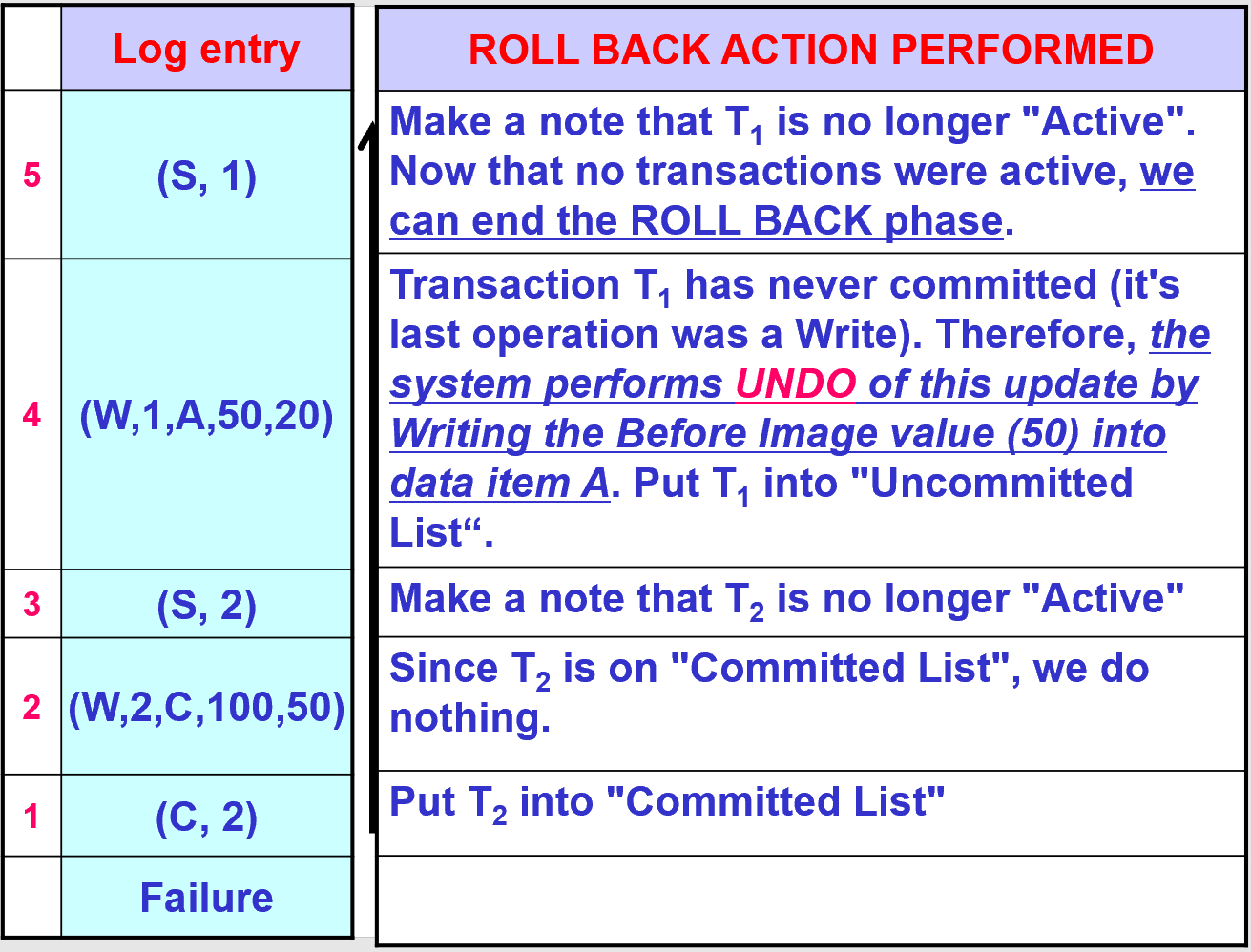
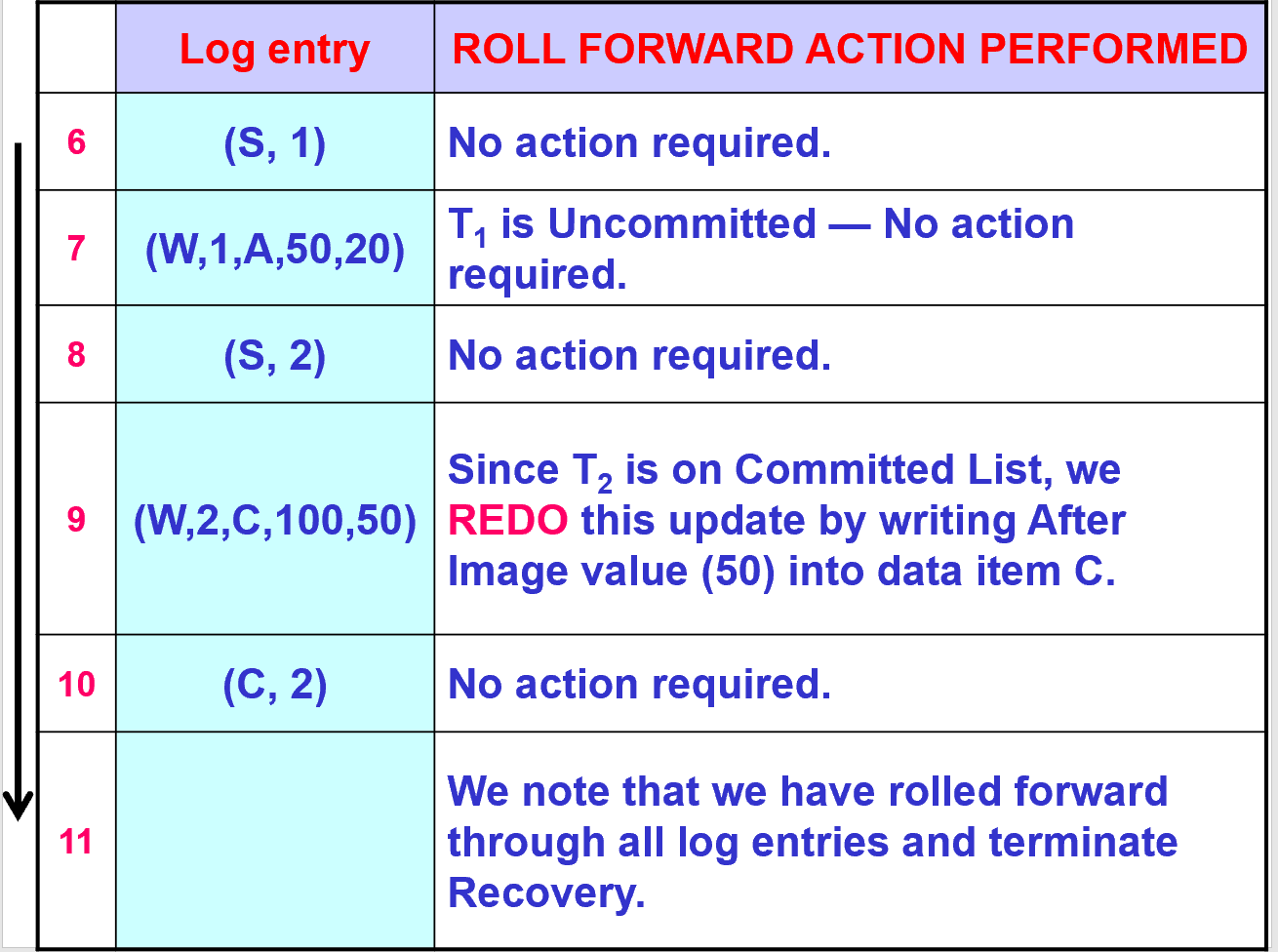
5.4. 检查点
5.4.1. 提交一致性检查点
- 在一致性检查点完成前没有新的事务可以开始
- 数据库操作将继续直到所有当前事务提交,并且他们的log文件写入磁盘
- 当前的日志缓冲区被写出到日志文件中,然后,系统将确保缓冲区中的所有脏页都已写出到磁盘上。
- 执行了步骤1-3后,系统会将特殊日志条目(CKPT)写入磁盘,并且检查点已完成。
5.4.2. 高速缓存一致性检查点
- 没有新的事务允许开始
- 当前所有事务禁止进行任何操作
- 当前的日志缓冲区被写到磁盘上,然后,系统将确保缓存缓冲区中的所有脏页都被写到磁盘上。
- 最后,一个特殊的日志条目(CKPT,列表)被写到磁盘上,并且我们说检查点已经完成。 此日志条目中的列表包含采用检查点时的活动事务列表。
5.4.3. 模糊检查点
- 在启动检查点之前,将先前检查点之前的所有脏页面强制驱出到磁盘上(但是写入速率应保留I/O容量以支持当前正在进行的事务;这样做没有紧要的时间)。
- 在检查点过程开始时,不允许新事务开始。 现有事务无法启动任何新操作。
- 当前日志缓冲区将通过附加的日志条目(CKPTN,列表)写出到磁盘,如高速缓存一致性检查点过程中所述。
- 自上次检查点日志CKPTN-1以来,缓冲区中的页面集已弄脏。这可能是通过缓冲区目录上的特殊标志来完成的。不需要将此信息放置在磁盘上,因为它仅用于执行下一个检查点,而在恢复的情况下不会使用。检查点现已完成。
5.5. UNDO日志中插入检查点的处理过程
- 系统停止接受"启动新事务的请求";
- 等到所有当前活跃的事务被提交或中止,并且在日志中写入了
<Commit T>或<Abort T>记录; - 将日志记录刷新到磁盘;
- 写入日志记录
<CKPT>,并再次刷新日志; - 重新开始接受新的事务。
5.6. UNDO日志中的检查点
- 在进行故障恢复时,只要逆向扫描到第一条
<CKPT>记录(最后一个被记入日志的检查点)就可以结束故障恢复工作。

5.6.1. UNDO日志中插入非静止检查点设置步骤
- 写入日志记录
<Start CKPT(T1,…,Tk)>,并刷新日志;- T1,…,Tk是当前所有活跃事务的标识符
- 等待T1,…,Tk中的每一个事务的提交或中止,但允许开始执行其它新的事务;
- 当T1,…,Tk都已经完成时,写入日志记录
<End CKPT>并刷新日志。
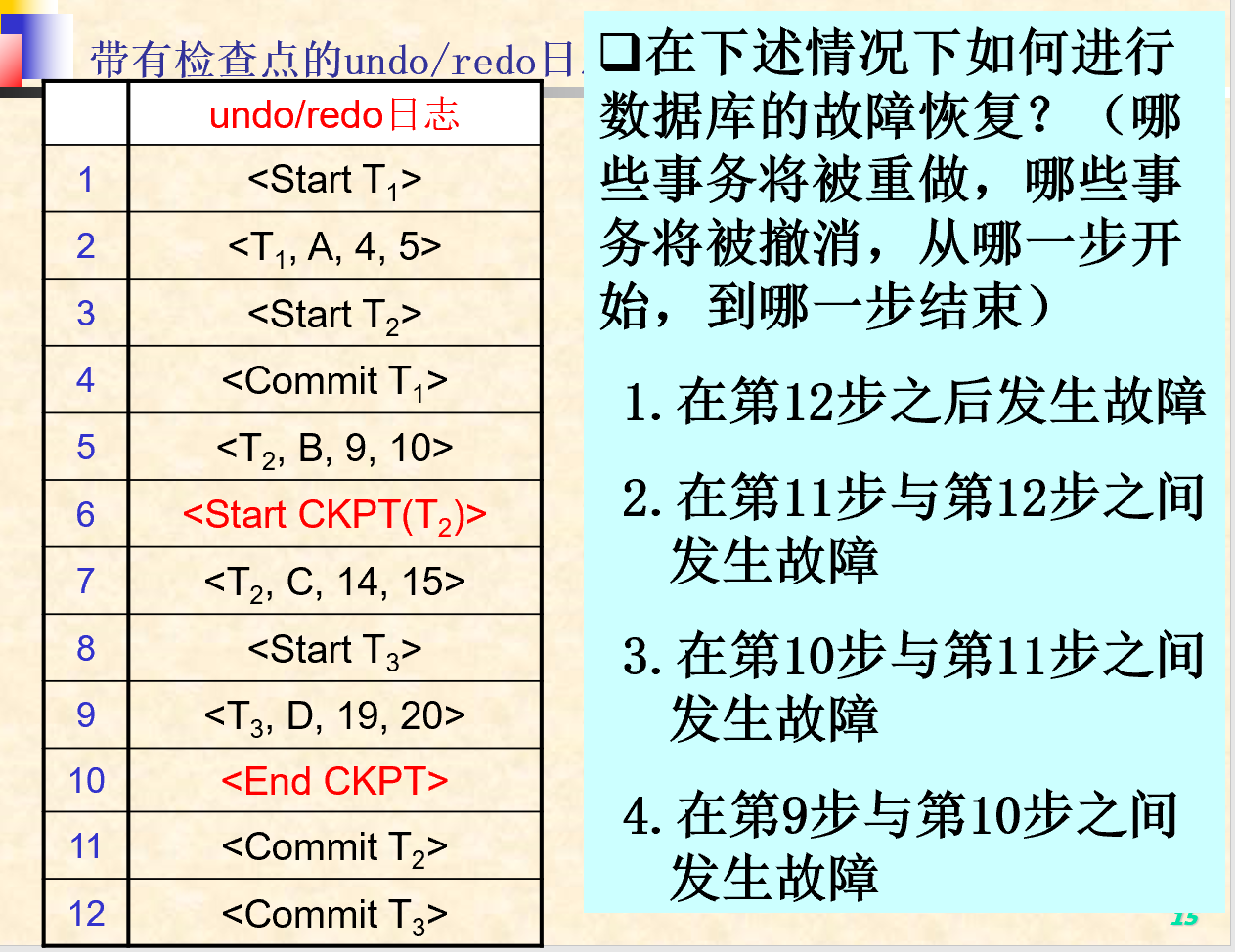
5.6.2. 非静止检查点的例子

5.6.3. 非静止检查点日志的恢复
- 从日志尾部向后扫描日志文件进行故障恢复。
- 如果先遇到
<End CKPT>记录,则继续向后扫描,直到出现对应的<Start CKPT(…)>记录就可以结束故障恢复工作,在这之后的日志记录是没有用处的,可以被抛弃。 - 如果先遇到
<Start CKPT(T1,…,Tk)>记录,此种情况下的故障恢复工作需要撤消两类事务的操作:- 在
<Start CKPT(T1,…,Tk)>记录之后启动的事务- 在扫描到
<Start CKPT(T1,…,Tk)>记录时,这类事务的操作已经被撤消。
- 在扫描到
- T1,…,Tk中在系统崩溃前尚未完成的事务
- 继续向后扫描日志,直至其中未完成事务的访问操作被全部撤消。
- 在
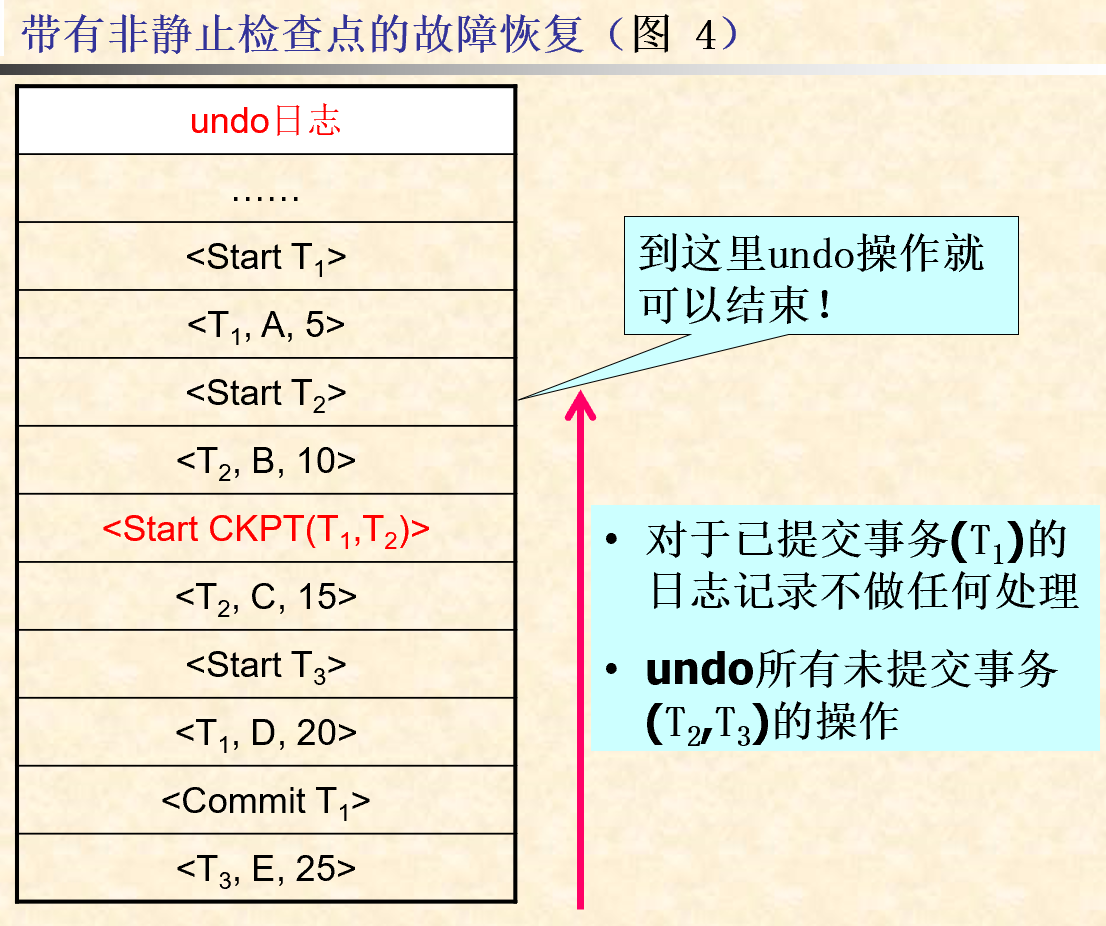
5.7. REDO日志的检查点
- 在redo日志中插入检查点时,由于已提交事务所做的修改被写入数据库磁盘的时间可能比事务提交的时间要晚得多,因此在插入检查点时,不仅仅需要考虑当前有哪些事务是活跃的,还要确保当前已提交事务的所有修改被写入到数据库的磁盘中去。
- 为了做到这一点,系统必须知道:
- 有哪些内存缓冲区被修改过,但还没有将修改结果写入磁盘?
- 每一个内存缓冲区都被哪些事务修改过?每个事务修改后的结果是什么?
5.7.1. 在REDO日志中插入(非静止)检查点的步骤
- 写入日志记录
<Start CKPT(T1,…,Tk)>,并刷新日志;- 其中:T1,…,Tk是当前所有活跃事务的标识符
- 同时获得当时所有已提交事务的标识符集合S
- 将集合S中的事务已经写到内存缓冲区但还没有写到数据库磁盘的数据写入磁盘;
- 写入日志记录
<End CKPT>并刷新日志。 - 不必等待事务T1,…,Tk或新开始事务的结束
- 写入日志记录

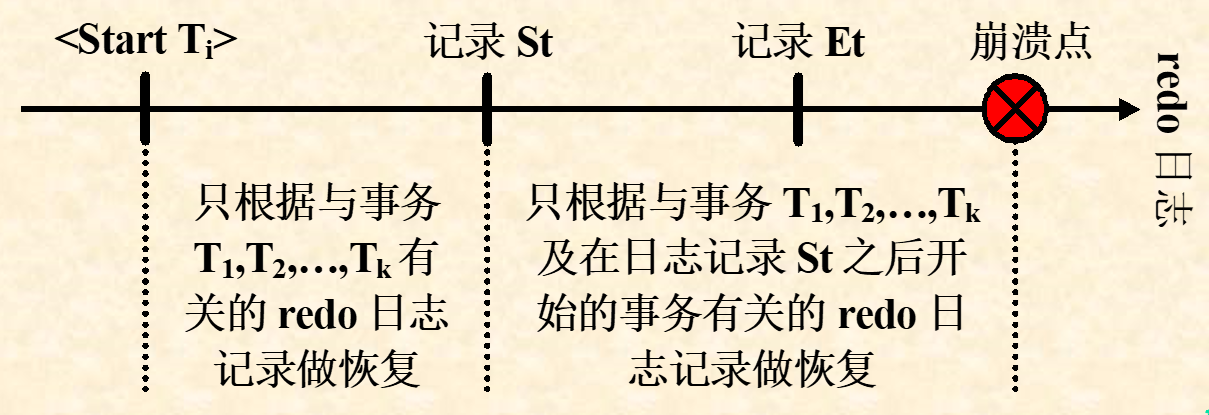
5.7.2. 带有检查点的REDO日志的恢复
-
寻找最后一个被记入日志的检查点记录:
- 如果是
<End CKPT>(记为记录Et),假设与之相对应的检查点记录是<Start CKPT(T1,…,Tk)>(记为记录St),并找到最早出现的<Start Ti>(记为记录ti),则故障恢复方法如下:针对事务T1,…,Tk以及在St之后开始的那些事务,重做其中已经被提交的事务 - 如果是
<Start CKPT(T1,…,Tk)>(记为记录St1),我们继续寻找前一个<End CKPT>(记为记录Et2),以及与Et2相对应的(记为记录St2); - 该情况就如同日志记录Et2是日志文件中的最后一条检查点(
<End CKPT>)记录一样进行恢复。
- 如果是
-
例子:


5.8. 在UNDO/REDO日志中插入检查点
- 写入日志记录
<Start CKPT(T1,…,Tk)>,并刷新日志。其中:T1,…,Tk是当前所有活跃事务的标识符; - 将所有被修改过的缓冲区写到数据库的磁盘中去;
- 写入日志记录
<End CKPT>并刷新日志。
2020-数据管理基础-ch10-更新事务
https://spricoder.github.io/2020/07/03/2020-Fundamentals-of-Data-Management/2020-Fundamentals-of-Data-Management-ch10-%E6%9B%B4%E6%96%B0%E4%BA%8B%E5%8A%A1/