2020-数据管理基础-ch08-数据库索引
ch08-数据库索引
1. 索引
1.1. 什么是索引
- 索引就像图书馆中的卡片目录。
- 每个卡(条目)具有:(键值,行指针)
- 键值用于查找
- 行指针(ROWID)足以在磁盘上定位行(一个I/O)
- 条目通常按"B树"中的查找键按字母顺序排列,也可能会被散列。
- 索引非常类似于内存驻留结构。
- 但是索引是磁盘驻留的。就像数据本身一样,通常一次也无法全部放入内存中。
- 索引可以被认为是一个有两列的表:键值和行指针
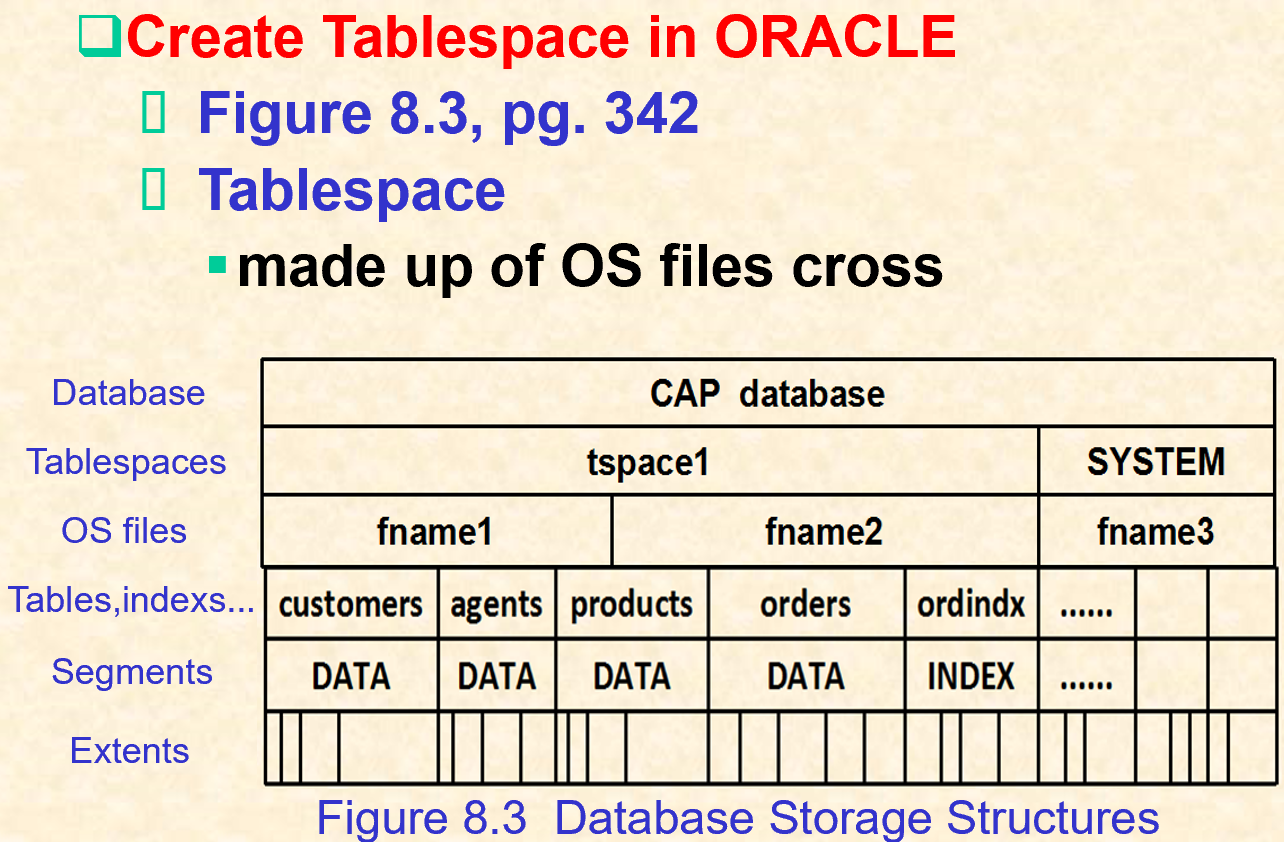
1.2. 索引创建
1 | |
- 键值和列必须是一对一关系
- 我们可以使用UNIQUE INDEX在Create Table Statement中实现UNIQUE约束。
- UNIQUE索引的例子

- cidx索引中的每个索引键值仅对应于一个客户行。
- 索引键与主键或候选键的关系概念完全不同。
- 但是,我们可以使用UNIQUE INDEX和NOT NULL来实现主键或候选键。
1.3. 使用索引
- 在索引被创建后,索引被排序并且存储在磁盘中
- 排序是按列值asc或desc进行的,如Select语句的SORT BY描述中所述。
- 索引建立之后,表的修改会直接反应在索引中,而并不需要重新建立索引
1.4. 索引删除
1 | |
2. 磁盘存储
2.1. 存储分类
- 计算机内存:快,但是易失的存储
- 磁盘存储:非常慢,非易失,低价
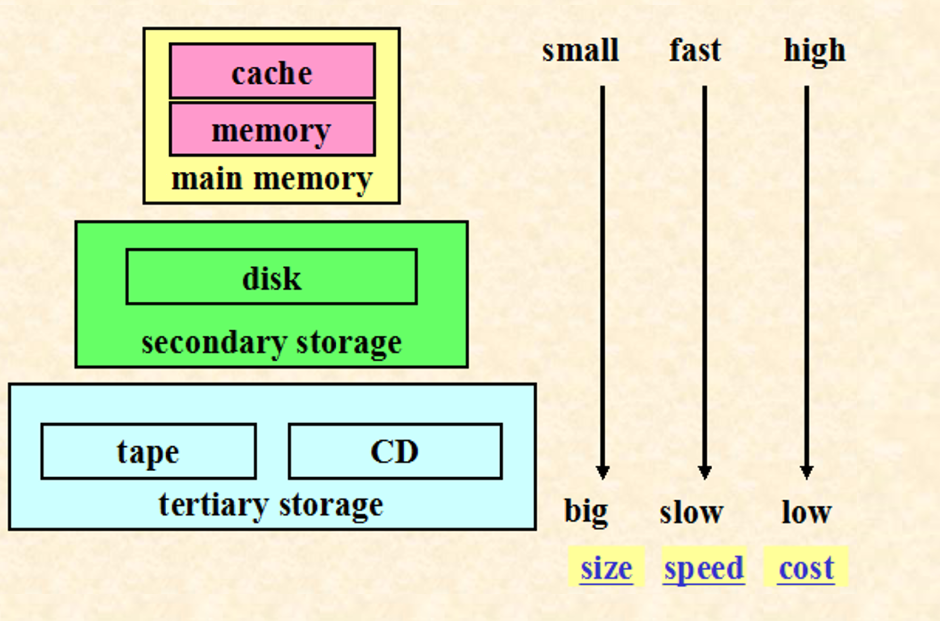
2.2. 不同存储的访问时间
2.2.1. 磁盘访问
- 寻道时间:圆盘臂移入或移出到正确的磁道位置。(.008s)
- 旋转延时:磁盘盘旋转到正确的角度位置。(.004s)
- 传输时间:磁盘臂在适当的表面上读取/写入磁盘页面。(.0005s)
- 访问时间:(10-8 - 10-7 s)
- 在很多结构中一行是连续的多个字节,很多行位于一页上(被称为Oracle的块)
- 头信息包含当前页是数据段还是索引段,以及当前页的编号。

- 磁盘中的行是从右侧向左侧添加的
- 标头后,行目录条目从左到右。给出相应行起点的偏移量。
- 在页面上提供行槽的编号。
- 当一行被添加后,会立即告诉我们是否还有剩余的空间给新的行文件
- 从概念上讲,中间的所有空间都表示删除行和回收空间必须移至填补空白的时间。
- 磁盘指针:可以用页码§和插槽号(S)唯一指定表中的一行。
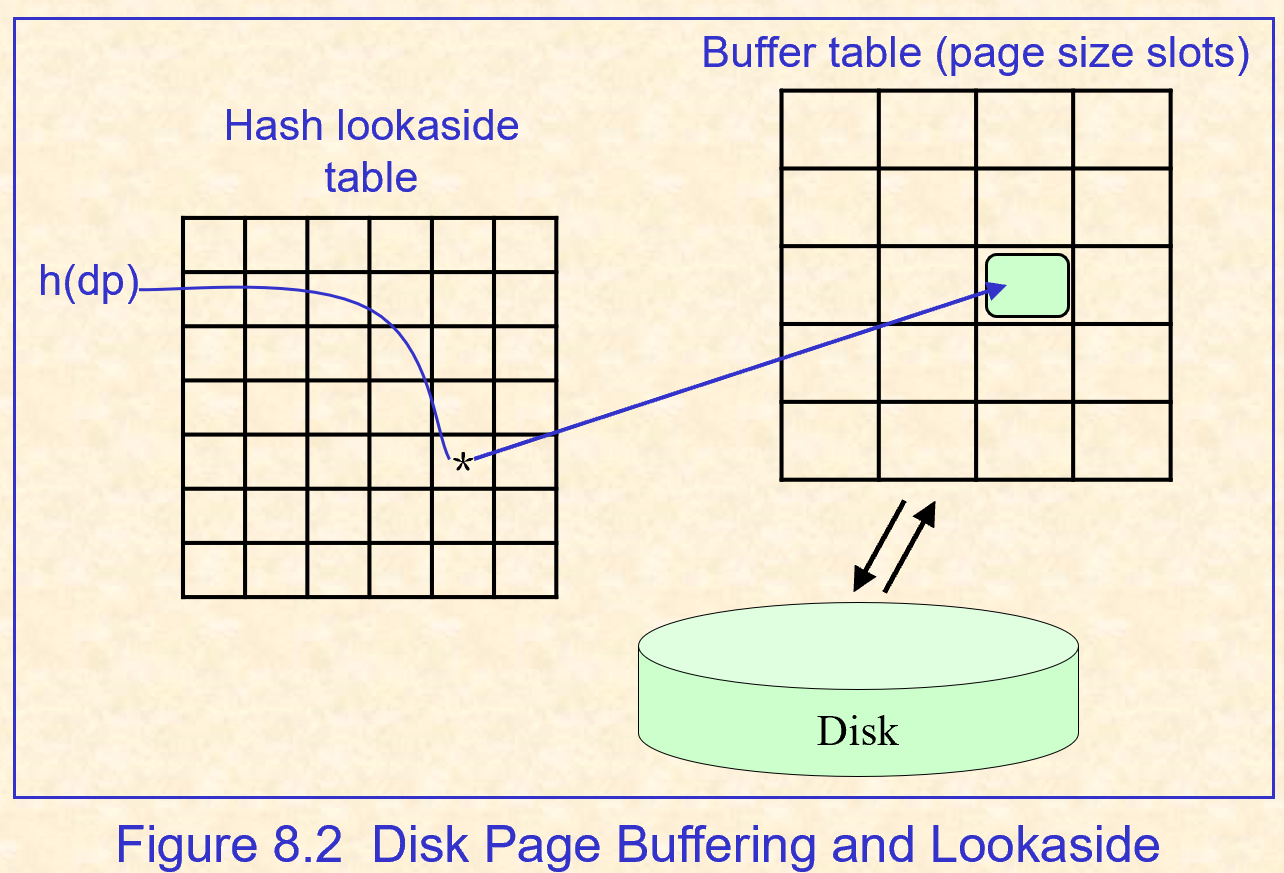
2.2.2. 内存缓存
- 将磁盘页读入到内存缓存,所以可以访问。一旦放在磁盘上正确的位置,传输时间就很便宜。
- 每次都希望有一个页面从磁盘,dkpgaddr,h(dkpgaddr)上的哈希表到Hashlookaside表中的条目,以查看该页面是否已在缓冲区中。
- 优点
- 节省磁盘I/O时间
- 在IO时间为CPU寻找一些事情来做
3. B树索引
- 每一个树的结点都是一个满了的磁盘页
- 每一个树的结点都有很多扇区
3.1. 创建索引的步骤
- 从磁盘中读出所有的N行
- 为每一行生成一个(键值, 行ID)对
- 将根据键值排序好的列表存储到磁盘中
- 如果具有NOSORT子句,则行按正确的顺序排列,因此不必排序。
3.2. 索引例子
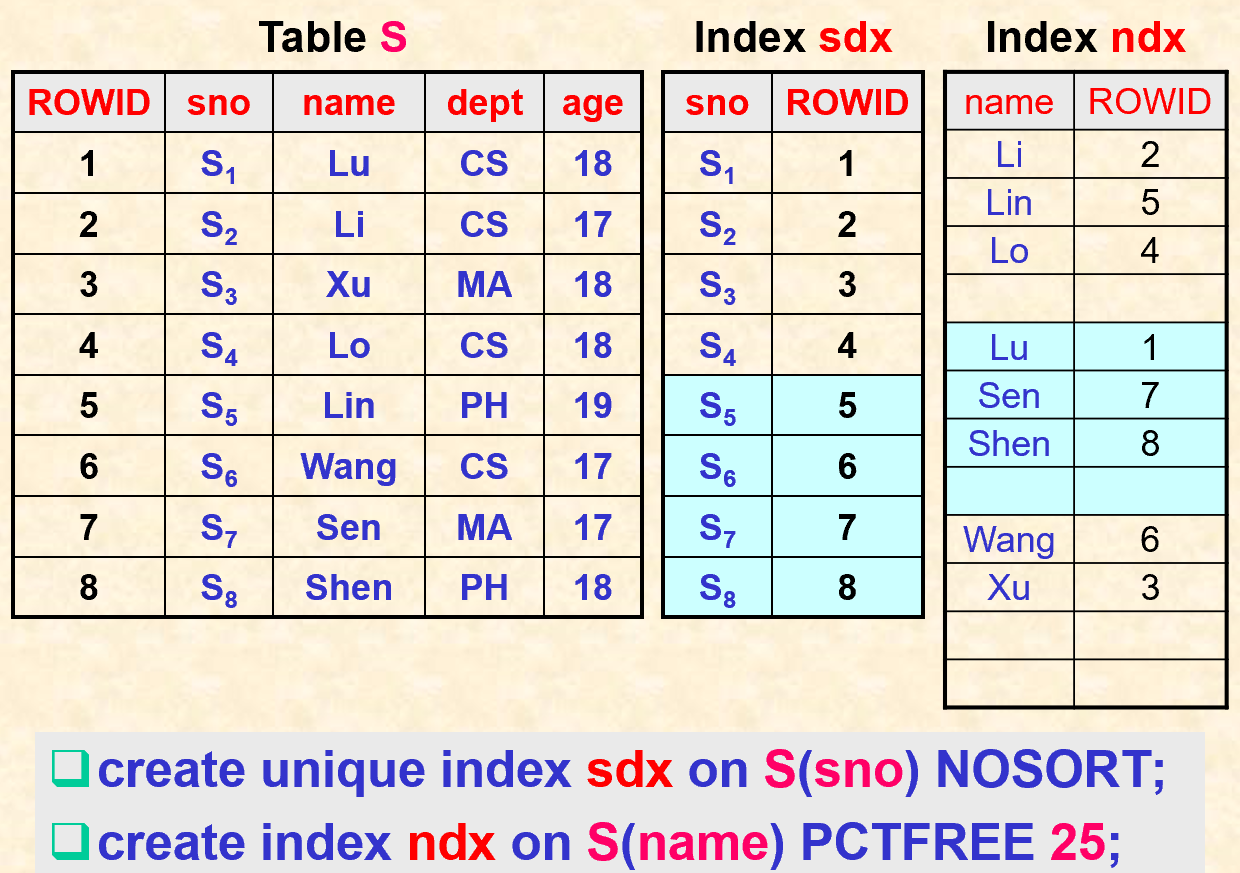
- PCTFREE:为一个块保留的空间百分比,表示数据块在什么情况下可以被insert,默认是10,表示当数据块的可用空间低于10%后,就不可以被insert了,只能被用于update;即:当使用一个block时,在达到pctfree之前,该block是一直可以被插入的,这个时候处在上升期。
3.3. 二分查找

- 二分查找效率
- 实体数量:106
- 每一个实体的大小:8 bytes
- 每一个磁盘页的大小:2k bytes
- 一个磁盘页上有250个实体
- 总共有4000个磁盘页
- 磁盘查找的效率为:
3.4. B树中的百万索引实体

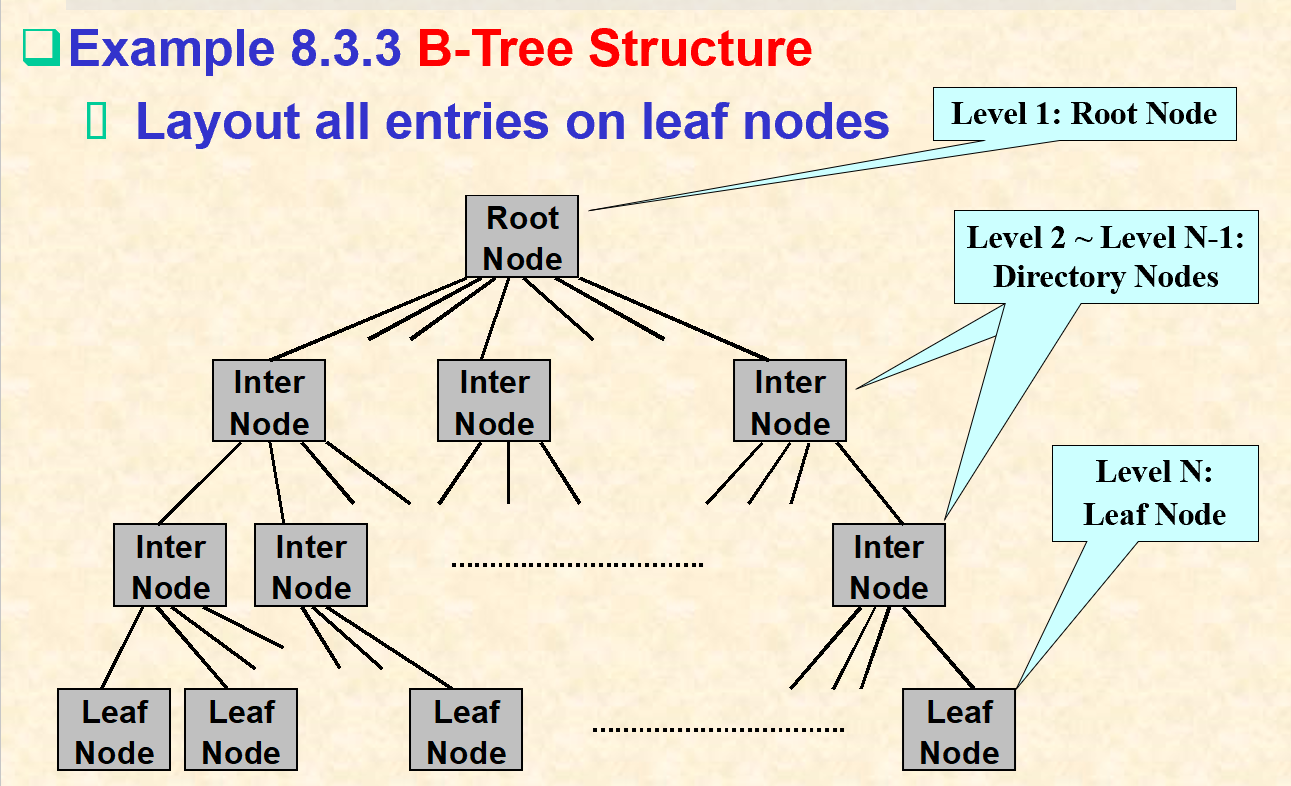
3.5. B树结构


- 秩为3的B树的内部结点
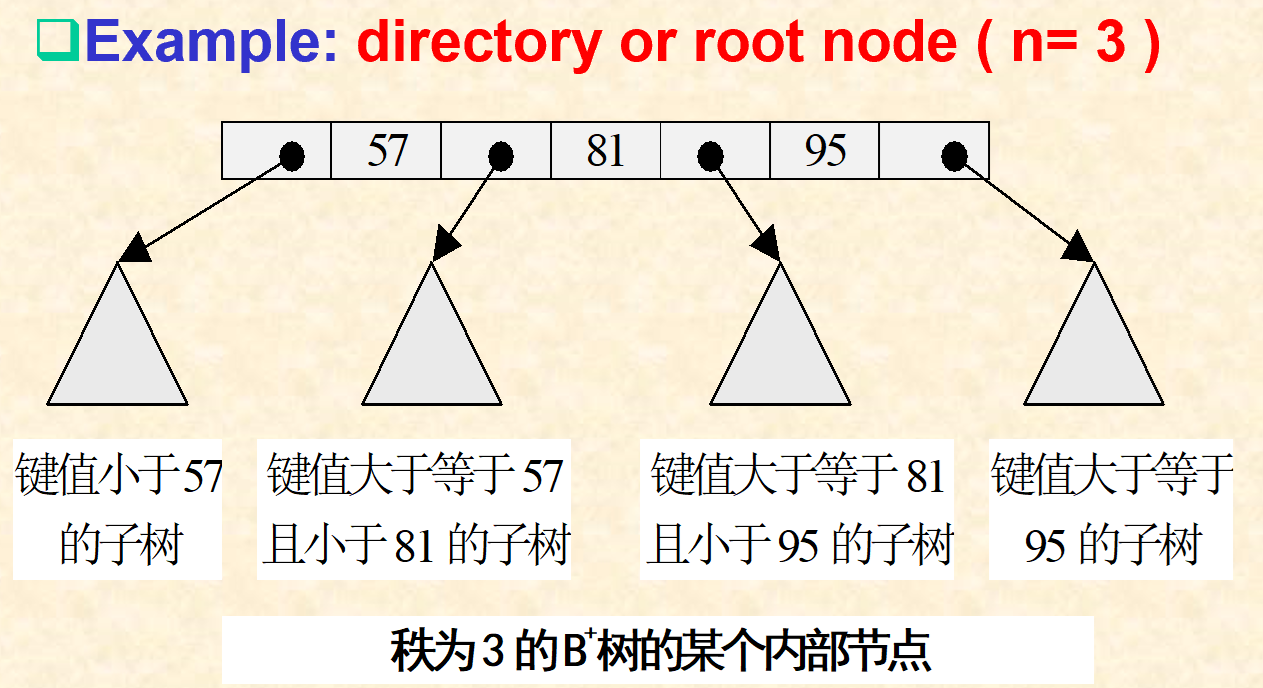
3.6. B+树的性质
- 每个节点都是磁盘页面大小的,并且位于磁盘上预先定义好的位置。
- 叶级以上的节点包含目录条目,带有(n–1)个分隔键和n个指向较低级B树节点的磁盘指针。
- 叶级上的节点包含具有(keyval,ROWID)对的条目,这些对指向已索引的各个行。
- 根以下的所有节点至少有一半充满条目信息。
- 多次删除后通常不执行此操作。
- 根节点至少包含两个条目(一个键值)。
- 除非仅索引一行并且根是叶节点。
3.7. 位图索引
- 位图索引为每个不同的键值使用一个位图。
- 位图代替ROWID列表,指定一组行。
- 1:这一行有键值
- 0:这一行没有键值
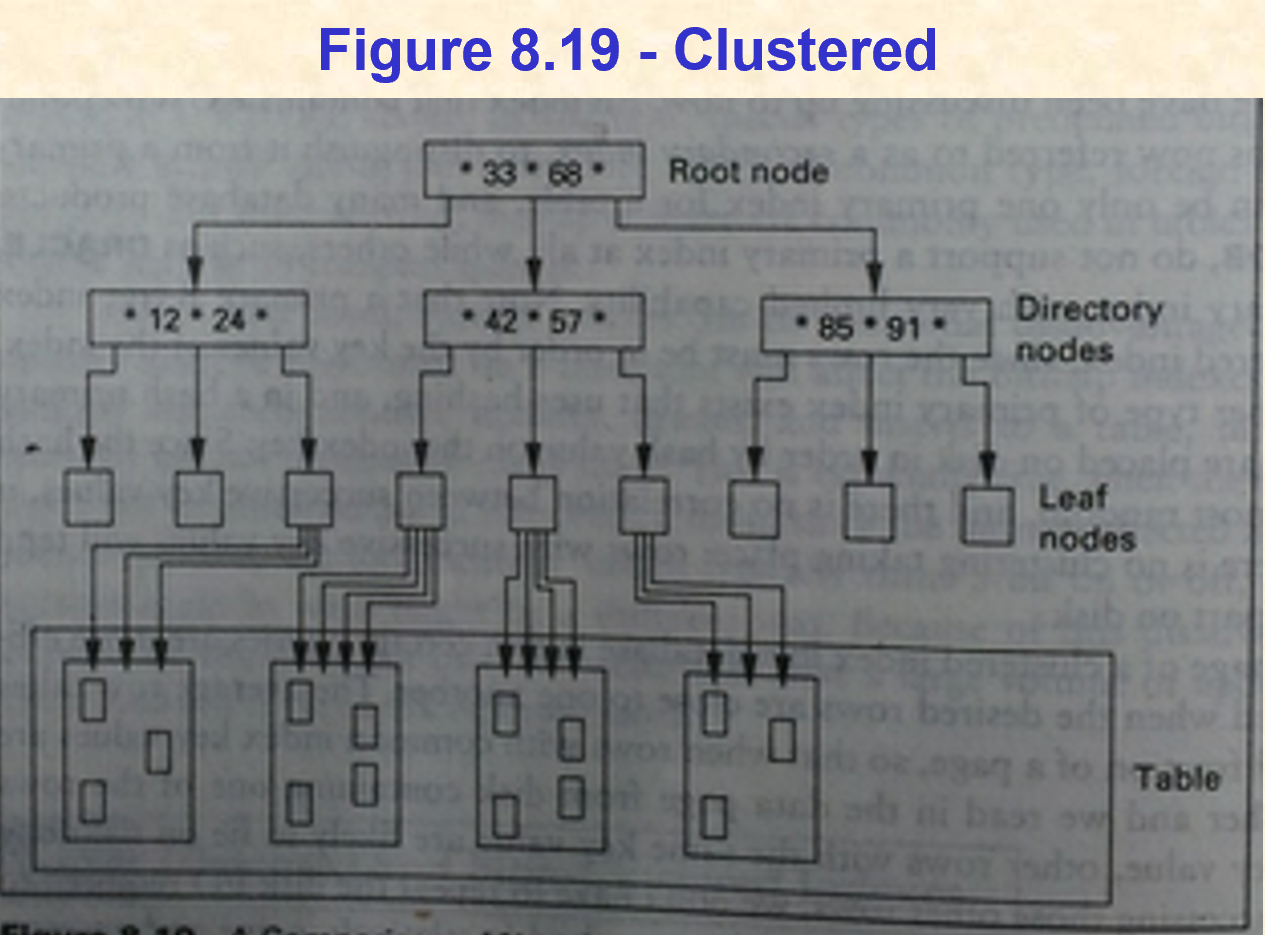
4. 聚集索引和非聚集索引
4.1. 聚集索引
- 表的行与索引条目的顺序相同-按键值。
- 在大多数数据库产品中,磁盘上数据页上行的默认放置是按加载或插入(堆)的顺序进行的。
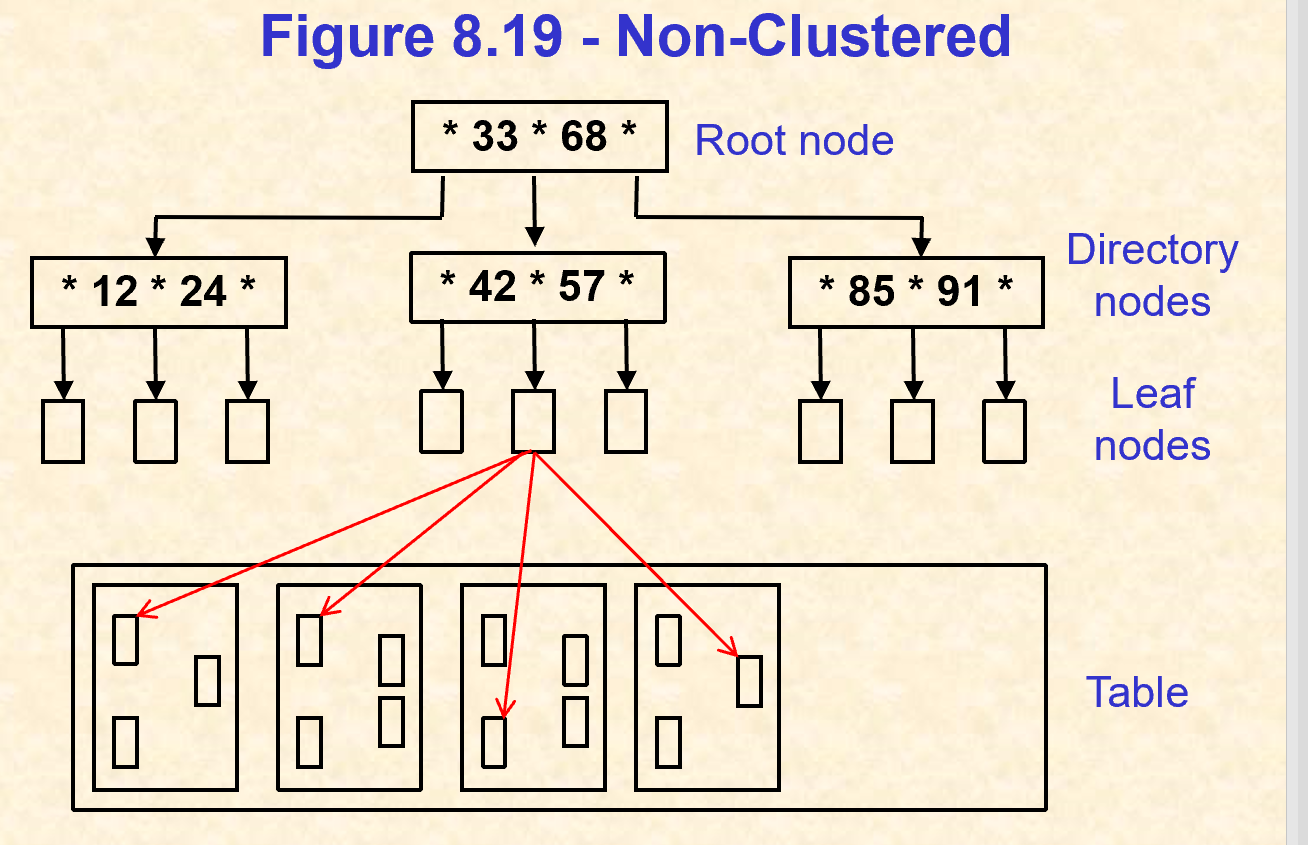
4.2. 非聚集索引
5. 哈希主键索引
- 使用哈希函数将位于哈希群集中的表中的行放置在伪随机数据页插槽中,并以相同的方式进行查找,通常仅使用一个I / O。
- 当然,也不根据键值排序
- 连续的键值并不太紧密,可能在完全不同的页面上,依靠哈希函数来确定位置。
5.1. 例子

2020-数据管理基础-ch08-数据库索引
https://spricoder.github.io/2020/07/03/2020-Fundamentals-of-Data-Management/2020-Fundamentals-of-Data-Management-ch08-%E6%95%B0%E6%8D%AE%E5%BA%93%E7%B4%A2%E5%BC%95/