Address=hash(key) also called : name-address function(名称-地址映射)
1.2. 散列函数
1.2.1. 如何寻找合适的散列函数
Find a proper hash function How to solve a collision Select a suitable load factor α.(寻找合适的hash函数如何解决冲突选择合适的负载因子α)
α=n/b
n is number of elements in the hash table b is the number of buckets in the hash table
α > 1 碰撞频率大
α < 1 碰撞频率小
1.2.2. 散列函数(1):取余法
大小通常取最大质数,避免造成散列中存在始终未用到的部分。
1.2.3. 散列函数(2):平方取中法
先进行原来的数据进行平方,然后选取中间的合适部分。
对于一个值,按照某一进制下进行处理,处理后选择其中合适的中间部分。(类字符串进行存取)
1.2.4. 散列函数(3):乘法杂凑函数
%1是留下小数部分
1.2.5. 散列函数(4):针对字符串-1
to add up the ASCII( or Unicode ) value of the characters in the string. 把字符串中的每一个字符的ASCII值或者Unicode值相加
1 2 3 4 5 6
publicstaticinthash( String Key, int tableSize ) { inthashVal=0; for( inti=0; i < Key.length( ); i++ ) hashVal += Key.charAt( i ); return hashVal % tableSize; }
Suppose TableSize = 10007, Suppose all the keys are eight or fewer characters long, 8*127=1016 hash function typically can only assume value between 0~1016 引起浪费(字符串过短会导致浪费)
1.2.6. 散列函数(5):针对字符串-2
相当于对原来常数级的事情,添加一个常数来形成多项式。
1.2.7. 其他散列函数(考试无要求)
EL-hash
1.3. 如何解决散列表冲突问题
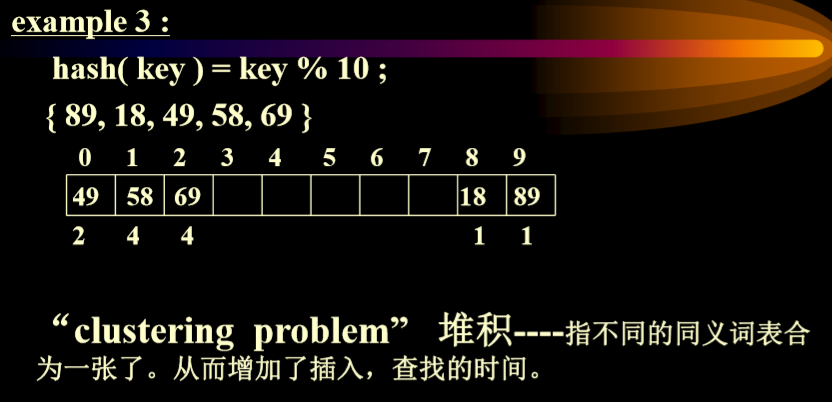
碰撞的两个(或多个)关键码称为同义词, 即H(k1)=H(k2),k1不等于k2
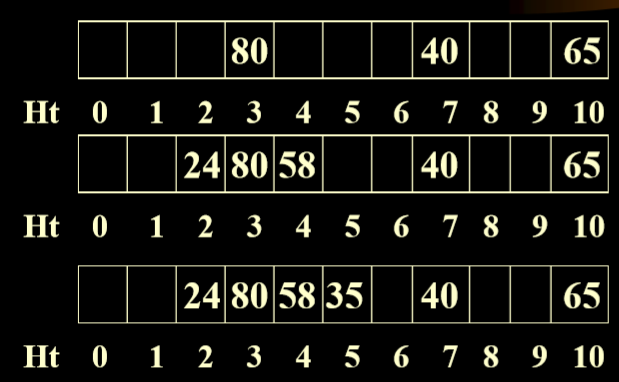
1.3.1. 解决冲突方案(1):linear Probing(线性探测法)
If hash(key)= d and the bucket is already occupied then we will examine successive buckets d+1, d+2,……m-1, 0, 1, 2, ……d-1, in the array(如何key的哈希值是d,并且d对应的位置已经被占据,然后我们会按照线性顺序向后成环形查找)
散列表已经满了之后,算法复杂度比较高,需要遍历整个散列表
例一
计算例一中的平均成功访问次数
例二
线性表示法的弊端:堆积问题
不能直接删除线性表中的数据,应该是标记上删除标记
1.3.2. 解决冲突方法(2):二次探测法(Quadratic probing)
If hash(k)= d and the bucket is already occupied then we will examine successive buckets d + 1, d + 22, d + 32 ……, in the array
放置hash值相同的情况下导致严重的堆积情况。
1.3.3. 解决冲突方法(3):双散列哈希(Double Hashing)
If hash1(k)= d and the bucket is already occupied then we will counting hash2(k) = c, examine successive buckets d+c, d+2c, d+3c……,in the array(如果k的第一哈希值为d,而这个对应的格子已经被占用则我们继续计算k的第二哈希值,然后检查d+c…)
//hashtable的构造方法 template<classE,classK>//E和K需要被实例化后,这个类才能被调用。 HashTable<E,K>::HashTable(int divisor){ D = divisor; ht = new E[D]; empty= newbool[D]; for(int i=0;i<D;i++) empty[i] = true; }
template<classE,classK> int HashTable<E,K>::hSearch(const K&k)const { int i= % D;//home bucket int j= i ; //start at home bucket do { if(empty[j] || ht[j]==k) return j;//fit j=(j+1)%D; //next bucket } while(j!= i); //returned to home?是否循环完成一遍 return j; //table full; }
//参数进行引用K&k template<classE,classK> bool HashTable<E,K>::Search(const K&k,E&e)const{ //put element that matches k in e. //return false if no match. int b= hSearch(k); if(empty[b]||Hash(ht[b])!=k)returnfalse; e=ht[b]; returntrue; }
template<classE,classK> HashTable<E,K>& HashTable<E,K>::Insert(const E& e) { K k=Hash(e);//extract key int b=hSearch(k); if(empty[b]){ empty[b]=false; ht[b]=e; return *this; } throwNoMem(); //table full }
public Hashable find(Hashable x) publicvoidinsert(Hashable x) publicvoidremove(Hashable x)
publicstaticinthash(String key, int tableSize) privatestaticfinalintDEFAULT_TABLE_SIZE=11;
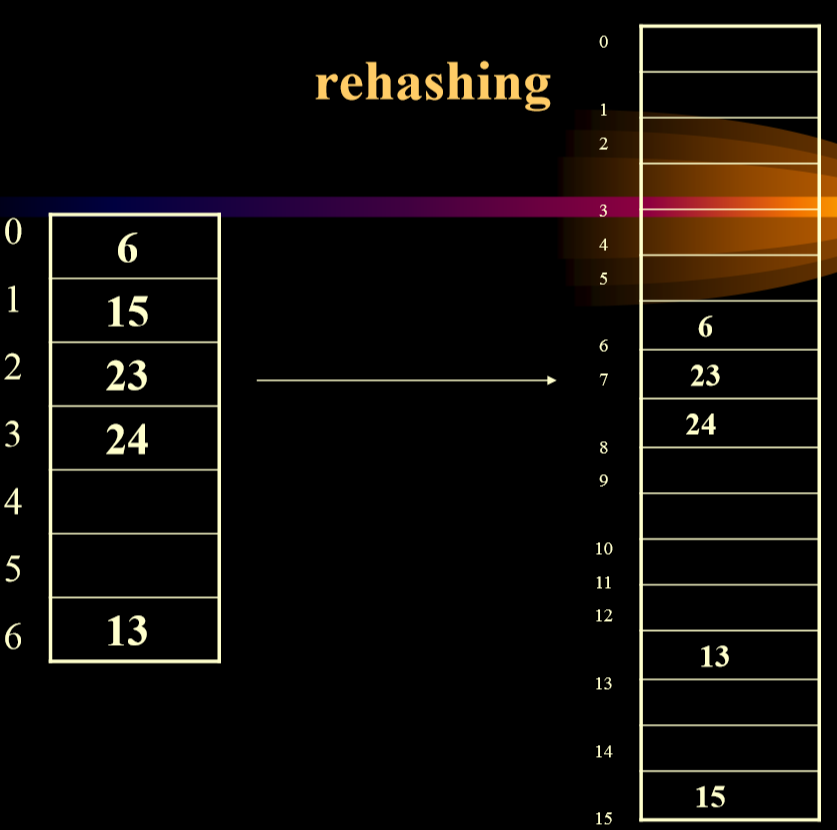
protected HashEntry [ ] array; privateint currentSize; privatevoidallocateArray(int arraySize ) privatebooleanisActive( int currentPos ) privateintfindPos( Hashable x ) privatevoidrehash( )//需要扩大hash表大小的时候,再哈希 privatestaticintnextPrime( int n ) privatestaticbooleanisPrime( int n ) }
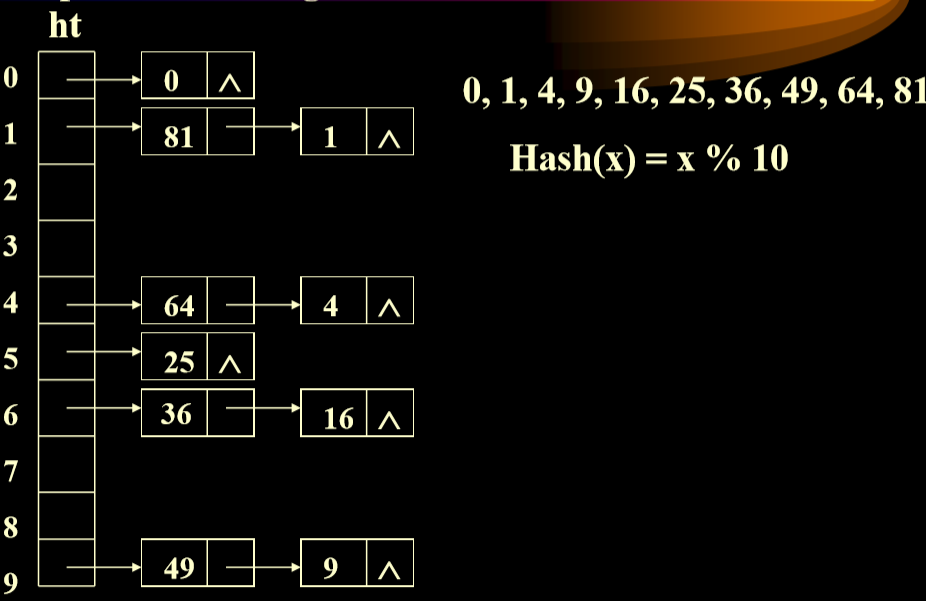
publicclassSeparateChainingHashTable { publicSeparateChainingHashTable( ) publicSeparateChainingHashTable( int size ) publicvoidinsert( Hashable x ) publicvoidremove( Hashable x ) public Hashable find( Hashable x ) publicvoidmakeEmpty( ) publicstaticinthash( String key, int tableSize )
privatestaticfinalintDEFAULT_TABLE_SIZE=101; private LinkedList [] theLists; privatestaticintnextPrime( int n ) privatestaticbooleanisPrime( int n ) }