使用指南 | IoT Benchmark 生成模拟数据集和写入
IoT Benchmark 是基于 Java 开发的时序数据库测试工具,支持 Apache IoTDB 各版本、InfluxDB 等多款数据库的测试,支持生成模拟数据集和使用真实数据集,并且完成多种配置的读写混合测试。本文主要介绍了如何使用 IoT Benchmark 生成模拟数据集和加载外部数据集。
1. 生成模拟数据集
IoT Benchmark 支持将生成的模拟数据集持久化到本地,修改如下的配置:
1 | |
执行模拟数据集生成,我们得到如下结构的数据集:
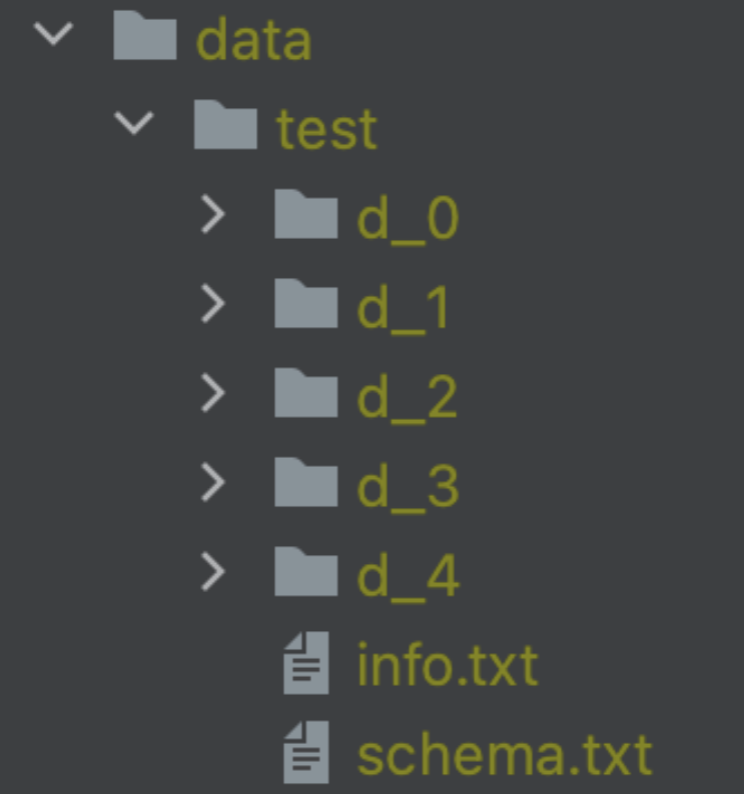
info.txt 文件是本数据集的相关配置信息,在后续执行数据集写入时会校验该配置是否与当前测试配置一致。如果不一致会拒绝写入,可以通过修改当前测试配置来完成写入。

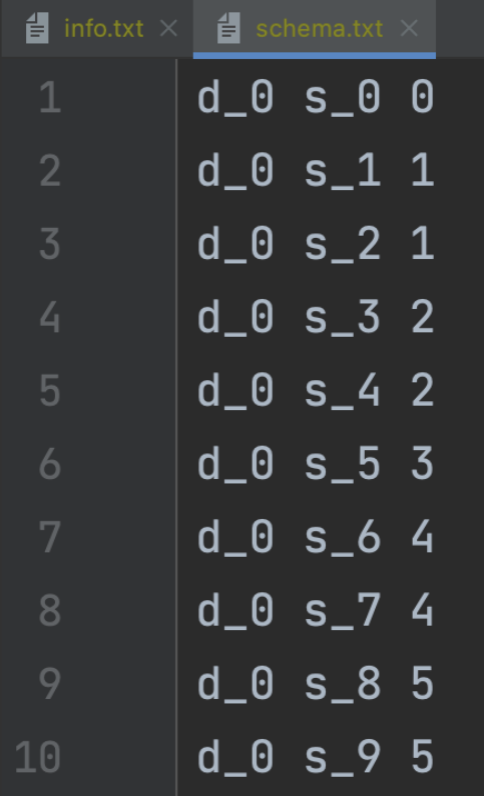
schema.txt 文件是本数据库的相关元数据配置,该文件每行包含设备名、传感器名和传感器类型,上述三个属性通过空格分隔开。其中,传感器类型0-5分别代表 BOOLEAN、INT32、INT64、FLOAT、DOUBLE、TEXT 类型。
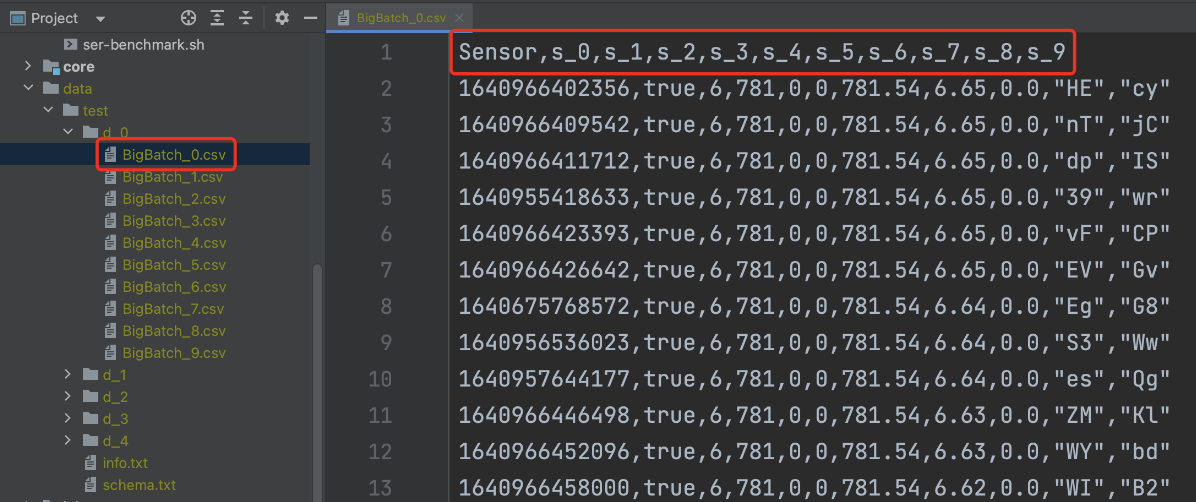
数据集内对应文件夹下的 csv 文件为本数据集的数据文件,每一个 csv 文件中包含 BIG_BATCH_SIZE 个 batch,每个 batch 均由 Sensor,s_0,s_1,s_2,s_3,s_4,s_5,s_6,s_7,s_8,s_9... 表头开始。
2. 写入生成的模拟数据集
在完成模拟数据集生成后,修改如下配置后执行模拟数据集写入并获取对应的统计结果:
1 | |
此外,还可以通过对生成的模拟数据集进行修改以满足更丰富的测试需求,只需要保证info.txt,schema.txt 和 具体的数据文件保持一致即可。
使用指南 | IoT Benchmark 生成模拟数据集和写入
https://spricoder.github.io/2024/01/20/Apache%20IoTDB/benchmark/%E4%BD%BF%E7%94%A8%E6%8C%87%E5%8D%97%20|%20IoT%20Benchmark%20%E7%94%9F%E6%88%90%E6%A8%A1%E6%8B%9F%E6%95%B0%E6%8D%AE%E9%9B%86%E5%92%8C%E5%86%99%E5%85%A5/