DDIA-Reading3-数据模型与查询语言
第二章:数据模型与查询语言
语言的边界就是思想的边界
1. 数据模型
- 对于每层数据模型的关键问题是:它是如何用低一层数据模型来表示的。
- 复杂的应用程序可能会有更多的中间层次,每层都会通过提供一个明确的数据模型来隐藏更低层次中的复杂性,这些抽象允许不同的人群有效地协作。
- 本章将比较关系模型、文档模型和少量基于图形的数据模型。
1.1. 关系模型与文档模型
关系模型(Edger Codd于1970年提出):数据被组织称关系(SQL中称为表),其中每个关系是元组(SQL中成为行)的无序集合。
- 目前最著名的数据模型可能就是SQL。
- 关系数据库主要是处理以下用例:
- 典型的事务处理:银行交易等
- 批处理:客户发票等
- 20世纪70年代和80年代初,网状模型和层次模型是主要选择,但是关系模型随后占据了主导地位。
1.2. NoSQL的诞生
NoSQL: Not only SQL
- 采用NoSQL数据库的背后的驱动因素:
- 需要比关系数据库更好的伸缩性:超大数据集和超高写入吞吐量。
- 相比商业数据库软件,免费和开源软件更受偏爱。
- 关系模型不能很好地支持一些特殊的查询操作。
- 受挫于关系模型的限制,渴望一种更具多动态性与表现力的数据模型。
- 关系数据库未来可能与各种非关系型数据库一起使用,被称为混合持久化(polyglot persistence)
1.3. 对象关系不匹配
- 目前大多数应用程序开发都使用面向对象的编程语言来开发,导致对SQL数据模型的普遍批评。
- 阻抗不匹配(Impedance mismatch):模型之间的不连贯。
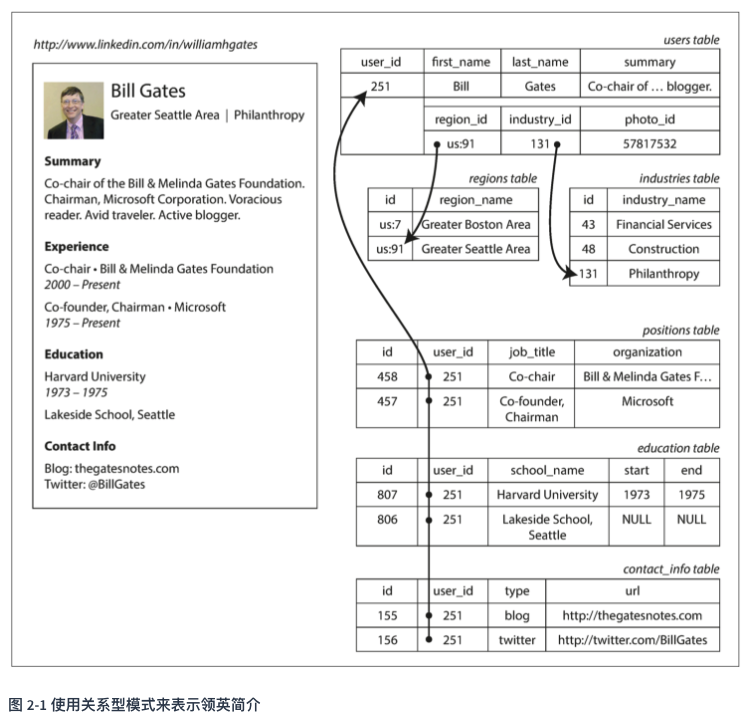
- 以领英为例,如何使用关系模式表示简历
- 传统SQL模型:将user_id作为外键。
- 将多值存储在单列:后续的SQL标准增加了对结构化数据类型和XML数据的支持。
- 将对应信息编码为固定格式的文档,存储在数据库的文本列:比如使用json格式表示,很多面向文档的数据库支持这种类型的数据模型。
1.4. 多对一和多对多关系
- 为什么
region_id是用ID的方式,而不是字符串的形式给出:- 保证样式和拼写统一
- 避免歧义:避免出现地名歧义问题
- 易于更新:避免出现不一致问题,数据的规范化
- 本地化支持:可以更标准化的替换
- 更好的搜索:匹配其他事实
- 在关系性数据库中,对连接的支持较强,但是在文档数据库中则相对比较弱。
- 更进一步:可以使用引用的方式,将对应的ID替换为一个指向,使用多对多关系扩展简历。
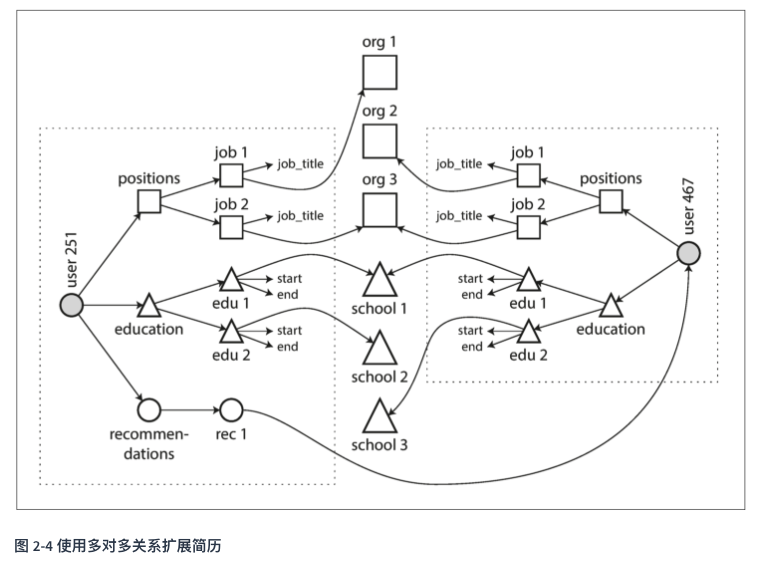
1.5. 文档数据库是否在重蹈覆辙?
如何以最佳的方式在数据库中表示多对多关系?
- 网状模型:最初很受关注,但最终变得冷门。
- 在层次模型的树结构中,每条记录只有一个父节点;在网状模型中,每个记录可能有多个父节点。
- 网状模型中记录之间的链接不是外键,而更像是编程语言中的指针。访问记录的唯一方法是跟随跟记录起沿这些链路所形成的路径(访问路径)。
- 网状模型会使得查询和更新数据库的代码变得非常复杂且不灵活。
- 关系模型:变成了SQL,并统治了世界。
- 一个关系(表)只是一个元组(行)的集合。
- 在关系数据库中,查询优化器来决定哪些部分以哪个顺序执行,以及使用哪些索引。这些选择实际上是"访问路径",但是是通过查询优化器自动生成的。
- 与文档数据库相比
- 在一个方面,文档数据库还原为层次模型。其父记录中存储嵌套记录,而不是在单独的表中。
- 另一个方面。在表示多对一和多对多关系时,关系数据库和文档数据库没有根本不同:相关项目都是通过一个唯一的标识符引用。
- 在关系数据库中,称为外键。
- 在文档数据库中,称为文档引用。
- 文档数据库没有在重蹈覆辙。
1.6. 关系型数据库与文档数据库在今日的对比
本章聚焦于数据模型中的差异。
- 哪种数据模型更有助于简化应用代码
- 如果应用程序有类似文档的结构,那么使用文档模型是合适的。
- 文档模型有一定的局限性:不能直接引用文档中嵌套的项目。
- 文档数据库对连接的糟糕支持未必是问题:需要结合业务代码。
- 文档模型中的模式灵活性:
- 是读时模式(Schema-on-read)
- 数据的结构是隐含的,只有在数据被读取时才被解释,类似于动态(运行时)类型检查。
- 适用于以下情况
- 存在许多不同类型的对象。
- 数据的结构由外部系统决定。
- 相应的是写时模式(Schema-on-write):传统的关系数据库方法中,模式明确),类似于静态(编译时)类型检查。
- 是读时模式(Schema-on-read)
- 比如目前存储了用户的全名,现在想要分别存储名字和姓氏
- 文档数据库:只需要开始写入具有新字段的新文档,并用代码来处理读取旧文档即可。
- "静态类型"数据库:需要使用
ALTER TABLE和UPDATE完成迁移- 模式变更更慢,而且要求停运。大多数关系数据库可以在几毫秒内完成
ALTER TABLE子句的执行,而MySQL是个例外(他会执行表复制) - 如果每一行的重写不可接受,那么可以设置默认值为
NULL,等到读取到的时候再更新。
- 模式变更更慢,而且要求停运。大多数关系数据库可以在几毫秒内完成
- 查询的数据局部性
- 文档通常以单个连续字符串形式进行存储。
- 如果应用程序经常需要访问整个文档,那么存储的局部性会带来性能优势;如果只访问文档的一部分,那么加载就比较浪费
- 更新文档时,需整个重写,因此建议保持相对较小的文档。
- 为了局部性而分组集合相关数据的想法并不局限于文档模型。
- 文档通常以单个连续字符串形式进行存储。
- 文档模型和关系数据库的融合。
- 许多数据库也开始对JSON文档提供了一定级别的支持。
- 关系模型和文档模型的融合是未来数据库一条很好的路线。
2. 数据查询语言
- 关系模型包含了一种查询数据的新方法
- SQL是一种声明式查询语言:只需要执行所需数据的模式,结果必须符合哪些条件,以及如何完成数据转换即可;并且更适合并行执行。
- IMS和CODASYL使用命令式代码来查询数据库:告诉计算机以特定顺序执行某些操作。
- Web上的声明式查询:使用
i.selected > p等方式来选择声明选择对象,从而避免复杂的代码和未来变更的影响。 - MapReduce查询:
- 介于声明式的查询语言,和完全命令式的查询API之间。
- 一些NoSQL数据库存储(包括mongodb)支持有限形式的MapReduce
- 具体例子
3. 图数据模型
- 一个图由两种对象组成
- 顶点(vertices),也称为节点(nodes),或实体(entities)
- 边(edges),也称为关系(relation),或弧(arcs)
- 典型例子:社交图谱、网络图谱等等
- 有几种不同的方法来构建和查询图中的数据
- 属性图模型(由Neo4j等实现)
- 三元组存储模型(由Datomic等实现)
- 三种查看图的声明式查询语言:Cypher、SPARQL、Datalog
3.1. 属性图模型
- 属性图模型
- 每个定点包括:唯一标识符、一组出边、一组入边、一组属性
- 每条边包括:唯一标识符、变得起点、变得重点、描述关系类型的标签、一组属性
- 也可以使用关系模型来表示属性图
- Cypher查询语言:为Neo4j图形数据库而发明
- SQL中的图查询:在使用关系模型表示的属性图中,也可以完成图查询,但是会比较复杂。
3.2. 三元组模型
- 三元组模型
- 所有数据都以简单的三部分表示形式存储(主语,谓语,宾语)
- 主语是图中的一个定点
- 宾语是原始数据类型的值或图中的另一个顶点。
- 语义网
- 三元组存储模型完全独立于语义网。
- 资源描述框架(RDF)目的是作为不同网站以统一的格式发布数据的一种机制,允许来自不同网站的数据自动合并成一个数据网络,一种互联网范围内的"通用语义数据库"
- SPARQL查询语言:一种用于三元组存储的面向RDF数据模型的查询语言。
4. 几个注意点
- 文档数据库的应用场景:数据通常是自我包含的,而且文档之间的关系非常稀少。
- 图数据库的应用场景:任何事物都可能与任何事物相关联
DDIA-Reading3-数据模型与查询语言
https://spricoder.github.io/2022/02/19/Designing-Data-Intensive-Applications-Reading/Designing-Data-Intensive-Applications-Reading3-%E6%95%B0%E6%8D%AE%E6%A8%A1%E5%9E%8B%E4%B8%8E%E6%9F%A5%E8%AF%A2%E8%AF%AD%E8%A8%80/