2019-计算机组织与结构-lecture13
Bus
1. 总线(Bus)
-
Bus is a communication pathway connecting two or more devices(总线是连接两个或多个设备的通信通道)
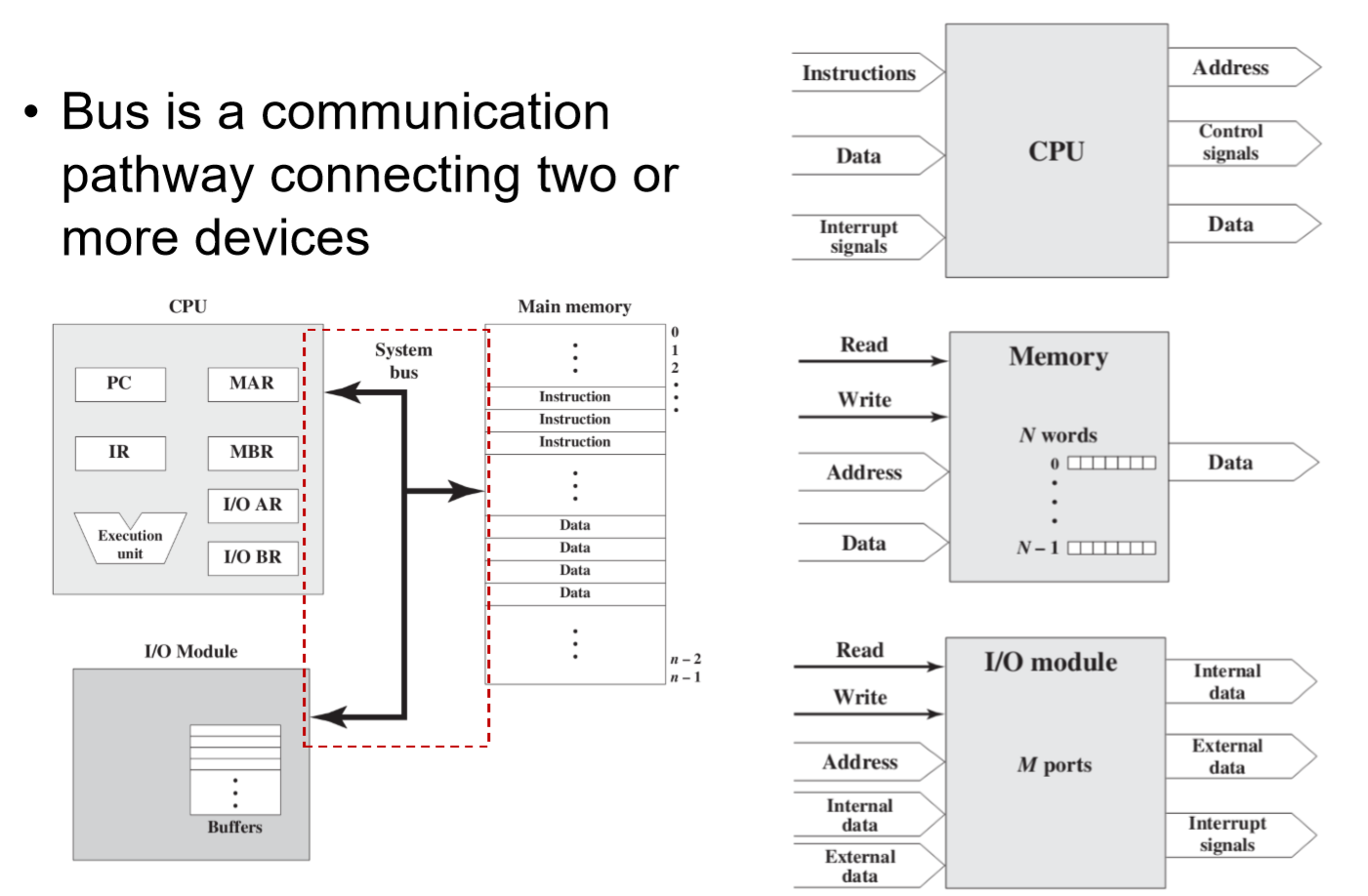
-
关键特点:(key Characteristic)
- A shared transmission medium(共享传输介质)
- Multiple devices connect to the bus(多种设备连接到总线)
- A signal transmitted by any one device is available for reception by all other devices attached to the bus(任何一个设备发送的信号可供连接到总线的所有其他设备接收)
- Only one device at a time can successfully transmit(一次只有一个设备可以成功传输)
- If two devices transmit during the same time period, their signals will overlap and become garbled(如果两个设备在同一时间段内传输,它们的信号将重叠并变得混乱)
2. 总线的类型
2.1. 总线的一种分类(层次型)
- Chip inner bus(芯片内部总线)
- Connect the parts inner a chip 连接芯片内部的各部分
- E.g. connect registers, ALU and other parts in CPU
- System bus(系统总线)
- Connect CPU, memory, I/O controller and other functional devices 连接CPU,内存,输入输出控制器或者其他功能设备
- Communication bus(通信总线)
- Connect host and I/O devices or connect different computer systems 连接主机和输入输出设备并且连接不同的计算机系统
- 上面是按照层级来的,层级由小到大。
- Intel的系统总线如下
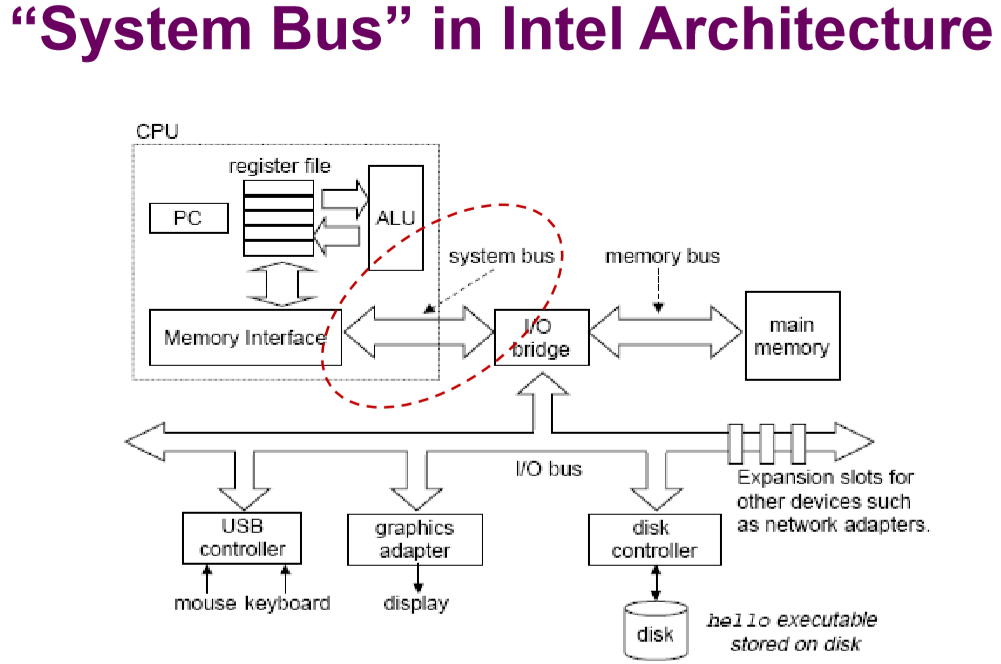
2.2. 总线的另一种分类(功能型)——总线的组成
- Bus lines can be classified into three functional groups(总线可以被分类为三个功能的集合)
- Data lines: move data between system modules(数据总线:在系统各个模块之间传输数据)
- The number of data lines determines the size of data can be transferred at one time(数据总线的数量决定着能够一次性传输数据的大小情况,简单说就是一次能够传输多少位的信息)
- Address lines: designate the source or destination of the data on the data bus and address I/O ports(地址总线:指定数据总线上数据的源或目标以及地址I/O端口)
- The number of address lines determines the size of addressing space(地址行的数目决定了地址空间的大小)
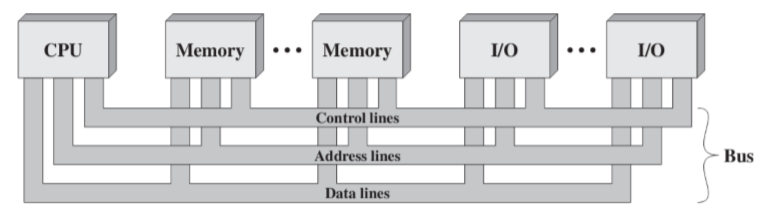
- Control lines: control the access to and the use of the data and address lines(控制总线:控制访问和使用数据、地址线的权限)
- Clock: bus synchronization(时钟:总线同步)
- Bus request: the device sending the signal requests bus(总线请求:发送信号的设备请求总线)
- Bus grant: the device receiving the signal can use bus(总线授权:接受信号的设备可以使用总线)
- Interrupt request: some interrupt requests(中断请求:一些中断请求)
- Interrupt acknowledge: some interrupt request is permitted(中断确认:允许某些中断请求)
- Memory read: read data from memory to bus(内存读出:将一些数据从内存中读出到总线)
- Memory write: write data from bus to memory(内存写入:将一些数据从总线写入到内存中去)
- I/O read: read data from I/O port to bus(I/O读出:从I/O模块将数据读入总线)
- I/O write: write data from bus to I/O port(I/O写入:将数据从总线写入到I/O模块)
2.2.1. Design element设计元素
- Bus type(总线类型)
- Dedicated, multiplexed(专用总线,复用总线)
- Arbitration(仲裁)
- Centralized, distributed(中心式的,分布式的)
- Timing(时间)
- Synchronous, asynchronous, semi-synchronous, split transaction(同步的,异步的,半同步的,分割式的)
- Bus bandwidth and data transfer rate(总线带宽和数据传输速率)
- Bus hierarchy(总线层次)
- Single bus, double bus, multiple bus(单总线,双总线,多总线)
3. Bus Type总线类型
- Dedicated bus(专用总线): permanently assigned either to one function or to a physical subset of computer components(永久分配给计算机组件的一个功能或物理子集)
- Advantage: high throughput for there is less bus contention(优点:高吞吐量,减少总线争用)
- Disadvantage: the increased size and cost(缺点:体积和数量会增大,价格会增高)
- Multiplexed bus(复用总线): use the same lines for multiple purposes(用相同的线来完成不同的目的)
- Advantage: fewer lines to save space and cost(优点:更少的线来节省空间和代价)
- Disadvantage: need more complex circuitry within each module and potentially reduce performance for sharing(缺点:在每个模块中需要更复杂的电路,并可能降低共享的性能)
- 复用有着多种形态,有可能是一条复用总线(传输地址、指令等),也可能是CPU和ALU的复用总线(传输地址、指令等)。
4. Arbitration(仲裁)
- A bus can be listened by multiple devices but only sent information by one device(总线是被多种设备监听,但是仅仅把信息送给一个设备)
- Bus arbitration(总线仲裁)
- Choose one device by some strategy when multiple devices want to communicate with bus(通过策略在多个想要和总线进行通信的设备中选择一个)
- Balance(平衡)
- Priority(优先级): the device with higher priority should be serviced first(有高优先级的设备更加可能被优先服务)
- Fairness(公平): the devices with the lowest priority cannot be delayed forever(优先级低的设备有可能一直用不到总线)
- 优先级和公平性本来就是矛盾的,没有好坏之分。
- 总线上:必须要等总线空闲的时候看优先级来完成。
4.1. Arbitration Type(总裁类型)
- Centralized scheme(集中式): a single hardware device, referred to as a bus controller or arbiter, is responsible for allocating time on the bus(一个简单的作为总线控制器或者仲裁器的硬件设备,它负责为总线各个设备分配使用时间)
- Daisy chain(链式)
- Query by a counter(计数器查询法)
- Independently request(独自请求)
- Distributed scheme(分布式): each module contains access control logic and the modules act together to share the bus(每一个部分包含权限控制逻辑并且每个模块同时相应去共享总线)
- Self selection(自主选择)
- Collision detection(冲突探测)
5. 集中式仲裁方式
5.1. Daisy Chain(菊花链式)
- All the devices are connected serially, and grant is delivered from the highest priority device to the lowest priority device(所有的设备会被线性的连接,并且许可信号被从高优先级的设备传递到低优先级的设备上去)
- If one device receives the grant and has bus request, the device sets the bus busy and the grant is not further delivered(如果一个设备有许可并且有总线请求,那么这个设备会设置总线为忙并且不再发送许可信号)

- 最左边的是仲裁器,黄色的线表示总线忙,Grant是许可线,来确定具体是哪一个设备可以使用。
5.1.1. 优点
- Simple to determine the priority(很简单来保证优先级)
- Flexible to add devices(添加设备容易)
5.1.2. 缺点
- Cannot ensure the fairness(不能保证公平)
- Sensitive to circuit fault(对于设备内部的总线损坏十分敏感,如果高优先级损坏,低优先级完全无法使用)。
- Limit the bus speed(限制总线速度,需要遍历,线性)
5.2. Query By A Counter(计数器查询法)
- Remove bus grant line, and use devices ID lines(移除了许可总线,使用装置ID线)
- If the bus is not busy, the bus arbiter sends the count through device ID lines(如果总线不忙,则总线仲裁器通过装置ID线发送计数)
- If one device requests the bus whose ID equals to the current count, the arbiters stops counting and the device sets the bus busy(如果一个设备需要总线,并且ID和当前的技术相同,则仲裁器终止技术并且设备设置总线为忙。)
- 通过不同报数规则保证公平性等。

- 图中每一个线不是一根线,而是一组线,有N位,则至少有log2N 向上取整个。
- 报号是不会故意等很久的,按照匀速率往下报号。
- 会稍微等一下,但是不会等很久
- 报号的方式是可以控制的
5.2.1. 优点
- Flexible to determine the device priorities by using different initial counts(通过不同初始化的技术来决定设备的优先级)
- Fixed priority: 0(初始化优先级:0)
- Fair priority: the ID following the device used the bus(公平优先级:ID对应的设备使用总线)
- Not sensitive to circuit fault(对于设备电路损坏不敏感)
- 可以很灵活,可以平衡公平和灵活。
5.2.2. 缺点
- Add the device ID lines(添加了设备ID线)
- Require to decode and compare device ID signal(需要解码和比较ID信号)
- 响应速度比较慢。
5.3. Independently Request(单独请求)
- Each device has its bus request line and bus grant line(每一个设备都有自己的请求线和总线许可线)
- When one device request the bus, it sends the request signal to bus arbiter through the bus request line(什么时候一个设备需要总线,它就通过总线请求线来发送信号给总线仲裁器)
- Bus arbiter determines which device can use the bus(总线仲裁决定了哪一个设备可以使用总线)
- Determination strategy: fixed priority, fair daisy chain, LRU, FIFO, …(很多的策略)
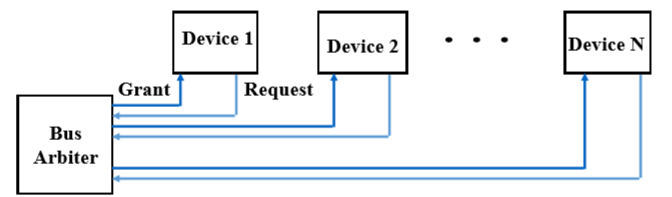
5.3.1. 好处
- Fast response(快速)
- Programming priority(优先级可以调整)
5.3.2. 缺点
- Complex control logic(复杂的控制逻辑)
- 为什么?是仲裁器电路比较复杂。
- More control lines(更多的控制线)
6. 分布式仲裁方式
6.1. Self Selection 自主选择
- Fixed priority(固定优先级)
- Each device sends the request on its bus request line(每一个设备都可以发送请求到他自己的请求总线的线上)
- The lowest priority device doesn’t have request line(最低优先级的设备不需要有总线请求线)
- Each device independently determines whether it is the device with the highest priority(每一个设备都可以独立的决定这个设备是不是最高优先级)
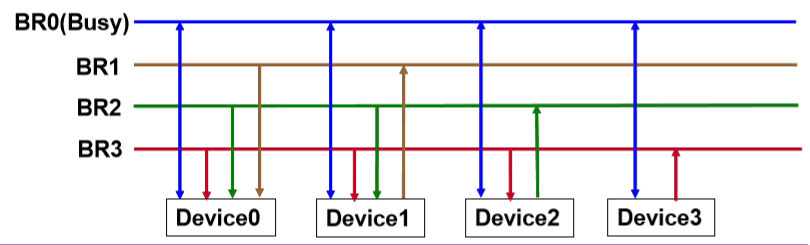
- 3的优先级最高:因为3的线最少
- 蓝色线:双向线:需要监听总线忙或者不忙
- 如果总线不忙:3使用,通过红色告诉012
- 如果总线不忙、3不用:2使用,通过绿色告诉01
- 如果总线不忙、23不用:顺序向下
6.2. Collision Detection(冲突检测法)
- When one device wants to use the bus, it checks whether the bus is busy(当一个设备想要使用总线,它来检测总线是否在忙)
- If bus is not busy, the device uses the bus(如果总线空闲,那么设备使用总线)
- Collision: if two devices found the bus is not busy, they may use the bus at the same time(冲突:如果两个设备都发现总线空闲,他们有可能同时使用总线)
- In data transfer, the device will listen to the bus and check whether exists a collision(在数据传输过程中,设备需要监听总线并且确定是否存在冲突)
- If a collision happens, all the devices using bus will stop data transfer and request the bus after a random duration(如果发生冲突,所有使用总线的设备将停止数据传输,并在随机时间后请求总线)
- 抢椅子,如果抢到了,发现总线占用,则进行再次争夺。
- 不关心谁在用,而只是发送数据上去,监听有无数据扰动,如无则无人使用,正常使用即可,否则放弃总线,随机等待一定时间后再次使用。
7. Timing(时序)
- The way in which events are coordinated on the bus(在总线上协调事务的方式——时序)
- Determine the start and end time of each bus transaction(确定每个总线事务的开始和结束时间)
- Type(类型)
- Synchronous timing(同步时序): the occurrence of events on the bus is determined by a clock(总线上的所有事务的发生由时钟决定)
- Asynchronous timing(异步时序): the occurrence of one event on a bus follows and depends on the occurrence of a previous event(总线上的事务的发生取决于它的前置事务的发生)
- Semi-Synchronous(半同步): combine synchronous timing (clock) and asynchronous timing (handshaking)(结合同步时钟和异步时序(握手))
- Split bus transaction(事务分隔): release the bus when the devices prepare data(在设备准备事务的时候释放总线)
7.1. Synchronous(同步总线)
- Bus transaction(总线事务): address + data + … + data(传输一次地址和很多的数据)
- 同步总线只能很短,不然会出现问题(时钟混乱)
- 数据过长会导致不同步,造成问题。
7.1.1. Advantage
Simpler to implement and test(很简单去实现和测试)
7.1.2. Disadvantage
- All the device share the same clock(所有的设备使用相同的时钟)
- Bus length is limited for clock skew(总线长度被时钟偏移限制)
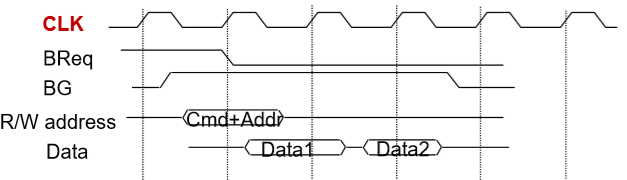
7.2. Asynchronous(异步问题)
- Bus transaction: address + data + … + data
- Use handshaking protocol(使用握手规则)

- 蓝色表示先后关系,也就是"一次握手"
- Ready是"我准备好了"
- Ack是"我收到了"
- 第一个握手(No interlock):我告诉你我准备好了
- 第二个握手(Semi-interlock):"我准备好了"信号只能在你说"我收到了"之后才能撤回。
- 我告诉你我已经收到了
- 第三个握手(interlock):我知道你知道"我收到了"之后才能撤回
- 发送方和接收方都要各发出一个信号,接收一个信号
- 握手之前有相应的准备
7.2.1. Advantage
- Flexible to the devices with different speeds(可以很灵活的适应不同速度的设备)
7.2.2. Disadvantage
- Sensitive to noise(对于噪声比较敏感)
- Complex interface logic(复杂的接口逻辑)
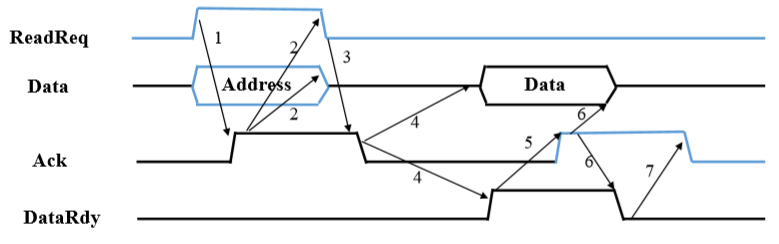
7.2.3. CPU从内存中读取一个数据

- CPU puts address and sets ReadReq line => Memory reads address(CPU告诉内存物品地址已经放上去了)
- Memory reads address and sets Ack line => CPU releases address lines and ReadReq line(内存告诉CPU我已经收到了地址了)
- CPU release address lines and ReadReq line => Memory releases Ack line(CPU撤回我已经放上去地址了)
- Memory releases Ack line => Memory puts data on data lines(情况Ack信号线)
- 如果没有的话,Ack的回复信号(4)会被误认为是(6),所以这一步就是为了清空信号线
- Memory puts data on data lines and sets DataRdy line => CPU reads data(内存告诉CPU我准备好数据了)
- CPU reads data and sets Ack line => Memory release data lines and DataRdy line(CPU告诉内存我已经收到数据了)
- Memory releases data and dataRdy line => CPU releases Ack lines(内存撤回我准备好数据了)
- 7次握手(3*2+1) => 2次传递 => 中间有一次来分开
- 蓝色:CPU干的事情,黑色:内存干的事情。
- ReadReq:读取是否准备好了
- Data:数据线
- Ack:信号线
- DataRdy:数据是否准备好了
7.3. Semi-Synchronous(半同步信号)
- To reduce the influence of noise, use clock in asynchronous timing(为了减少噪声的硬性,我们在异步的时候使用时钟)
- Ready and reply signals are valid in the rising edges of clock(准备好的信号和恢复信号只有在时钟信号高电平的时候才有效)
- 有效的避免了噪声。
- Combine the advantage of synchronous and asynchronous timing(结合了同步和异步时序的优点)
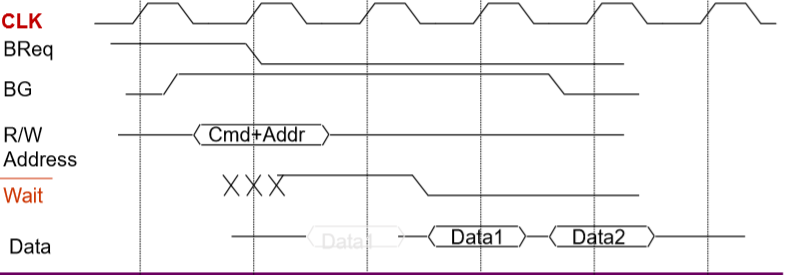
- 在异步总线中会受到噪音的干扰
7.4. Split Bus Transaction(总线事务分隔)
- Split one bus transaction into two procedures(将总线事务进行了分割)
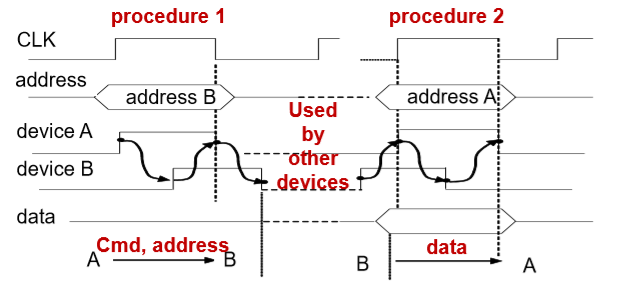
- 就是将两个信号之间的总线释放出来
- 事务是一个不可分割的部分,理论上总线在这段时间全部被占用,但是实际上会有被闲置的时刻,所以我们设备在准备数据的时候,将总线释放出来。
7.4.1. 优点
increase the bus utilization(提高了总线的利用率)
7.4.2. 缺点
increase the duration of each bus transaction and system complexity(增加了系统总线的事物时间间隔和系统的复杂性)
8. Bus Bandwidth and Data Transfer Rate(带宽和数据传输率)
- Bus bandwidth(带宽): the maximum data transfer rate of bus(总线的最大数据传输速率)
- Don’t consider bus arbitration, address transfer, …(不包含其他时间)
- 一个数据/最短时间:最大带宽
- Data transfer rate(数据传输率)
- Consider address transfer, …(包含了各种时间)
- Bus width(总线宽度): the number of lines to compose a bus(组成总线的线的个数)
- The wider the data bus, the greater the number of bits transferred at one time(数据总线越宽,一次性能够传递的数据的位数越多)
- The wider the address bus, the greater the range of locations that can be referenced(地址总线越宽,地址能够表示的范围越宽)
- 最大时间传输率:包括传输地址等待等时间来进行计算,而不是带宽。
8.1. Data Transfer Rate of Synchronous Bus and Asynchronous Bus(同步总线和异步总线的数据传输率)
- Data transfer rate = d/t(t包含三个步骤:先送过去地址,准备好数据,将数据传回)
- 传送时间:和总线宽度、数据宽度有关
- 握手和CPU处理一般是并行处理的
8.1.1. 同步总线和异步总线的例一
- Assume the clock cycle of synchronous bus is 50ns and each transfer requires one clock cycle, asynchronous bus requires 40ns for each handshaking. Both buses have 32 bits width, and the data prepare time of memory is 200ns. Calculate the data transfer rates of the two buses when read one word (32 bits) from memory.(我们假设同步总线的时钟周期为50ns,并且每一次数据传输需要一个时钟周期,异步总线每次握手需要40ns。两种总线均为32位宽,并且数据的准备时间均为200ns,计算当总线从内存中读取一个字(32位)的时候的数据传输率)
- Synchronous bus(同步总线)
- Sends command and address to memory: 50ns
- Memory prepares data: 200ns
- Transfers data to CPU: 50ns
- Data transfer rate = 4B / (50 + 200 + 50)ns = 106.7Mbps
- Asynchronous bus
- Step 1: 40ns
- Step 2, 3, 4: max(40ns*3, 200ns) = 200ns
- Step 5, 6, 7: 40ns * 3 = 120ns
- Data transfer rate = 4B / (40 + 200 + 120)ns = 88.9Mbps
- 第二个开始才有地址,第五个开始前必须要准备好,示意图如下
8.1.2. 例二
- Assume the clock cycle of synchronous bus is 50ns and each transfer requires one clock cycle, asynchronous bus requires 40ns for each handshaking. Both buses have 32 bits width, and the data prepare time of memory is 230ns. Calculate the data transfer rates of the two buses when read one word (32 bits) from memory.(我们假设同步总线的时钟周期为50ns,同时我们每一次传输数据都需要一个时钟周期,异步总线每次握手需要40ns,两个总线均为32位宽,并且数据的准备时间均为230ns,计算两种总线在从内存中读取一个字的数据传输率)
- Synchronous bus
- Data transfer rate = 4B / (50 + 250 + 50)ns = 91.4Mbps
- 修改为230必须要等20ns,因为一个时间周期不可以做两件事情。
- Asynchronous bus
- Data transfer rate = 4B / (40 + 230 + 120)ns = 82.1Mbps
8.1.3. 例三
- Assume a system has the following characteristic:(我们假设一个系统有如下特性)
- It supports to access the blocks with the size of 4 to 16 words (32 bits per word)(这个系统支持访问大小为4或者16字的块(每个字有32位))
- Synchronous bus has the 64 bits width and 200MHz clock frequency, which
requires one clock cycle to transfer address or 64 bits data(同步总线有64位宽,并且时钟周期为200MHz,需要一个时钟周期来传递地址或者64位的数据) - There are two idle clock cycles between two bus transactions(两个总线事务之间有两个空闲的时钟周期)
- The access time of memory requires 200ns for the first 4 words, and then
reduces to 20ns per 4 words(访问内存的时间,前4个字需要200ns,之后每4个字需要20ns) - When the previous data is transferred on bus, memory is reading the following
data at the same time(当前面的数据在被传入总线,内存同时可以读取出后面的数据)
- If read 256 words, calculate the data transfer rate, transfer time and bus transactions number per second when transfer 4 words and 16 words each time, respectively(如果读出来256个字,计算在每次读出来4个字和16个字的时候的数据传输率,传输时间和每秒能够处理的事物的个数)
- 问题一:Transfer 4 words each time 每次传送4个字
- Bus transaction: address + 4 words data
- Address transfer: 1 cycle
- Data read: 200ns (40 cycles)
- Data transfer: 2 cycles(读出和读入各1个周期)
- Idle: 2 clock cycles
- Total: (256 / 4) * (1 + 40 + 2 + 2) = 2880 cycles
- Transfer time = 2880 * 5 = 14400ns
- 一个时钟周期5ns
- Bus transaction number per second = 64 * 1s / 14400ns = 4.44M
- Data transfer rate = 256 * 4B / 14400ns = 568.9Mbps
- Bus transaction: address + 4 words data
- 问题二:Transfer 16 words each time
- Bus transaction: address + 16 words data
- Address transfer: 1 cycle
- Data read (first 4 words): 200ns (40 cycles)
- Data transfer: 2 clock cycles (read the following 4 words)
- Idle: 2 clock cycles (finish the following 4 words read)
- Total: 256 / 16 * (1 + 40 + 3 * max(4, 2) + 2 + 2) = 912 cycles
- 特性五
- Transfer time = 912 * 5 = 4560ns
- Bus transaction number per second = 16 * 1s / 4560ns = 3.51M
- Data transfer rate = 256 * 4B / 4560ns = 1796.5Mbps
- Bus transaction: address + 16 words data
8.2. 增加同步总线的宽度和数据传输率(Increase Bandwidth and the rate of data transfer Of Synchronous Bus)
- Increase clock frequency(提高时钟频率)
- Increase data bus width(增加数据总线的宽度)
- Transfer more data each time (cost: more bus lines)(每次传输更多地数据)
- Block transfers(块传输)
- Transfer address once and transfer data (cost: high complexity)(同时传送地址和数据,代价是高复杂度)
- Split bus transaction(切割总线事务)
- Increase system bandwidth (cost: high complexity, enlarge the duration of each transaction)(增加总线宽度,代价是高复杂度,增加了每个总线事务的时间)
- Separate address lines and data lines(分离地址线和数据线)
- Transfer address and data simultaneously (cost: more bus lines, high complexity)(同时传递地址和数据,代价是更多的总线的长度和高复杂度)
9. 总线层次结构(Bus Hierarchy)
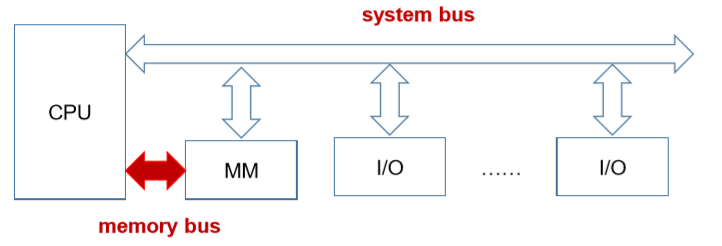
9.1. Single bus hierarchy(一根总线)
- CPU, memory and I/O modules attach to system bus(CPU,主存和I/O模块连接到系统总线)
- I/O模块不是I/O
- Advantage: simple, easy to extend(简单,容易扩展)
- Disadvantage: bus is the bottleneck(总线是瓶颈)

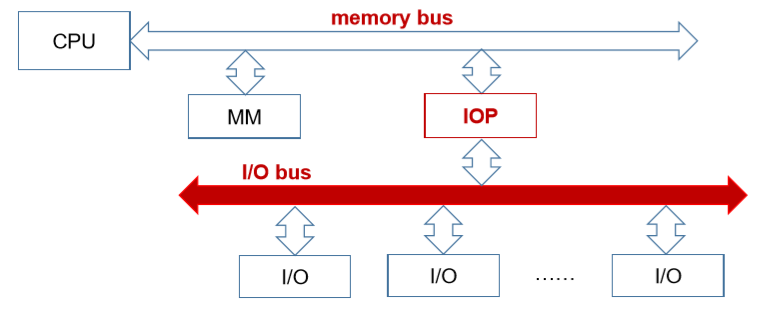
9.2. Double bus hierarchy 双总线结构
- Add a memory bus between CPU and memory(在CPU和主存之间添加了存储总线)
- Advantage: increase the transfer efficiency between CPU and memory, and reduce the burden of system bus(提高了CPU和主存之间的数据传输效率,并且减少了系统总线的负担)
- Split system bus to memory bus and I/O bus with IOP (input/output processer)(把系统总线划分为存储总线和I/O总线)
- Advantage: reduce the burden of I/O(减少了I/O的负担)
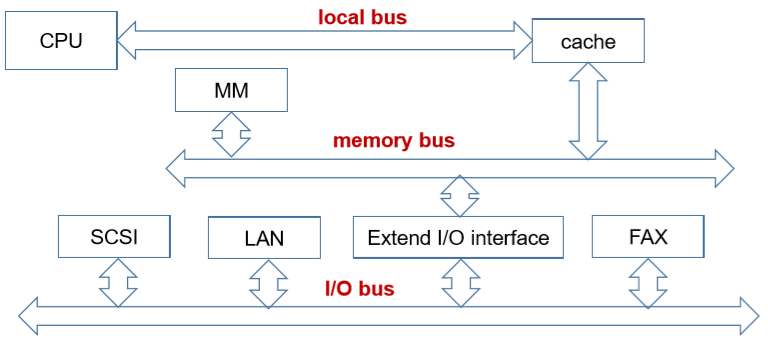
9.3. Multiple bus hierarchy 多总线结构
- Split system bus to memory bus and I/O bus, and add DMA bus(添加了I/O总线和DMA总线)
- Advantage: increase I/O efficiency(优点:增加了I/O模块的效率)
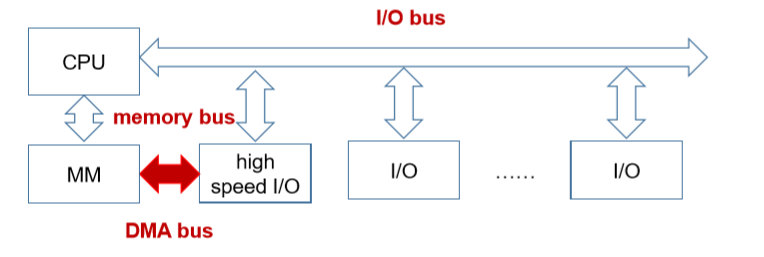
- Add a local bus to connect CPU and cache(添加了CPU和cache之间的总线)
- Advantage: separate CPU with I/O communication(把CPU从I/O交互中解耦)
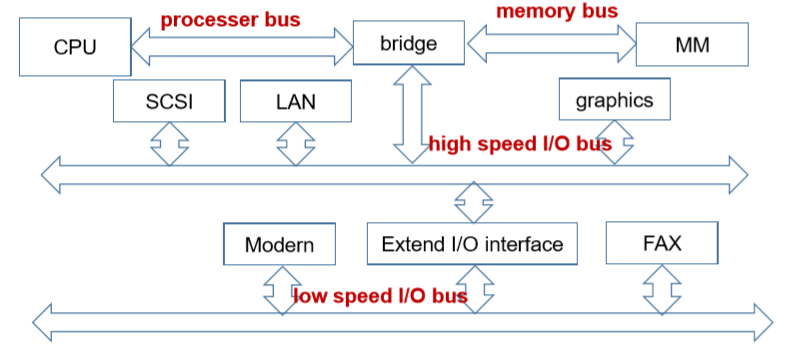
- Add a high speed I/O bus to connect high speed devices(使用桥接,两层总线,一层快I/O总线,一层慢I/O总线)
- Advantage: increase I/O communication efficiency(提高了I/O交互的效率)
2019-计算机组织与结构-lecture13
https://spricoder.github.io/2020/01/16/2019-COA19/2019-COA19-lecture13/