2021-服务端开发-Exam0-课程复习
Exam0-课程复习
1. 后端开发学习建议
- 至少精通一门编程语言,非常精通,不是能简单写几个程序,尽可能多学几门语言。
- 熟练掌握一门编程框架,如java的Spring,Python的Django,前端的Vue
- 会使用常用的工具,包括: IDE、Git
- 会使用静态检查工具,如java的Finbugs(分析类内部、类间和类与外部的问题)、PMD、CheckStyle(代码格式化)等IDEA插件或Maven插件
- 会单元测试工具,如java的JUnit、mockito、Coverage(覆盖率检查工具)、Cobertura
- 会使用构建工具,如java的Maven,常用的mvn插件
- 会使用数据库以及开发技术,MySQL是首选,其次用于测试的H2、SQLite也是需要的,另外ORM开发框架(mybatis、JPA等)也需要会一个
- 会使用多个功能和性能自动化测试工具,提醒你们的是无论你将来做开发还是做测试,多掌握几个自动化测试工具对你们是非常有用的。
- 其它的开发技术主是是以WEB开发、分布式(云计算)、大数据等为主要方向,能多学点,对你们将来也有利的。
- 最后就是软件工程的知识,你们要知道一个软件开发项目是如何运转的,需求怎么做、设计怎么做、什么才是好代码、应该怎么做测试、版本如何管理、缺陷如何管理等,还有敏捷的价值观、优秀实践(TDD、CI/CD等),这些知识也是必需的。
2. 第一节:概述
2.1. Spring是Java生态圈的主流编程框架
- 轻量级(Lightweight)
- 非侵入性(No intrusive)
- 容器(Container)
- 依赖注入(Dependency Injection)
- 面向切面编程(Aspect Oriented Programming)
- 持久层(JDBC封装、事务管理、ORM工具整合)
- Web框架(MVC、其它WEB框架整合)
- 其他企业服务的封装
2.2. Spring 的模块组成

2.3. 经典的基于Spring的典型Web分层架构示例
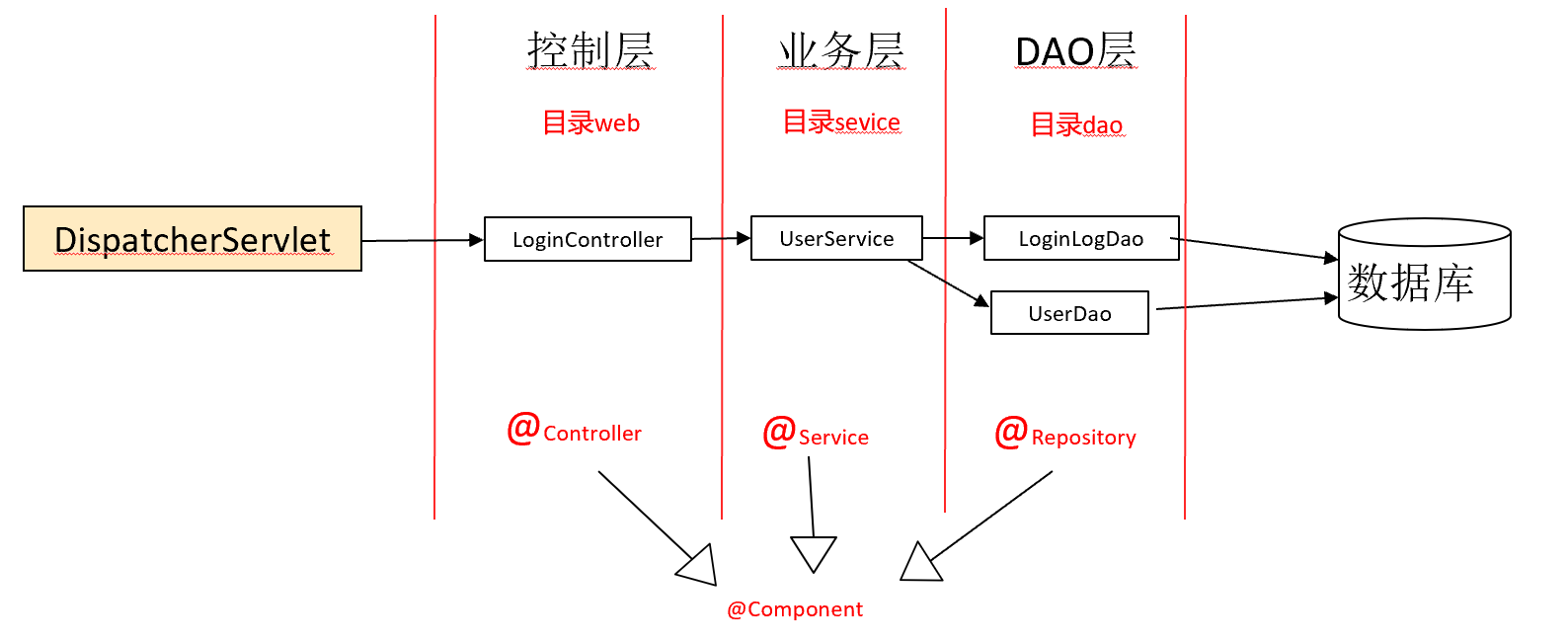
3. 第二节:依赖注入 —— Spring容器
3.1. Spring配置方案
- Spring框架负责创建对象和建立之间的关系
- 配置方法(告知Spring配置方案)
- XML:最早
- 自动化配置
- JavaConfig

- 创建上下文方式:
- Config文件 + 注解
- XML实现配置
3.2. auto(section2-1)
@componentScan:声明扫描包内的Component,进行对应的实例化。- 等价于:
<context:component-scan base-package="..."/> - 无参数:扫描当前文件所在包
- 有参数:
- 不安全的:({“包名”, “包名”})
- 类型安全:(basePackageClasses = xxx.class)表示扫描该类所在的包
- marked interface:保证类型的安全,同时保证类的重构不影响它,在这个类底下添加一个稳定的接口(标签接口)
- 等价于:
@component:告知框架,当前类需要实例化,等价于@Named@Autowired:自动装配(注入),可以放在构造函数、setter上,等价于@Inject- 构造对象的时候调用构造函数或者setter
- required参数:默认为true,可以修改为false表示允许该值为null
- 不必与
@Bean同时使用,加上@Bean的方法的参数可以自动注入 - 可能涉及到的POM配置文件如下
1 | |
- Spring的命名空间、XML文件配置法(
<context>:命名空间)
3.3. JavaConfig(section2-2)
- 没有
@Component,依靠在Config中编写,是基于Java的配置 @configuration:声明一个配置类,告知框架读取配置@Bean(name="xxx"):声明一个Bean,并且可以自定义名称- Bean的默认名称为方法名
- 可以通过name字段修改bean的名称
- 可以有多个
- Bean的实例个数
- 单实例(默认):默认情况下多次调用创建多实,默认在一个容器里面。
- 多实例
- 使用
@Scope进行修改:Scope,也称作用域,在Spring IoC容器是指其创建的 Bean 对象相对于其他 Bean 对象的请求可见范围。在 Spring IoC 容器中具有以下几种作用域:- 基本作用域:
singleton表示在spring容器中的单例,通过spring容器获得该bean时总是返回唯一的实例prototype表示每次获得bean都会生成一个新的对象(多实例)
- Web作用域
request表示在一次http请求内有效(只适用于web应用)session表示在一个用户会话内有效(只适用于web应用)- 会话建立时创建Bean,会话结束后销毁Bean
- Session Client和Server之间的一个Session,不同Client可能和Server建立多个Session,Request是一次请求和处理
globalSession表示在全局会话内有效(只适用于web应用):请求开始时创建Bean,请求结束后销毁Bean
- 自定义作用域
- 基本作用域:
1 | |
- 一般情况下配置类和业务类会分包存储。
3.4. XML(section2-3)
- bean:
<bean id = "bean_name">- 不能进行类型检查
- 有构造函数参数(构造器注入)
- 元素:每个参数一条
- 引用:
<constructor-arg ref="对象名"> - 值:
<constructor-arg value ="参数内容、字面常量">
- 引用:
- 属性:
- c-命名空间
- 建议按顺序取:编译结束后名称就已经不存在了
- 注入具体值
- 指定字面量值:(
<null/>表示null) - 指定集合:
<list>和<set>,中间的值为<value>xxx</value>
- 指定字面量值:(
- 元素:每个参数一条
- 属性方式注入(p name)
- set方式名字和properties name保持一致
- p命名空间不支持list
<util: list id>可以存放多项,然后p引用该util(util命名空间)
1 | |
- xml文件名和测试类的名字一样,就不需要在测试的上下文配置中指定。
- 强依赖建议使用构造器注入
3.5. 混合(section2-4)
- 混合配置:
- JavaConfig:类型检查简单
@Import(配置类.class, xxx)@ImportResource(xml文件)
- xml:导入、.class文件不用调整
- JavaConfig:类型检查简单
- 配置文件(java 和 xml)里面可以import别人
<import resource = "xml文件"/><bean class = "配置类"/>
- import可以import多个:xml里面,配置类写过的可以不仔细写
3.6. 控制容器实例化
3.6.1. @Profile
@Profile:不同情况下使用不同的bean,使用profile来控制,还可以使用Spring Boot的属性文件命名(含后缀)devprod
- 激活:激活的方式使用激活的三种方式。Spring Boot在java –jar时,使用-Dspring.profiles.active =sys会读取application-sys.properties文件来完成配置。如果没有添加profile则会帮你实例化出来(无论是否有profile的别的)
spring.profiles.default="dev"spring.profiles.active="prod"@ActiveProfiles("dev")
1 | |
3.6.2. @Conditional
- Conditional的**.class实现了Condition接口,自己决定什么时候创建这个Bean,什么时候不创建这个Bean
1 | |
3.6.3. 自动装配的歧义性
@Component或@Bean@Primary- 定义时
@Componet或@Bean@Qualifier("...")自定义限定符,通过使用@Qualifier注解,我们可以消除需要注入哪个bean的问题。
- 使用时
@Autowired@Qualifier("…")bean名称或自定义限定符,默认Bean名是限定符
- Spring 注解 @Qualifier 详细解析
- 可以自定义注解,这些注解本身也加了@Qualifier注解
@Cold@Creamy
1 | |
3.6.4. 通过代理注入给单例对象

1 | |
4. 面向切面编程 AOP
4.1. 概述
- AOP:Aspect Oriented Programming
- 发展史:
- POP:面向过程编程
- OOP:面向对象编程
- AOP:面向切面编程
- FP:函数式编程
- Rx:反应式编程(Java 9、Spring 5)
4.2. 概念
- 横切关注点:切入的代码的功能或者关注点,业务代码不关注这部分点
- 日志
- 安全
- 事务
- 缓存
- 通知(Advice):切面做什么?什么时候做?代表了切面的逻辑。
- 切点(Pointcut):指定通知存放的位置,定义要改的方法和参数。
- 切面(Aspect):通知 + 切点
- 连接点:通知 + 切点的实例化:也就是和业务代码连接的地方
- 引入(Introduction):(给对象)引入新的行为和状态
- 织入(weaving):切面应用到目标对象的过程
4.2.1. 通知类型
@Before:在调用目标之前@After:被切的对象方法执行之后,等于@AfterReturnning+@AfterThrowing@AfterReturning:被切对象方法返回后,有异常但是没有return的话不执行AfterReturning@AfterThrowing:被切对象方法出现异常之后@Around:被切对象方法的执行前和执行后,等于@Before+@After
4.2.2. 织入的时机
- 编译器:编译的时候将Aspect织入进去,需要使用特别的编译器。
- 类加载期:Spring不支持
- 运行期(Spring 织入):使用代理对象,就是获得的是切面对象的代理对象的引用,通过代理来操作,只支持方法级别的连接点
4.2.3. Spring AOP的两种支持类型
@ApectJ注解驱动的切面- 切面表达式:表达切点
- 流程:写
@Aspect->配置Config完成实例化和代理配置 - 多参数
- 语法:
- 对参数不感兴趣:√
- 对返回值或方法名不感兴趣:×
- 参考
1 | |
- 纯POJO切面:通过XML而不是Spring注解,解决:比如想要将第三方无源码代码织入。
- 开启AspectJ的自动代理机制:
@EnableAspectJAutoProxy
4.2.4. 引入新功能
@DeclareParents:使用代理的方式为原类增加新方法,参考- main 和 测试
4.2.5. XML中声明切面
- 前置和后置通知
<aop:pointcut>- 声明环绕通知
- 传参数,测试
- 引入新功能
5. Web
5.1. 软件系统结构(C/S B/S)
- C/S(Client):客户机和服务器(有客户端,相当于安装软件)
- B/S(Browser):浏览器和服务器

5.2. 分层结构
- 控制层:Controller
- 业务层:Service(业务逻辑)
- 持久化层(DAO):repository(数据库访问)
- view层
- model层
- domain层(领域层):把Java对象对应到数据库里的表
5.3. Spring MVC请求
- 第一步:携带有URL和表单信息的Request达到DispatchServlet
- 第二步:DispatchServlet去Handler mapping中查找映射关系
- 第三步:根据查找到的映射关系,将Request交给具体对应的Controller
- 第四步:Controller得到携带的URL和表单信息等,在交给业务层处理后,得到业务层返回的Model和logical的视图名
- 第五步:DispatchServlet得到对应的model和logical view name(str),并向ViewResolver根据名称查找界面
- 第六步:DispatchServlet得到查找到的View界面
- 第七步:将View放置在Response中返回给客户端

5.4. DispatchServlet的配置
- Servlet3规范
- 使用Java将DispatchServlet配置到Servlet容器中
- 自定义DispatchServlet需要实现WebApplicationInitializer接口,或其实现接口
AbstractAnnotationConfigDispatcherServletInitializer实现了WebApplicationInitializer接口- DispatcherServlet加载的应用上下文:
getServletConfigClasses,装载Web组件:控制器、视图解析器、处理器映射 - ContextLoaderListerner加载的应用上下文:
getRootConfigClasses,装载其它Bean
- DispatcherServlet加载的应用上下文:
5.5. 常见的上下文文件
- web.xml
- applicationContext.xml
- 相对比较传统
5.6. 启用Spring MVC组件
- 注解
@EnableWebMvc - 配置视图解析器
- 启动组件扫描
- 排除静态资源的请求
5.7. 检验表单
- Java检验API(Java Validation API)
@NotNull@Size@Valid
- 检查回调结果
1 | |
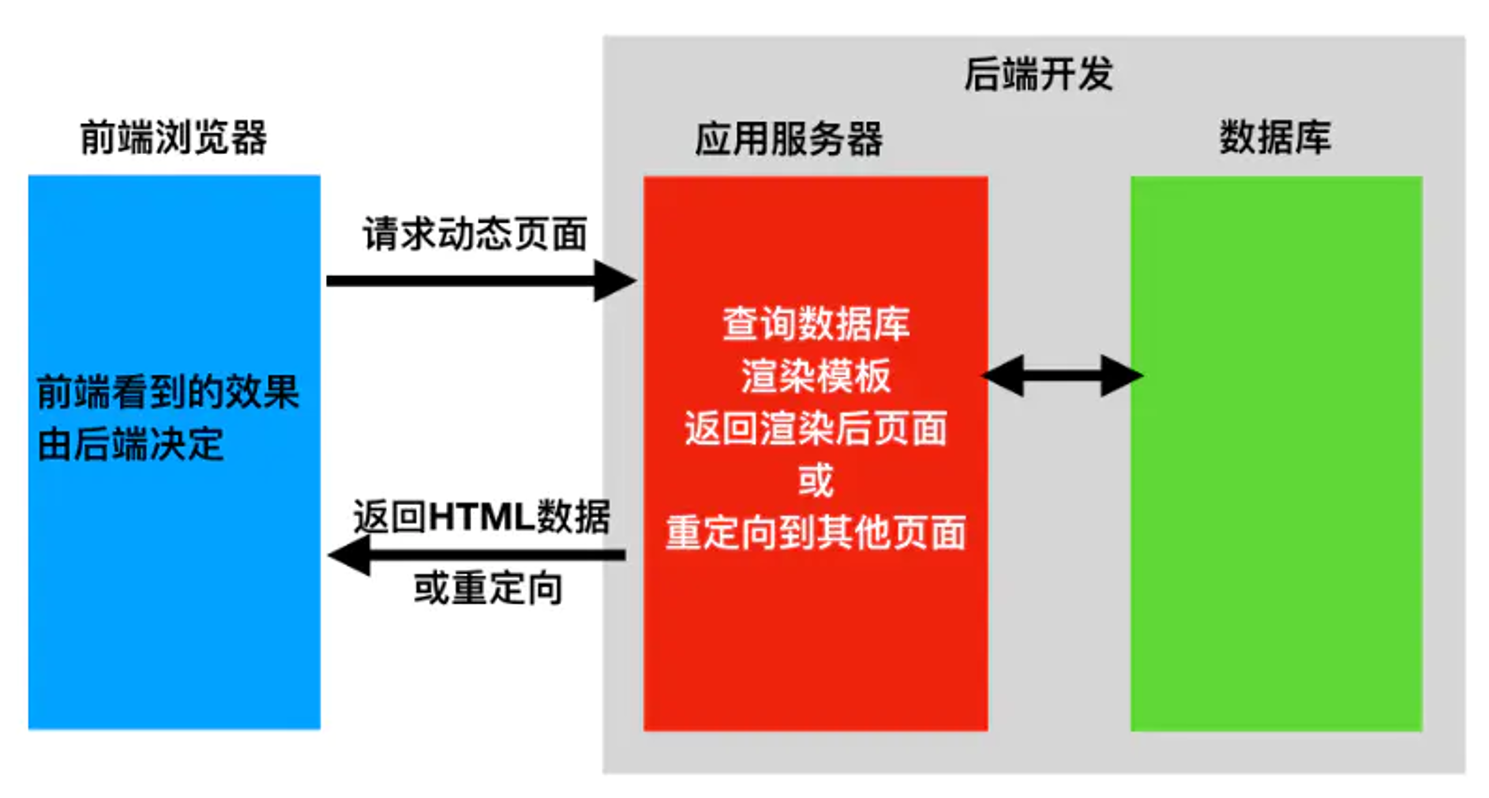
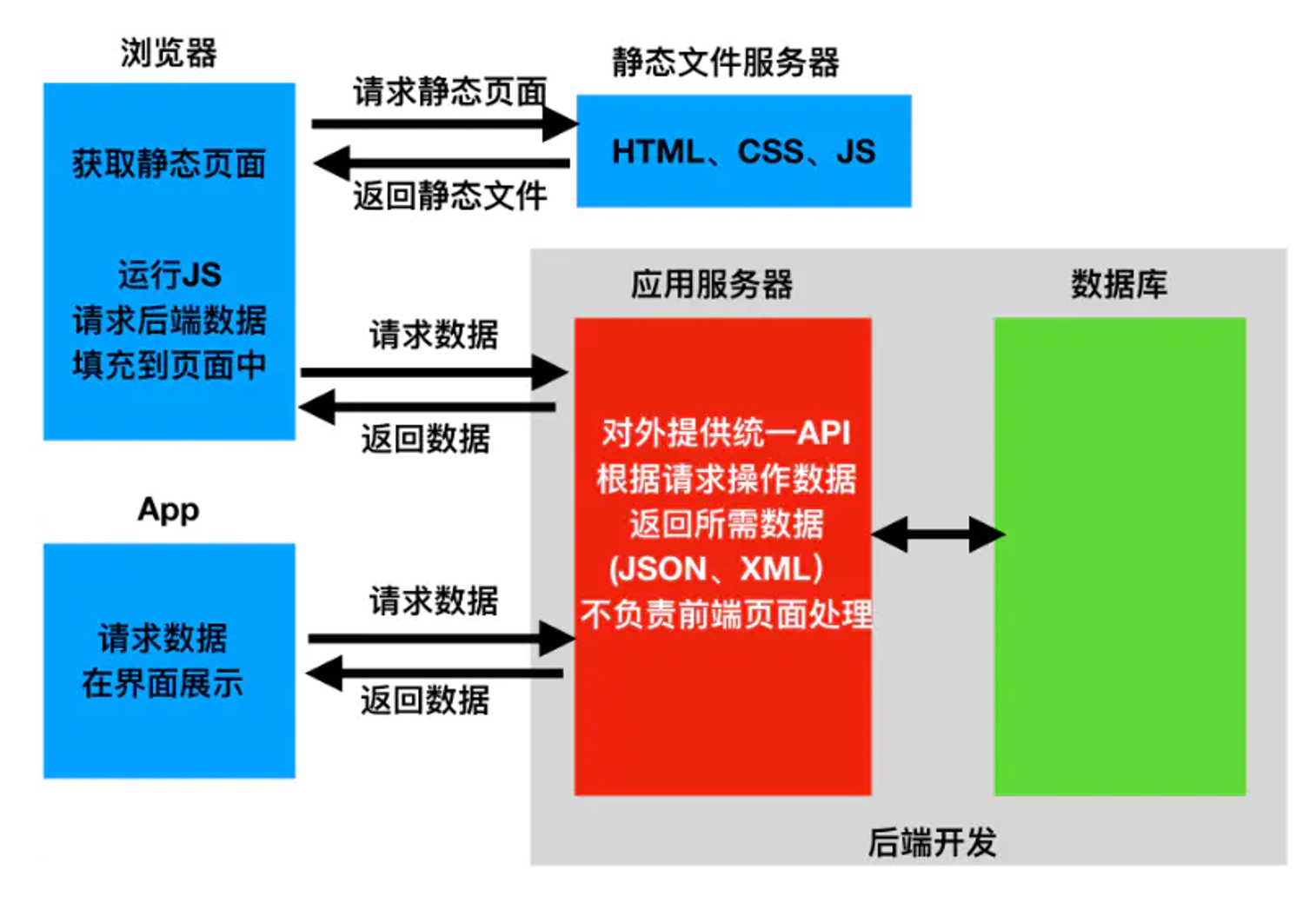
5.8. 前后端分离和前后端不分离
| 前后端不分离 | 前后端分离 |
|---|---|
 |
 |
5.9. 文件上传
AbstractAnnotationConfigDispatcherServletInitializer中需要配置registration.setMultipartConfig(new MultipartConfigElement)WebMvcConfigurerAdapter中需要配置StandardServletMultipartResolver- 控制器:
@RequestPart("file") MultipartFile file - 页面指定表单格式:
multipart/form-data
5.10. 异常处理
- 抛出异常与响应状态关联
1 | |
- 异常与响应页面的关联
1 | |
- 为控制器添加通知
1 | |
- 跨重定向请求传递数据:自学7章
6. 第五章:Spring Security
6.1. 过滤web请求
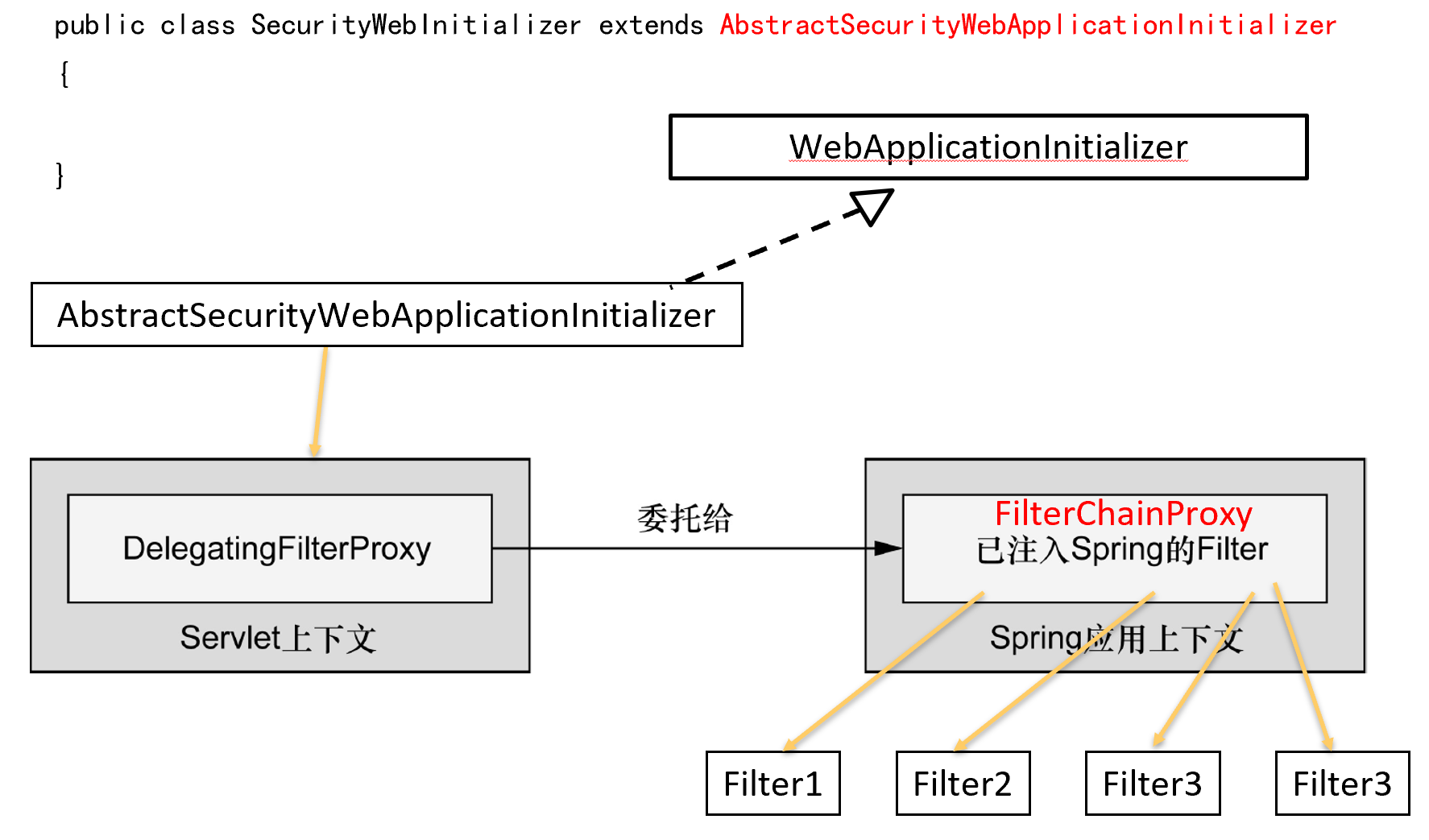
- 新开了一个WebApplicationInitializer实现,用于拦截请求
另一个WebApplicationInitializer是AbstractAnnotationConfigDispatcherServletInitializer(仅负责DispatcherServlet的初始化)
这两个同时存在
6.2. 安全配置
1 | |
@EnableWebMvcSecurity相比于@EnableWebSecurity,增加:@AutthenticationPrincipal注解的参数解析,获得用户名- 增加一个bean,页面自动添加CSRF token输入域
- 注意SecurityConfig与SecurityWebInitializer是两个不同的类
6.3. 拦截请求
- 使用HTTPS安全通道
- 防止跨站请求伪造,cross-site request forgery,CSRF
- 默认开启
- 关闭:.csrf().disable()
- 登录页面
- formLogin
- loginPage
- 启用HTTP Basic认证
- httpBasic()
- 关于Cookie
- 启用Remember-me功能
- rememberMe()
- 退出
- Filter自动拦截/logout请求
- 重定向
6.4. 建立HTTPS安全通道
- 访问链接
- 总结来说就是服务端tomcat要配keystore,里面也有客户端的证书,客户端windows系统里也要有客户端证书,服务端证书ca。
1 | |
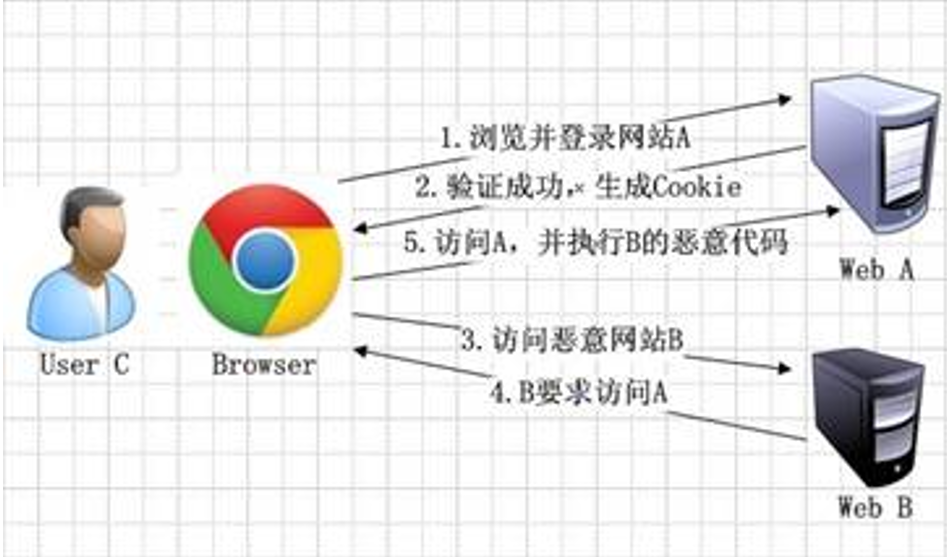
6.5. CSRF攻击
6.6. 保护视图
- JSP标签库
- Thymeleaf方言:
templateEngine.addDialect(new SpringSecurityDialect());,pom依赖如下
1 | |
6.7. 保护方法的配置
1 | |
@EnableGlobalMethodSecurity(securedEnabled=true)应该可以放到WebSecurityConfigurerAdapter- 就是
WebSecurityConfigurerAdapter与GlobalMethodSecurityConfiguration合二为一 - 这样请求拦截和方法保护同时有效
6.8. 三种安全注解
- spring自带注解
@Secured({"ROLE_SPITTER", "ROLE_ADMIN"})securedEnabled=true
- JSR-250
@RolesAllowed("ROLE_SPITTER")jsr250Enabled=true
- 表达式驱动的注解
@PreAuthorize("(hasRole('ROLE_SPITTER') and #spittle.text.length() le 140) or hasRole('ROLE_PREMIUM')")@PostAuthorize@PreFilter@PostFilterprePostEnabled=true
7. 第六章:ORM与Hibernate、JPA编程
7.1. ORM
- ORM:对象关系映射(Object-Relational-Mapping),在Java对象和关系型数据库之间的映射,实现直接存取Java对象,只是一套规范
- 在Java对象与关系数据库之间建立某种映射,以实现直接存取Java对象;不必编写RowMapper,不用关系对象是如何获得的,也不用担心一对多等问题
- 具体实现
- Hibernate、MyBatis
- JPA (Java Persistence API)
7.2. Hibernate
7.2.1. Hibernate配置
- org.hibernate.Session接口
- 获取org.hibernate.SessionFactory对象:org.springframework.orm.hibernate4.LocalSessionFactoryBean
- 定义映射关系:XML、注解(JPA、Hibernate)
7.2.2. Hibernate的三类查询
- HQL(Hibernate Query Language):即Hibernate提供的面向对象的查询语言
- select/update/delete
- from
- where
- group by
- having
- order by
- asc/desc
- QBC(Query By Criteria):完全面向对象的查询
- 本地SQL
7.3. @Repository注解
- 类似于
@Component - 转换成Spring的统一异常,实现持久化异常转换的Bean
1 | |
7.4. JPA Java Persistence API
- JPA: Java持久化 API,为POJO提供持久化标准规范
- JPQL(Java Persistence Query Language):类似SQL
- JPQL就是一种查询语言,具有与SQL相类似的特征
- 参考
7.4.1. JPA配置
- javax.persistence.EntityManager:类似于Hibernate的Session
- 实体管理器工厂(Entity Manager Factory)
- org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean
- org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter
- 并不真正注入EntityManager
- 线程不安全,每次操作前创造一个
@PersistenceUnit:每个EntityManager负责将固定数量的一组类映射到数据库中,这组类就被称做persistence unit。Persistence unit是在persistence.xml中定义的。根据Java Persistence规范的要求,该部署描述文件是必需的。一个persistence.xml文件可以定义一个或多个persistence unit,它一般都会放置在META-INF目录中。@PersistenceContext:称为持久化上下文,它一般包含有当前事务范围内的,被管理的实体对象(Entity)的数据。每个EntityManager,都会跟一个PersistenceContext相关联。PersistenceContext中存储的是实体对象的数据,而关系数据库中存储的是记录。
- 应用程序管理类型:LocalEntityManagerFactoryBean persistence.xml配置持久化单元、数据源
- 容器管理类型:LocalContainerEntityManagerFactoryBean adapter背后可以有不同厂家的JPA实现
- pom依赖
1 | |
- JPA配置
- 加注解
@EnableJpaRepositories:会扫描org.springframework.data.repository.Repository接口 - 继承接口
org.springframework.data.jpa.repository.JpaRepository - 可以继承
org.springframework.data.repository. CrudRepository:包含18个方法
- 加注解
7.4.2. 编写自定义的查询方法
- 定义查询方法,无需实现
- 领域特定语言(domain-specific language,DSL),spring data的命名约定
- 查询动词 + 主题 + 断言
- 查询动词:get、read、find、count
- 声明自定义查询
- 不符合方法命名约定时,或者命名太长时
@Query("select ...")
- 使用EntityManager直接低层实现:接口名+Impl的实现类
7.5. JPA、Hibernate、Spring Data JPA三者之间的关系
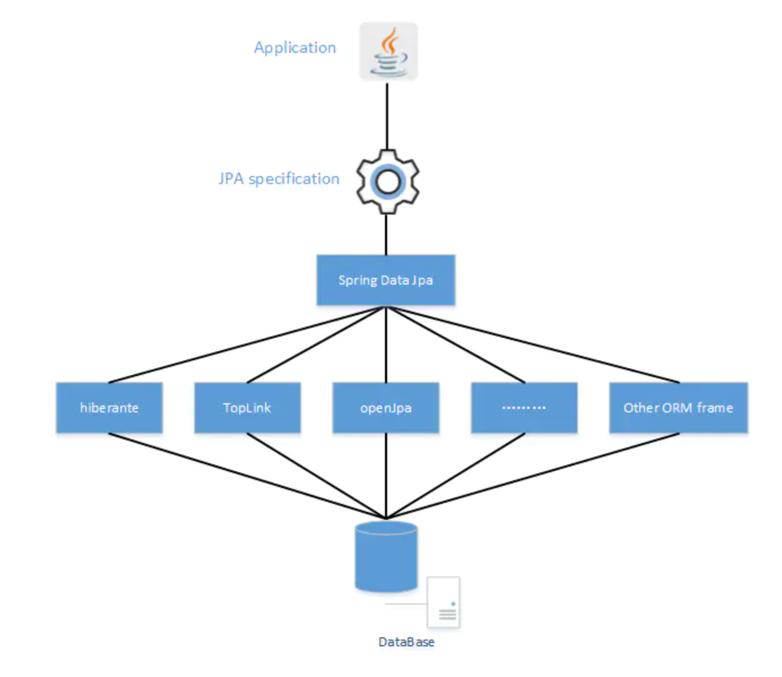
7.6. 例子:在Spring Boot开发中使用MyBatis
application-xxx.yml中的配置- 配置数据源
- mapper-locations指定mapper文件地址
1 | |
- 定义接口(使用注解
@Mapper) - 映射文件地址:
classpath:mapper/***Mapper.xml
7.7. JDBC
- 业务访问与持久化解耦
- 数据访问对象(DAO)或者Repository
- 业务对象 -> Repository接口 <- Repository实现(依赖倒置)
- 异常处理:SQLException
- 非"运行时异常",注意catch
- 链接断开、语法有误会导致这个异常
- 难以恢复、难以确定类型
- Spring:把异常变成运行时的DataAccessException(平台无关,让DAO层的异常不会被业务层直接发现)
- 模板方法模式:定义过程的主要框架,template
- 资源管理
- 事务控制
- 异常管理
- 配置数据源方法
- JNDI数据源:Java命名与目录接口
- Web容器(比如Tomcat)中配置JNDI参数,定义一个数据源(XML文件方式)
- 以Tomcat为例:在conf目录下的server.xml
- 驱动程序放到lib里面。
- 直接在Spring里面使用连接池化处理
- 很多第三方软件可以重用
- 可以在Java里或XML配置
- DBCP
- Spring 提供:JDBC驱动
- DriverManagerDataSource:没有连接池
- SingleConnectionDataSource:只有一个连接
- 开发或测试使用
- 用Spring配置嵌入式数据源:
<jdbc: >
- JNDI数据源:Java命名与目录接口
@Profile("dev"):配置环境,用来决定不同环境下选择哪一个进行实例化@ActiveProfile:指定当前环境- 不改变源代码
- RowMapper的接口的实现:lamada表达式负责将数据库字段映射到java对象的属性
- 持续交付-部署流水线:共用一套测试版本,加入到制品库后的东西不能够重新编译添加。
8. 第八章:非关系型数据库和编程
- MongoDB:文档式的存储。
- Redis:集群间的数据共享、缓存。
- 非关系型数据库不要求定义Schema,存储方式可以是多种多样的。
8.1. NoSQL
- NoSQL(Not Only SQL):指非关系型的数据库
- 没有声明性查询语言
- 没有预定义的模式
- 键-值对存储、列存储、文档存储、图形数据库
| 命令 | 解释 |
|---|---|
| db.help() | help on db methods |
| db.mycoll.help() | help on collection methods |
| sh.help() | sharding helpers |
| rs.help() | replica set helpers |
| help admin | administrative help |
| help connect | connecting to a db help |
| help keys | key shortcuts |
| help misc | misc things to know |
| help mr | mapreduce |
| show dbs | show database names |
| show collections | show collections in current database |
| show users | show users in current database |
| show profile | show most recent system.profile entries with time >= 1ms |
| show logs | show the accessible logger names |
| show log [name] | prints out the last segment of log in memory, ‘global’ is default |
use <db_name> |
set current database |
| db.foo.find() | list objects in collection foo |
| db.foo.find( { a : 1 } ) | list objects in foo where a == 1 |
| it | result of the last line evaluated; use to further iterate |
| DBQuery.shellBatchSize = x | set default number of items to display on shell |
| exit | quit the mongo shell |
8.2. MongoDB
8.2.1. 简介
- C++编写,基于分布式文件存储的开源数据库系统
- 文档存储一般采用JSON格式
- 存储的内容是文档型,保证了有机会对某些字段创建索引
- 里面的对象自带时间属性
1 | |
- MongoDB Shell是它自带的Shell,Js的Shell,可以在里面敲JS
- 术语:
database=databasecollection=tabledocument=rowfield=column- 同一个Collection中的Document的Field可以不相同
- 文档:
- 一次记录中有多个对象,要用另一张表Join,但是Mongo里可以存在一起
- 嵌套
.pretty()显示的更格式化更好看
8.2.2. 编程
- 基于JDBC驱动:启动一个MongoDB的Client,获得DataBase,数据库操作,Close,和Spring本身没有关系
1 | |
- 推荐工具:Java-Faker
- Spring Data MongoDB
- 需要添加Spring Data的依赖,包含类的时候可以直接存储
- 数据结构的定义注解是
@Document,当前的数据类作为一个Document @MongoRepository:带参数、类名和ID类型。@Query(json):筛选条件- save会将class字段自动添加进入
- 不同插入方式的效率问题
- Java-Faker:构造数据使用(需要添加依赖)
- JDBC快:Spring Data插进去了更多的字段
8.3. Redis
8.3.1. 简介
- key-value的Hash结构,存的是数据结构
- key-value是大小写。
- 可以指定key的消亡时间。
- 内存数据库(缓存)
- 可以做集群部署,master-slave结构,写给master,然后由master复制给slave们
- 集群环境下事务的处理
- 集群环境下Message的处理、消息队列
- key-value可以区分大小写。
- 可以查看数据类型
- string:如果发现是数值类型也可以做数值计算
- list:链表,往left或者right插入
- 可以阻塞等待,设置等待时间
- push和pop
- 阻塞等待:BRPOP和BLPOP
- hash:
hm set key - set
8.3.2. 编程
- 连接Redis:
- 需要客户端连接
- 创建连接工厂(RedisConnectionFactory),提供Template模板(RedisTemplate、StringRedisTemplate),Factory不指定则使用默认的连接(6379端口)
- 要实现一个序列化接口
- 不推荐使用基于Java的序列化(字节序列)
- 比如换成jackson、json格式等
- RedisTemplate的子API
- 使用简单的值:opsForValue() - ValueOperations,set、get
- 使用List类型的值:opsForList() - ListOperations:rightPush、leftPop、range
- 在Set上执行操作
- opsForSet() - SetOperations
- add、difference、union、intersect
- 绑定到某个key上:boundListOps(“cart”)
- 指定序列化器
- 默认处理:JdkSerializationRedisSerializer
- StringRedisSerializer
- Jackson2JsonRedisSerializer
9. 第九章:缓存编程
9.1. 概述
- 添加一层缓存,常用到的数据可以不从数据库中查找
- 启用缓存
@各种注解,在Repository层的接口中添加- 配置类里面添加
@EnableCaching - 缓存管理器:Spring默认提供(org.springframework.cache.CacheManager),但是一般用第三方
- 利用AOP机制,在方法前后进行处理。
9.2. 缓存实现
- (原生的)定义一个Bean,返回一个ConcurrentCacheManager
- org.springframework.cache.concurrent.ConcurrentMapCacheManager
- CacheEvict:从缓存中也删除。
- EhCache:速度比较快
- org.springframework.cache.ehcache.EhCacheCacheManager
- 和程序运行在同一个进程内,提供一些额外的功能。
- RedisCache:分布式
- org.springframework.data.redis.cache.RedisCacheManager
- 3个Bean:模板、工厂、Manager
- 本地需要启动Redis
9.3. EhCache
- 概念:
- CacheManager:Cache的容器对象,并管理着(添加或删除)Cache的生命周期。
- Cache:一个可以包含多个Element,由CacheManager管理,实现缓存的逻辑。
- Element:需要缓存的元素,维护键值对,可以设置有效期(0代表无限制),可以包含多个信息。
- 初始化Manager的时候需要XML配置,需要引入pom的引入,使用XML进行配置(XML中包含了每个Cache的配置)
- 使用Spring:
- import EhCache的包
- 使用工厂来完成实例化
9.3.1. 自定义缓存配置
- name : 缓存的名称,可以通过指定名称获取指定的某个Cache对象
- maxElementsInMemory :内存中允许存储的最大的元素个数,0代表无限个
- clearOnFlush:内存数量最大时是否清除
- eternal :设置缓存中对象是否为永久的,如果是,超时设置将被忽略,对象从不过期。
- timeToIdleSeconds : 设置对象在失效前的允许闲置时间(单位:秒)
- timeToLiveSeconds :缓存数据的生存时间(TTL)
- overflowToDisk :内存不足时,是否启用磁盘缓存
- maxEntriesLocalDisk:当内存中对象数量达到maxElementsInMemory时,Ehcache将会对象写到磁盘中。maxElementsOnDisk:硬盘最大缓存个数
- diskSpoolBufferSizeMB:这个参数设置DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区
- diskPersistent:是否在VM重启时存储硬盘的缓存数据。默认值是false
- memoryStoreEvictionPolicy:如果内存中数据超过内存限制,向磁盘缓存时的策略。默认值LRU,可选FIFO、LFU。
9.3.2. Spring 与 EhCache的集成
- pom依赖配置
1 | |
- 配置CacheManager
1 | |
9.3.3. Spring 与 Redis 集成
- pom依赖
1 | |
- 配置CacheManager
1 | |
9.4. 缓存注解
@Cacheable:先去缓存中查找,如果没有找到则去数据库中查找,并将结构缓存,参数是Cache的名字- condition:缓存条件,可以禁用缓存
- unless:阻止引入
@CachePut:在数据库中粗出后将结果放入到缓存,而不会进数据库中找@CacheEvict:从Cache中删除,beforeInvocation,调方法之前就删除
9.5. 自定义缓存Key
- SpEL表达式中的元数据
- #result:结果对象
- #Argument:参数对象
- 可以指定,使用元数据
- 条件化缓存
- 属性condition 禁用缓存
- 属性unless 阻止将对象放进缓存
10. 第十章:Docker
10.1. 容器与虚机

10.2. Docker 组成
- 容器是在Linux内核实现的轻量级隔离机制
- 虚拟机是操作系统级别的资源隔离
- 容器本质上是进程级的资源隔离,是共用主机内核,利用内核的虚拟化技术隔离出一个独立的运行环境,拥有独立的一个文件系统、网络空间和进程空间视图
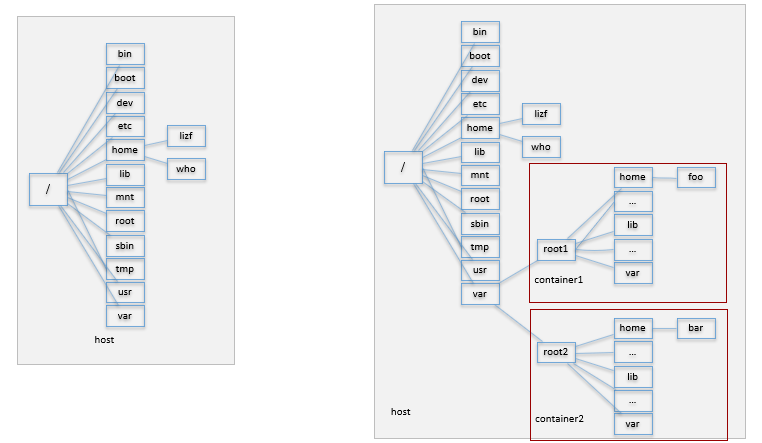
- 组成
- Docker Daemon(Docker Engine):一般在宿主主机后台运行
- 用户使用Client和Engine(Daemon)交互,可以通过pip、unix socket、tcp进行交互
- Docker Index指向Docker registries,也叫Docker仓库,也叫做Docker仓库,可以用来上传和下载images,官方docker仓库:Hub.docker.com
- 使用GO语言实现
10.3. 虚拟机与容器
- 从虚拟化层看容器,轻量级、高性能是核心价值:虚拟机 vs 容器
- 容器是在Linux内核实现的轻量级资源隔离机制
- 虚拟机是操作系统级别的资源隔离,容器本质上是进程级的资源隔离
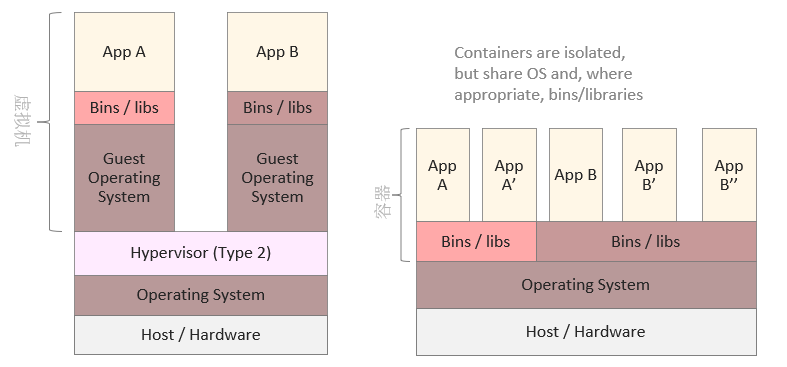
10.4. 使用
- run
- -d:后台运行容器,并返回容器ID
- -i:以交互模式运行容器,通常与-t同时使用
- -t:为容器重新分配一个伪输入终端,通常与-i同时使用
- -p:指定(发布)端口映射,格式(主机(宿主)端口:容器端口)
- -P:随机端口映射,容器内部端口随机映射到主机的高端口
- –name = “docker_name”:为容器指定一个名称
- -e env=“value”:设置环境变量
- –env-file=“filename”:从指定文件中读入环境变量
- –expose=2000-2002:开放(暴露)一个端口或一组端口
- –link container_name:tag_name:添加链接到另一个容器,对于某个容器,跑的时候给要连接的另一个容器添加一个名字,就可以把那个容器映射到当前容器里
- -v path_name:绑定一个卷(volumn)
- –rm:退出时自动删除容器
- container
docker container lsdocker container ls -adocker container ls -aqdocker inspect容器名:显示容器信息docker port容器名:显示端口映射信息docker logs -f <contioner id>查看容器内部的标准输出docker stop <container id>停止一个容器docker start <container id>启动已停止运行的容器docker restart <container id>正在运行的容器可以重启docker attach <container id>附着到容器docker exec -it <container id>/bin/bash 进入容器,执行命令docker rm -f <container id>删除容器docker container prue:清理掉所有处于终止状态的容器
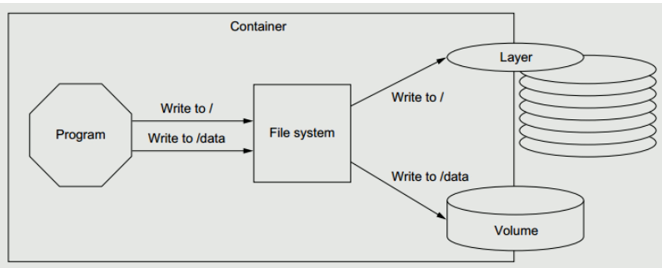
10.5. Volumn
- 镜像分层
- 镜像顶层可读写,底层不可写
- 写时复制:如果需要进行读写,进行提升

- 数据卷(volume:Docker管理宿主机文件系统的一部分,默认位于/var/lib/docker/volumns目录中)
- Docker 管理卷:
docker volumn 命令 - 绑定挂载卷:
-v,挂载到容器内 - bind mounts:意味着可以存储在宿主机系统的任意位置
- tmpfs:挂载存储在宿主机系统的内存中
- Docker 管理卷:
1 | |
10.6. 导出和导入容器镜像
1 | |
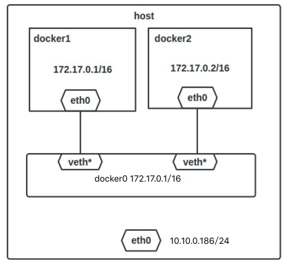
10.7. 容器网络
docker bridge:所有的容器都联通到桥上,彼此间就可以连通。- 桥有自己的网关,可以路由到虚拟机的网卡上,虚拟机又可以路由到外面的宿主机
- 两个虚拟机之间可以用overlay打通。
- 不建议挂载bridge上,因为需要
--link才能彼此连通。
- 容器网络
- none网络,–net=none
- host网络,–net=host
- bridge网络,–net=bridge,docker0 的 linux bridge
- container模式,–net=container:NAME_or_ID
host:容器本身没有网卡,使用的是宿主机的网络。- 使用自己创建的网络
- 同一个网络下的各个容器,可以通过容器名直接连通
- 也可以到达虚拟机的网卡,连接宿主机
- 自己创建的网络和真实的网络是一样的
- 一个容器可以有多个网卡(IP地址)
1 | |
11. 微服务
11.1. 单体 VS 微服务
- 单体应用程序
- 数据库的表对所有模块可见
- 一个人的修改整个应用都要重新构建、测试、部署
- 整体复制分布式部署,不能拆分按需部署
- 微服务
- 应用程序分解为具有明确定义了职责范围的细粒度组件
- 完全独立部署、独立测试,并且可以服用
- 使用轻量级通信协议(HTTP和JSON),松耦合
- 服务实现可使用多种编程语言和技术
- 将大型团队划分成多个小型开发团队,每个团队只负责他们各自的服务。
11.2. 开发技术
- 针对Java开发:Spring Boot和Spring Cloud
- Spring Boot:拿到开发具体的微服务,面向REST的微服务框架
- Spring Cloud:解决实施和部署微服务到私有云和公有云的问题。
- REST原则:表现层状态转化(Representational State Transfer)
- 资源(Resources):网络上的一个实体,比如图、文档等等,标识为URI
- 表现层(Representation):可以认为是View,展现资源
- 状态转化(State Transgfer):服务端 —— 客户端
- HTTP协议的四个操作动词:Get、Post、Put、Delete
- CRUD:Create Read Update Delete
- 如果一个架构符合REST原则,就称它为RESTful架构
11.3. 客户端与服务的交互
11.3.1. 请求头与请求体
- 请求头:请求头由 key/value 对组成,每行为一对,key 和 value 之间通过冒号(:)分割。请求头的作用主要用于通知服务端有关于客户端的请求信息。
- User-Agent:生成请求的浏览器类型
- Accept:客户端可识别的响应内容类型列表;星号* 用于按范围将类型分组。*/*表示可接受全部类型,type/*表示可接受 type 类型的所有子类型。
- Accept-Language: 客户端可接受的自然语言
- Accept-Encoding: 客户端可接受的编码压缩格式
- Accept-Charset: 可接受的字符集
- Host: 请求的主机名,允许多个域名绑定同一 IP 地址
- connection:连接方式(close 或 keepalive)
- Cookie: 存储在客户端的扩展字段
- Content-Type:标识请求内容的类型
- Content-Length:标识请求内容的长度
- 请求体:请求体主要用于 POST 请求,与 POST 请求方法配套的请求头一般有 Content-Type和 Content-Length
11.3.2. 响应头与响应体
- 状态行:由 HTTP 协议版本、状态码、状态码描述三部分构成,它们之间由空格隔开。
- 状态码:由 3 位数字组成,第一位标识响应的类型,常用的5大类状态码如下:
- 1xx:表示服务器已接收了客户端的请求,客户端可以继续发送请求
- 2xx:表示服务器已成功接收到请求并进行处理
- 3xx:表示服务器要求客户端重定向
- 4xx:表示客户端的请求有非法内容
- 5xx:标识服务器未能正常处理客户端的请求而出现意外错误
- 响应头
- Location:服务器返回给客户端,用于重定向到新的位置
- Server:包含服务器用来处理请求的软件信息及版本信息Vary:标识不可缓存的请求头列表
- Connection: 连接方式,close 是告诉服务端,断开连接,不用等待后续的请求了。keep-alive 则是告诉服务端,在完成本次请求的响应后,保持连接
- Keep-Alive: 300,期望服务端保持连接多长时间(秒)
- 响应内容:服务端返回给请求端的文本信息。
11.3.3. 客户端表述的两种方式
- 内容协商(Content negotiation)
- ContentNegotiatingViewResolver是要创建的bean,基于内容协商生成表述,判断的依据有请求头的Accept,URL请求路径加扩展名(优先)。
- 然后会转向具体的视图解析器生成不同的视图表述
- ContentNegotiationManager(配置的作用)
- 通过setter注入到ContentNegotiatingViewResolver中
- 创建这个Bean的方式是继承自WebMvcConfigerAdapter(基于spring mvc)
- 覆盖方法configureContentNegotiation,配置缺省内容类型等。
- 缺点:不能处理request输入(消息转换)
- 消息转换器(Message conversion)
- 使用注解@ResponseBody或类级@RestController,作用:指定使用消息转换器
- 没有model和视图,控制器产生数据,然后消息转换器转换数据之后的资源表述。
- spring自动注册一些消息转换器(HttpMethodConverter),不过类路径下要有对应转换能力的库,如:Jackson Json processor、JAXB库
- 请求传入,@RequestBody以及HttpMethodConverter
11.3.4. 提供资源以外的其他内容
- @ResponseStatus(HttpStatus.CREATED)指定返回的状态码
- 控制器方法返回ResponseEntity对象,指定业务对象(负载)、状态码、响应头:不用使用@ResponseBody注解
- 异常处理器,@ExceptionHandler(异常类型),加在方法上
- 指定响应头信息,通过返回ResponseEntity对象的方式
- HttpHeaders类型:注意与发出请求时的类型MultiValueMap区别
- setLocation
1 | |
11.3.5. REST客户端
- new RestTemplats()
- getForObject(),指定返回类型,自动转换
- getForEntity(),返回ResponseEntity,有头部信息,getBody()可以转换
- put(),传递的对象存在转换问题,String转成test/plain,MultiValueMap转成x-www-form-urlncoded,对象可能转成json,要看classpass类路径下有无库。
- delete(),删除一个资源,一般提供资源路径即可
- postForObject()/postForEntity()/postForLocation
- 因为需要返回值
- postForLocation,只需要路径,不需要body,路径信息来源头部Location信息
- exchange(),可指定请求头信息
- MultiValueMap headers
HttpEntity<Object> requestEntity=new HttpEntity<Object>(headers)ResponseEntity<Spitter> response = rest.exchange()
11.4. Spring Boot
- starter:不是一个普通的jar包,可以做一些初始化
- 帮助创建Bean
- 自动管理依赖、版本号
- 自动配置:根据类路径加载的类自动创建需要的Bean
- 如:DataSource,JDBCTemplate、视图解析器等
- Actuator
- /autoconfig 使用了哪些自动配置(positiveMatches)
- /beans 包含bean依赖关系
- URI反应实体、资源的层次,是定位描述,前面可加一个版本号
@SpringBootApplication:服务启动入口- 初始化
@Configuration:配置类@ComponentScan:扫描配置- 新注解
@RestController:帮助完成序列化和反序列化
- 健康检查:url/health,返回服务的状态信息
- 环境监测:url/env,返回服务的环境信息
- actuator提供这部分的检查能力
11.5. Docker 镜像
- 把为服务做成Docker镜像
- 制作:
- Dockerfile的文本文件,放脚本
- 运行命令:
docker build -t image_name:tag_name 目录(上下文)
- 微服务打包之后,放到Docker容器里,默认起一下即可。
- Dockerfile
- FROM:指定基础镜像,必须为第一个命令
- MAINTAINER: 维护者信息
- RUN:构建镜像时执行的命令
- ADD:将本地文件添加到容器中,tar类型文件会自动解压
ADD <src>... <dest>注意:如果copy的是文件,dest的最后要加/,否则会被认为是文件名(如果是tar文件则不会)。另外目标目录如果不存在,会自动创建。ADD ["<src>",... "<dest>"]用于支持包含空格的路径- 示例
ADD hom* /mydir/添加所有以"hom"开头的文件ADD hom?.txt /mydir/? 替代一个单字符,例如:“home.txt”ADD test relativeDir/添加 “test” 到WORKDIR/relativeDir/ADD test /absoluteDir/添加 “test” 到 /absoluteDir/
- COPY:功能类似ADD,但是不会自动解压文件
- CMD:构建容器后调用,也就是在容器启动时才进行调用
- CMD [“executable”,“param1”,“param2”]
- CMD [“param1”,“param2”] (设置了ENTRYPOINT,则直接调用ENTRYPOINT添加参数)
- CMD command param1 param2 (执行shell内部命令)
- CMD echo “This is a test.” | wc -
- CMD ["/usr/bin/wc","–help"]
- ENTRYPOINT:配置容器,使其可执行化。配合CMD可省去"application",只使用参数
- LABEL:用于为镜像添加元数据
- ENV:设置环境变量
- EXPOSE:指定与外界交互的端口
- VOLUME:用于指定持久化目录
- WORKDIR:工作目录,类似于cd命令
- USER:指定运行容器时的用户名或 UID
- ARG:用于指定传递给构建运行时的变量
- ONBUILD:用于设置镜像触发器:
1 | |
- Docker build:
docker build [OPTIONS] PATH | URL | -- -f :指定要使用的Dockerfile路径;
- –force-rm :设置镜像过程中删除中间容器;
- –rm :设置镜像成功后删除中间容器;
- –tag, -t: 镜像的名字及标签,通常 name:tag 或者 name 格式;可以在一次构建中为一个镜像设置多个标签。
- –network: 默认 default。在构建期间设置RUN指令的网络模式
- RUN指令创建的中间镜像会被缓存,并会在下次构建中使用。如果不想使用这些缓存镜像,可以在构建时指定–no-cache参数,如:docker build --no-cache
11.6. 现实与挑战
- 程序规模越来越大、越来越复杂
- 客户期望快速频繁交付
- 性能和可伸缩性
- 弹性,应用程序中某个部分的故障或问题不应该导致整个应用程序崩溃
- 小型的、简单的和解耦的服务 = 可伸缩的、有弹性的和灵活的应用程序
11.6.1. 云计算平台
- 基础设施即服务(Infrastructur as a Service , IaaS)
- 平台即服务(Platform as a Service, PaaS)
- 软件即服务(Software as a Service, SaaS)
- 函数即服务(Functions as a Service, FaaS),将代码块以“无服务器”(serverless)的形式部署,无须管理任何服务器基础设施
- 容器即服务(Container as a Service, CaaS),如亚马逊ECS(Amazon’s Elastic Container Service)
11.6.2. 微服务开发需要考虑的问题
- 微服务划分,服务粒度、通信协议、接口设计、配置管理、使用事件解耦微服务
- 服务注册、发现和路由
- 弹性,负载均衡,断路器模式(熔断),容错
- 可伸缩
- 日志记录和跟踪
- 安全
- 构建和部署,基础设施即代码
11.6.3. Spring Cloud的工具集成
- Spring Boot
- Spring Cloud Config
- Spring Cloud服务发现与Consul、Eureka集成
- 与Netflix Hystrix、Ribbon集成
- 与Netflix Zuul集成
- Spring Cloud Stream,与RabbitMQ、Kafka集成
- Spring Cloud Sleuth,与日志聚合工具Papertrail、跟踪工具Zipkin集成
- Spring Cloud Security
11.6.4. 微服务划分
- 可以从数据模型入手,每个域的服务只能访问自己的表
- 刚开始粒度可以大一点,不要太细,由粗粒度重构到细粒度是比较容易的
- 设计是逐步演化的
11.6.5. 接口设计
- 使用标准HTTP动词:GET、PUT、POST、DELETE,映射到CRUD
- 使用URI来传达意图
- 请求和响应使用JSON
- 使用HTTP状态码来传达结果
11.6.6. 运维实践
- 都在源代码库中
- 指定JAR依赖的版本号
- 配置与源代码分开放
- 已构建的服务是不可变的,不能再被修改
- 微服务应该是无状态的
- 并发,通过启动更多的微服务实例横向扩展,多线程是纵向扩展
11.7. More
- 远程通信:RPC协议,性能比较高
- 普通的RESTful API相对更常用
12. 第十二章:服务配置与服务编排
12.1. 服务配置
- 将服务配置信息和代码分开
- 硬编码进入代码(不推荐)
- 分离的外部属性文件,与物理部署分离(如外部数据库)
- 使用配置管理服务来统一管理配置,配置管理更改需要通知到使用数据的服务
- 配置服务使用的存储类型
- 文件共享系统:volumn
- 源代码控制下的文件:Git
- 关系数据库
- Spring Cloud Config:文件系统、Git、Eureka、Consul
12.2. Spring Cloud配置服务器
- 基于Spring Boot
- pom.xml文件中的依赖
- spring-cloud-config-server
- spring-cloud-starter-config
- 指定父模块
- 导入dependencyManagement,依赖的构件和版本号
- application.yml:服务端口号、后端数据来源
- git、native
- bootstrap.yml,指定服务名configserver
- @EnableConfigServer
- 数据来源本地文件系统(native)
12.2.1. 关于starter包
- starter依赖其实就是一个jar,但,是一个特殊的jar
- 定义spring.factories文件
- 实现@Configuration配置类
- 在starte中实例化bean,然后在需要使用starte的工程中直接注入那些bean
- starter中需要的配置可以在使用starter的工程中定义
- starter中的bean可以在使用starter的工程中重新实现
12.2.2. 创建使用不同环境的属性数据
- @Profile
- -Dspring.profiles.active=***
- 命名约定:应用程序名称-环境名称.yml
- 访问:http://localhost:8888/licensingservice/default
- 数据来源Git:使用源代码控制系统
- 数据更新
12.2.3. 使用配置数据
- Spring data子项目,JPA编程
- 服务启动时指定:profile、配置服务端点信息
- 属性注入
- pom.xml依赖(主要是定义依赖)
- spring-cloud-starter-config
- spring-cloud-config-client
- 服务的两个本地配置文件(yaml、.分隔的属性名称)
- bootstrap.yml
- application.yml
- health、env端点
CONFIGSERVER_URI: "http://configserver:8888"configserver是编排中指定的名称,因为目前的配置服务还没有注册到服务发现- 使用配置数据的关键是pom.xml依赖,其它不需要在启动类中加什么注解。
12.2.4. YAML文件
- 使用缩进表示层级关系,不允许使用Tab键,只允许使用空格
#表示注释,从这个字符一直到行尾,都会被解析器忽略。- 对象,键值对,使用冒号结构表示
- animal: pets
- hash: { name: Steve, foo: bar }
- 数组,一组连词线开头的行,构成一个数组
- Cat- Dog- Goldfish- 行内表示法:animal: [Cat, Dog]
12.2.5. 获取属性数据
- 数据库属性自动创建数据源对象
- @Value注解
12.2.6. 属性刷新
- @RefreshScope:配置服务可以自动更新,但是要让配置服务更新则需要在服务上访问…/refresh
- refresh端点
12.2.7. 检查服务可用性
- 镜像中添加netcat
- nc -z 服务号 端口号
- depends on:只能决定启动顺序,不能判断是否准备好
12.2.8. 服务编排工具 docker-compose
1 | |
12.2.9. 敏感信息配置
12.2.9.1. 配置服务端
- 属性加密:对称加密(共享密码)、非对称加密(公钥/私钥)
- 下载并安装加密所需的Oracle JCE jar(jce_policy-8.zip)
- JCE: Unlimited Strength Java Cryptography Extension
- 将local_policy.jar、US_export_policy.jar复制到$JAVA_HOME/jre/lib/security目录
- 配置共享密钥:设置环境变量ENCRYPT_KEY
- 如果发现有ENCRYPT_KEY,则自动添加两个端点:/encrypt和/decrypt
- 属性值的前面加上{cipher}前缀
12.2.9.2. 客户端使用
- 在配置服务侧配置不要解密的属性:spring.cloud.config.server.encrypt.enabled=false
- 配置共享密钥:设置环境变量ENCRYPT_KEY,与配置服务侧相同
- 添加依赖
1 | |
13. 第十三章:服务发现、负载均衡
13.1. 服务发现
- 找到合适的微服务以及实例
- 发现服务的IP
- 确定具体的示例
- 停止服务并通知
- 启动全新的微服务,所有服务向这个服务注册和咨询
- 好处:
- 可以快速水平伸缩而不是垂直伸缩,不影响客户端
- 水平伸缩:根据需求增减服务的实例
- 垂直伸缩:服务内增加更多的线程
- 更加具有弹性:容错性更强。
- 可以快速水平伸缩而不是垂直伸缩,不影响客户端
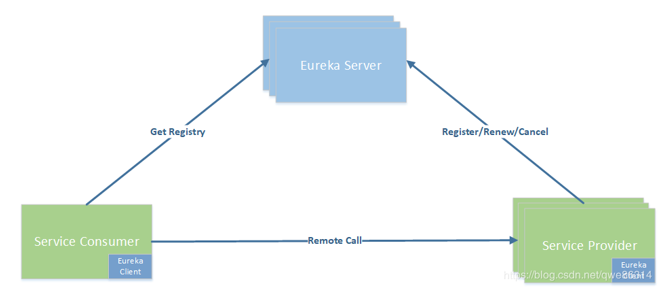
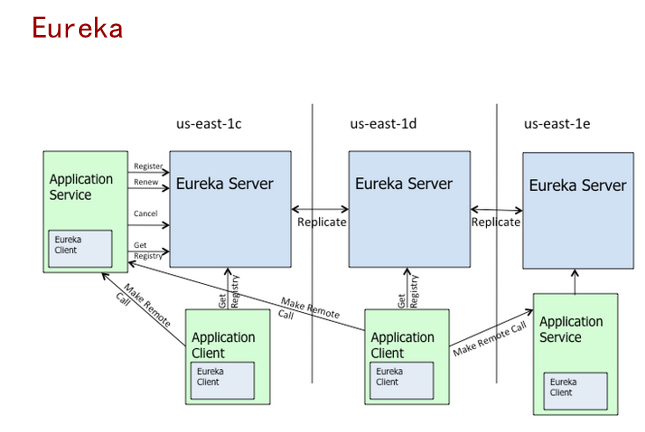
- Eureka:
- 中间添加了一个Eureka Server,所有的服务都找他注册、发送状态
- 多个Eureka Server,保证可使用(信息需同步)
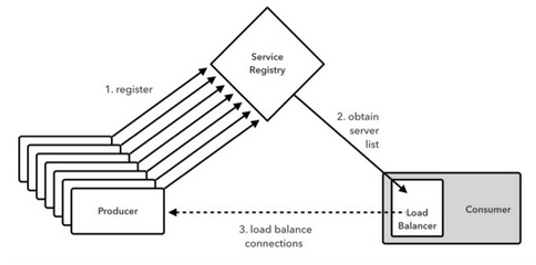
13.2. 负载均衡:Ribbon
- 客户端负载均衡
- 过程
- 从Eureka一次全取过来,然后按照一定频率进行更新
- 客户端侧维持一个列表,然后从列表中挑选。
13.3. 服务调用关系
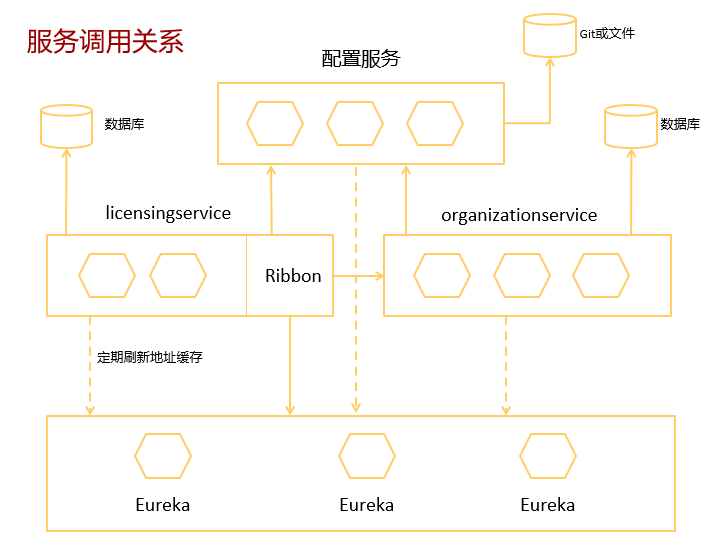
13.4. Spring Eureka服务
- pom.xml:spring-cloud-starter-eureka-server
- application.yml
- 引导类加注解@EnableEurekaServer
13.4.1. 注册服务
- pom.xml文件中的依赖:spring-cloud-starter-eureka
- bootstrap.yml、application.yml
- 应用程序ID(ServiceId)、实例ID(6833e17cc88a:customerservice:8085)
- eureka.client.fetchRegistry,本地缓存注册表,每隔30s客户端刷新
- eureka.client.serviceUrl.defaultZone,可以有多个,逗号分隔
- 启动类加注解:@EnableEurekaClient或@EnableDiscoveryClient
- http://localhost:8761/eureka/apps/licensingservice
- Accept:application/json
- 注册开始后,三次心跳,间隔10s,30S后eureka才能让使用这个服务
- 查询eurecka服务信息:http://localhost:8761/
13.4.2. 查找和调用服务
- 第三方库:Ribbon,本地缓存,本地负载均衡
- 三种方式
- Spring DiscoveryClient
- 使用支持Ribbon的RestTemplate
- 使用Netflix Feign
13.4.3. Spring DiscoveryClient
- pom.xml文件中的依赖:spring-cloud-starter-eureka
- 启动类加@EnableDiscoveryClient,使能够使用DiscoveryClient和Ribbon库
- 注入:private DiscoveryClient discoveryClient;
- discoveryClient.getInstances
- new RestTemplate
- restTemplate.exchange
- localhost:8080/v1/tools/eureka/services
- http://localhost:8761/eureka/apps/licensingservice
1 | |
13.4.4. 使用支持Ribbon的RestTemplate
- 使用Ribbon功能
- @LoadBalanced
- 注入RestTemplate restTemplate;
- restTemplate.exchange,指定要调用的服务名,而不是IP
- 可以不用加@EnableDiscoveryClient,但当前服务不能注册
13.4.5. 使用Netflix Feign调用服务
- pom.xml文件中的依赖
- spring-cloud-starter-feign
- 启动类加注解:@EnableFeignClients
- 定义接口
- 接口加注解:@FeignClient(“organizationservice”)
- 同样,可以不用加@EnableDiscoveryClient,但当前服务不能注册
- 不加的话以下也可以注入
1 | |
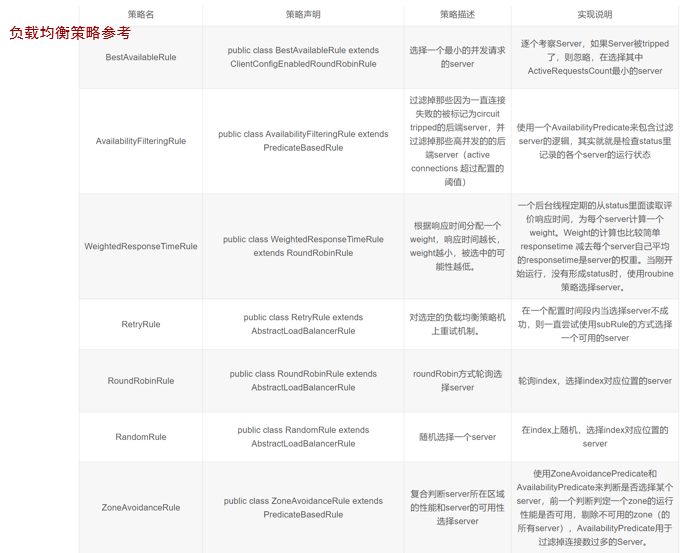
13.4.6. Ribbon自带负载均衡策略
1 | |
14. 第十四章:客户端弹性 断路器模式
14.1. 客户端弹性模式
- 远程服务发生错误或表现不佳导致的问题:客户端长时间等待调用返回
- 客户端弹性模式要解决的重点:让客户端免于崩溃。
- 目标:让客户端快速失败,而不消耗数据库连接或线程池之类的宝贵资源,防止远程服务的问题向客户端上游传播。

14.2. 四种客户端弹性模式
- 客户端负载均衡(client load banlance)模式:Ribbon提供的负载均衡器,帮助发现问题,并删除实例
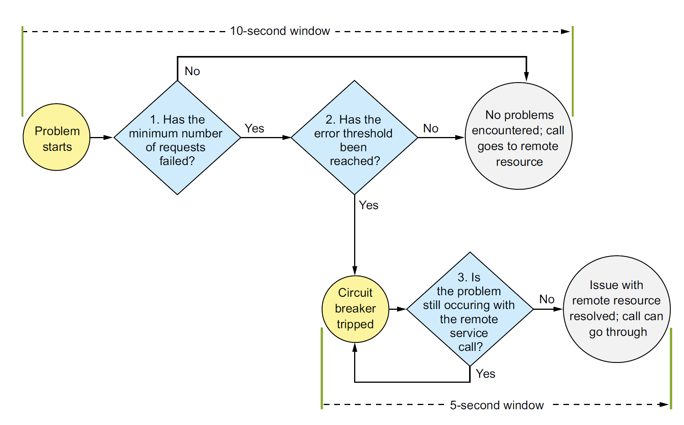
- 断路器模式(Circuit Breaker Patten):监视调用失败的次数,快速失败
- 后备(fallback)模式:远程服务调用失败,执行替代代码路径
- 舱壁隔离模式(Bulkhead Isolation Pattern):线程池充当服务的舱壁(使用ThreadLocal)
14.3. Hystrix
- Hystrix is a latency and fault tolerance library designed to isolate points of access to remote systems, services and 3rd party libraries, stop cascading failure and enable resilience in complex distributed systems where failure is inevitable.
- google翻译:Hystrix是一个延迟和容错库,旨在隔离对远程系统,服务和第三方库的访问点,停止级联故障,并在不可避免发生故障的复杂分布式系统中实现弹性。
14.3.1. 使用Hystrix
- pom.xml文件中的依赖:spring-cloud-starter-hystrix
- 启动类加注解:@EnableCircuitBreaker
- 用断路器包装远程资源调用,方法加注解:@HystrixCommand
- 默认1秒超时,超时会抛异常:com.netflix.hystrix.exception.HystrixRuntimeException
14.3.2. 设置超时时间
- 默认1s
1 | |
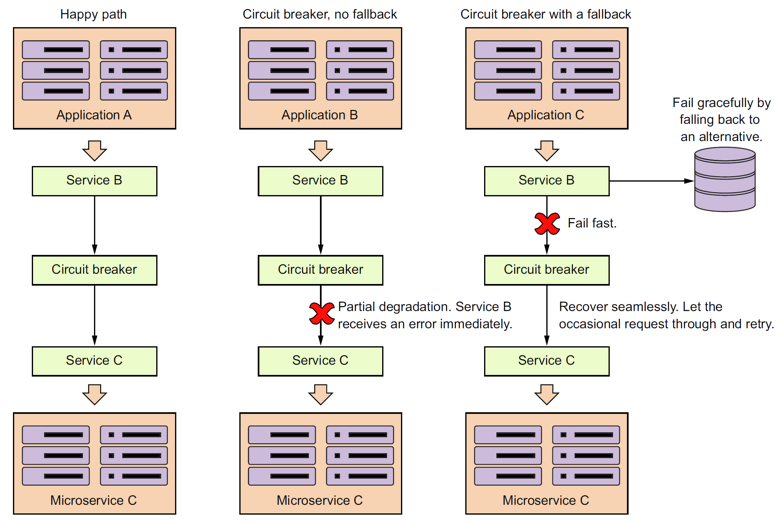
14.4. 后备(fallback)模式
- fallbackMethod = “buildFallbackCargo”
- buildFallbackCargo方法位于相同类,与原方法具有相同签名
1 | |
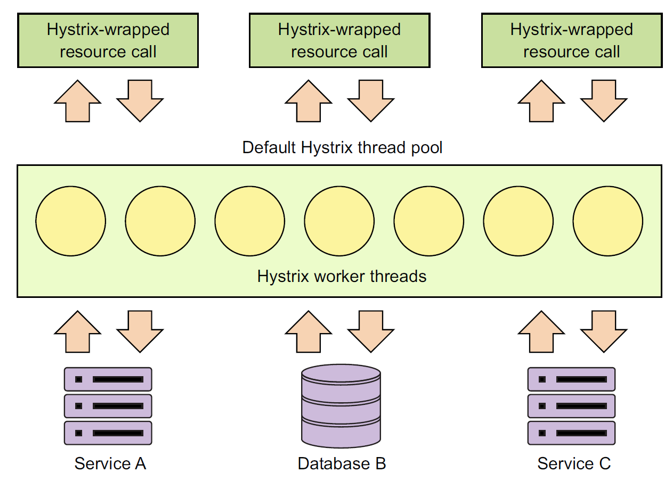
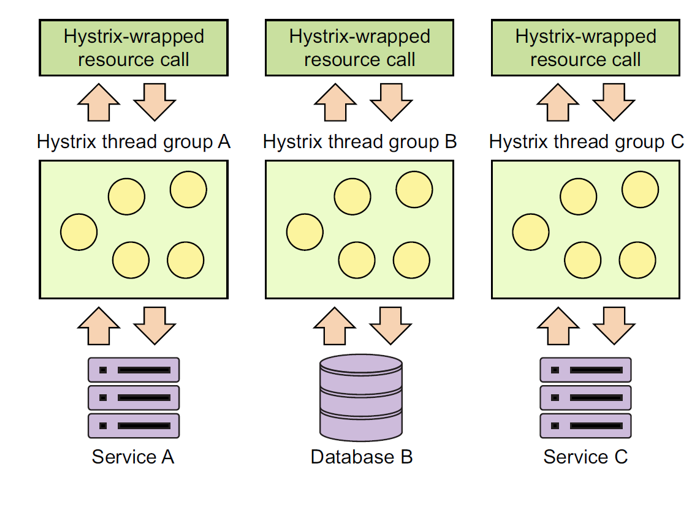
14.5. 舱壁隔离模式(Bulkhead Isolation Pattern)
- Hystrix默认共享同一个线程池(10个线程),用于不同的远程资源访问
1 | |
 |
 |
|---|
14.6. 断路器模式(Circuit Breaker Patten)
1 | |
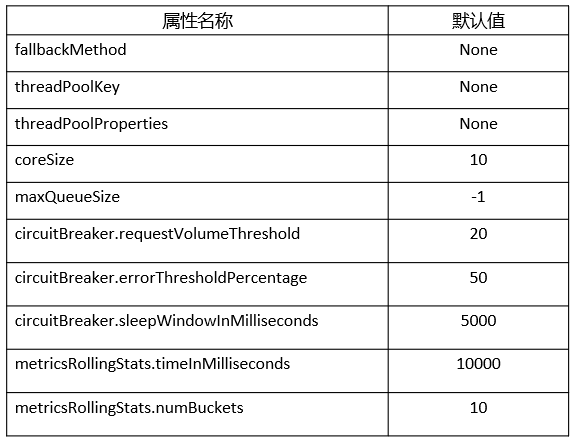
14.6.1. @HystrixCommand注解配置
14.6.2. 传递关联ID(correlation ID)
- 关联ID是唯一标识符,可用于在单个事务中跨多个服务调用进行跟踪
- 通过HTTP Header传递
- 通过实现过滤器拦截rest服务请求获取上游来的header属性
- 调用rest服务前使用ClientHttpRequestInterceptor或RequestInterceptor添加header属性,使传递到下游
14.7. Java ThreadLocal
- ThreadLocal是JDK包提供的,它提供线程本地变量,如果创建一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的一个副本,在实际多线程操作的时候,操作的是自己本地内存中的变量,从而规避了线程安全问题

14.8. Hystrix中的使用线程上下文的步骤
- 定义Hystrix并发策略类
ThreadLocalAwareStrategy extends HystrixConcurrencyStrategy
- 定义Callable类,将UserContext注入Hystrix命令中
DelegatingUserContextCallable<V> implements Callable<V>
- 配置Spring Cloud以使用自定义的Hytrix并发策略
registerConcurrencyStrategy
15. 第十五章:服务网关和路由
- 多个微服务,并不是直接暴露给外面使用
- 设置一个网关,统一从网关来访问。网关处可以进行流量监控、控制等操作。
- 认证操作也可以统一在网关处实现,这样就不用每个微服务都需要进行权限检查了。
15.1. 分布式系统的横切关注点
- 安全
- 日志记录
- 用户跟踪
- 服务网关
- 这些部分可以放到网关处做
15.2. 服务网关
- 服务网关位于服务客户端和相应的服务实例之间
- 所有服务调用(内部和外部)都应流经服务网关
- 服务网关提供的能力
- 静态路由:服务之间互相调用也可以使用网关。
- 动态路由:根据客户端请求不同来路由,运行时动态指定。
- 验证和授权:其他服务都不必操心。
- 度量数据收集(单位时间请求数和请求处理时间等等)和日志记录
15.3. Zuul
- Zuul是提供了动态路由、监控、弹性、安全等功能的网关服务,将应用程序中的所有服务的路由映射到一个URL
- 可以添加过滤器
- 使用Zuul和Zuul过滤器允许开发人员为通过Zuul路由的所有服务使用横切关注点
- ZuulFilter
- 前置过滤器,在Zuul将实际请求发送到目的地之前被调用
- 后置过滤器,在目标服务被调用并将响应发送回客户端后被调用
- 路由过滤器,用于在调用目标服务之前拦截调用

15.3.1. 使用zuul
- pom依赖
1 | |
- 启动类添加注解:
@EnableZuulProxy - 配置Zuul与Eureka通信:Eureka、Ribbon
15.3.2. 分布式系统关系图
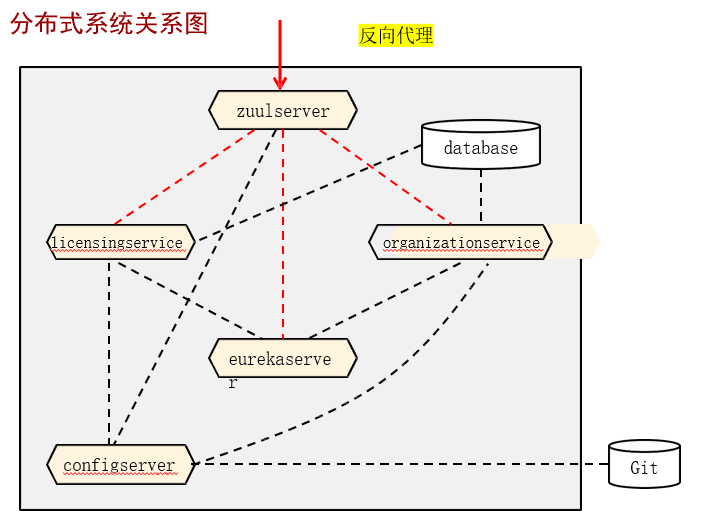
15.3.3. 映射路由的方式
- 通过服务发现自动映射路由
- 服务ID,需要访问Eureka,有服务才会创建路由
- 使用服务发现手动映射路由
- application.yml
- ignored-services:过滤服务,如果不想让zuul做第一层级的初始的静态路由构建,那就加上这个设置
- prefix
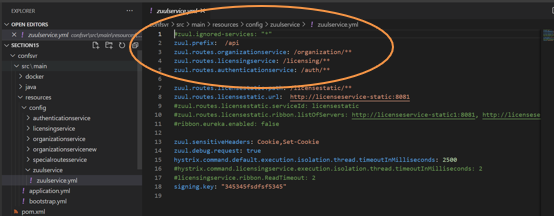
- 使用静态URL手动映射路由
- 静态URL是指向未通过Eureka服务发现引擎注册的服务的URL
- 禁用Ribbon与Eureka集成,手动指定负载均衡的服务实例
- 动态重新加载路由配置
- Git-更新Zuul Service配置
- Zuul POST:http://localhost:5555/refresh 给Zuul发送请求会就会刷新
15.3.4. 设置超时
- Hysrix 1s
- Ribbon 5s:Ribbon的懒加载导致第一次调用慢,引起失败
15.4. 总结
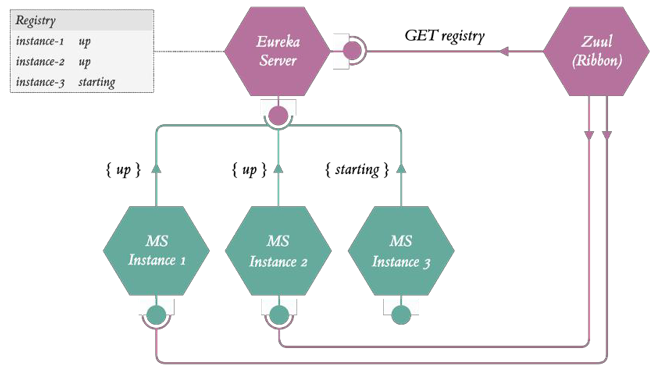
- Zuul是整体的入口,需要向Eureka获取服务和服务的状态,并建立相应的路由,借助Ribbon来访问目标服务,负载均衡。
- Feign简化了访问目标服务的方式,实现接口即可,背后还是借助了Ribbon的。
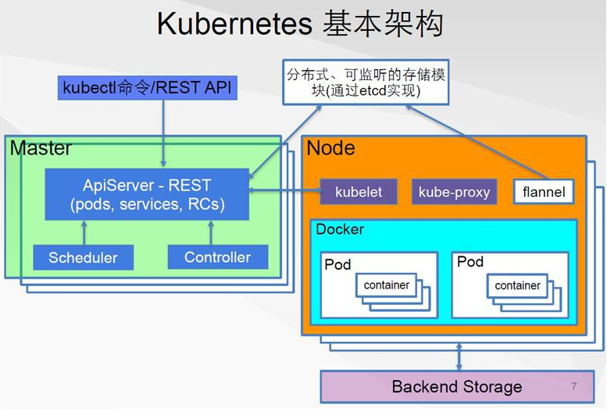
15.5. K8S
- K8S是一个帮助部署的平台,管理着多个虚拟机,每个虚拟机上都有docker
15.6. 下一代微服务 Service Mesh
- 将服务治理的内容进行下沉,Config、服务发现、网关、熔断容错等。
- 一种基础设施层,服务间的通信通过Service Mesh进行。
- 可靠地传输复杂网络拓扑中服务的请求,将服务变为现代的云原生服务。
- 一种网络代理的实现,通常与业务服务部署在一起,业务服务不感知。
- 一种TCP/IP之上的网络模型。
- 部署模型:
- 单个服务调用,表现为sidecar
- 多个服务调用,表现为通讯层
- 大量服务,表现为网格
- 为什么选择使用?
- 无需多种语言的微服务框架开发
- 对业务代码0侵入
- 不适合改造的单体应用
- 开发出的应用既是云原生的又具有独立性。
16. Spring Web Flow
- 开发基于流程的应用程序
- 将流程定义、实现流程行为的类和视图分离开
- 流程:看做是起点到终点间有很多小村庄
- 状态
- 视图
- 行为
- 决策
- 子流程
- 结束:可能不止一个
- 转移:
- to:目标状态
- on:事件
- on-exception:异常
- 全局转移:global-transitions
- 流程的数据:创建变量
- 全局有效:
<var name="order"> <evaluate result="变量名和范围">- view范围:本页面
- flow范围:本流程
- 全局有效:
- 状态
2021-服务端开发-Exam0-课程复习
https://spricoder.github.io/2021/05/04/2021-Server-Development/2021-Server-Development-Exam0-%E8%AF%BE%E7%A8%8B%E5%A4%8D%E4%B9%A0/