2021-数据库开发-Lec5-数据表的物理实现
Lec5-数据库的物理存储
- 下周完成SQL测试,按照测试给分
- 我们无法比较一次操作的性能差异,我们比较时一般是针对一类查询比较很多次
- 读的快,要聚集存储;写的快,要分散存储。
- 关系型数据库的读写是矛盾的:写的快是很重要
- NoSQL的数据很难保证数据一致性。
1. 数据表的物理实现
1.1. 冲突的目标
- 并发用户数很大的系统
- 尽量以紧凑的方式存储数据
- 尽量将数据分散存储
- 没有并发的修改密集型(change-heavy)
- 数据查询要快
- 数据更新也要快
- DBMS所处理的基本单元(页、块)通常不可分割
- 总结:读写不会和睦相处,怎么和谐啊~~
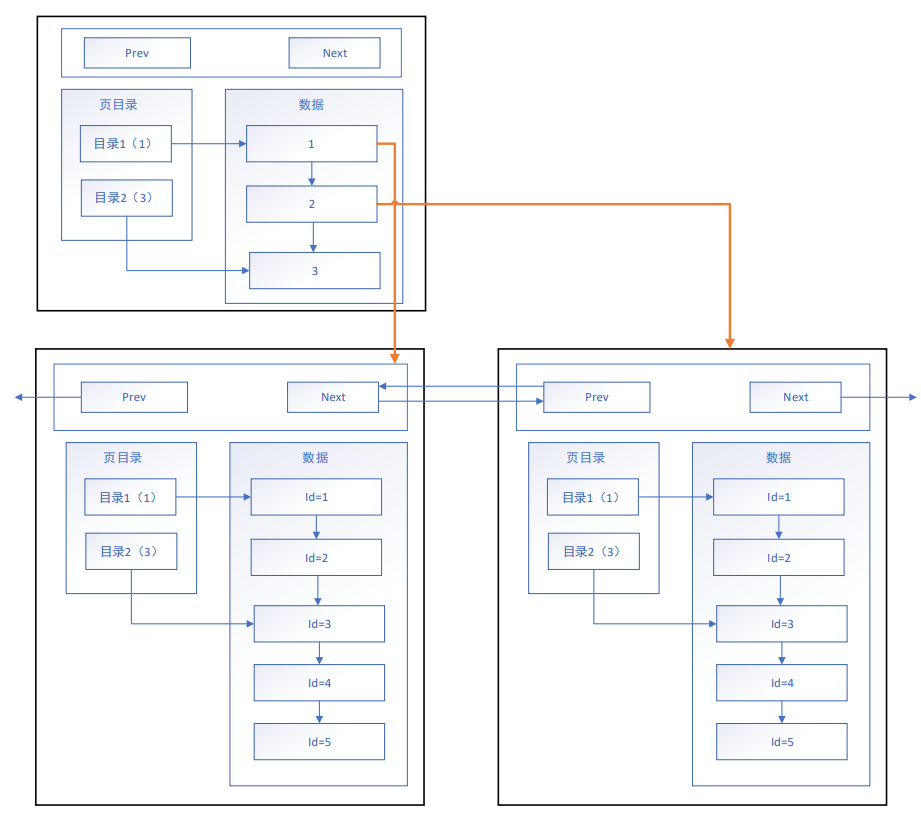
1.2. 页模式
- 链表模式的目的是优化查询效率
- 目录页的本质也是页,普通页中存的数据是项目数据,而目录页中存的数据是普通页的地址。
1.3. 把索引当成数据仓库
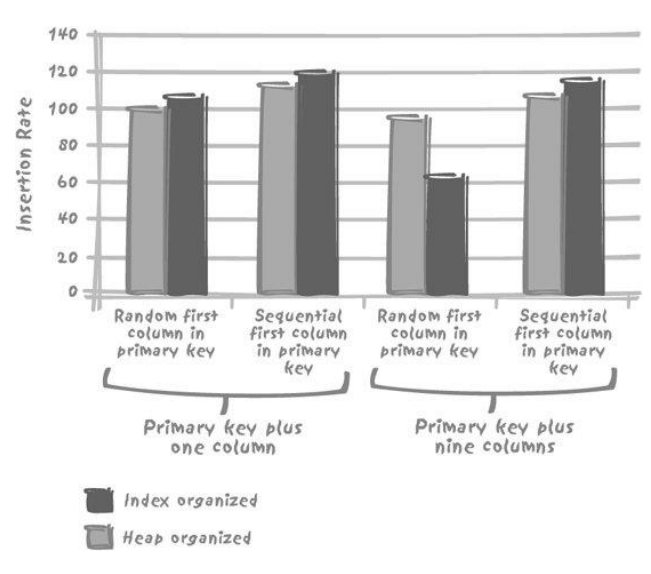
- 当索引中增加额外的字段(一个或多个,它们本身与实际搜索条件无关,但包含查询所需的数据),能提高某个频繁运行的查询的速度。
- 尽量在索引中多存储数据的极限是?–允许在主键索引中存储表中所有数据,表就是索引
- Oracle:“索引组织表(index-organized table,IOT)”
- 如果有索引index(x, y),选择select x, y仍然是可以使用索引并且很快的
- 如果表x, y, z,index(x, y, z)会将索引按照顺序文件存储,同时数据文件以堆文件,但是MySQL提供了以顺序文件的格式来存储。
1.4. 记录强制排序
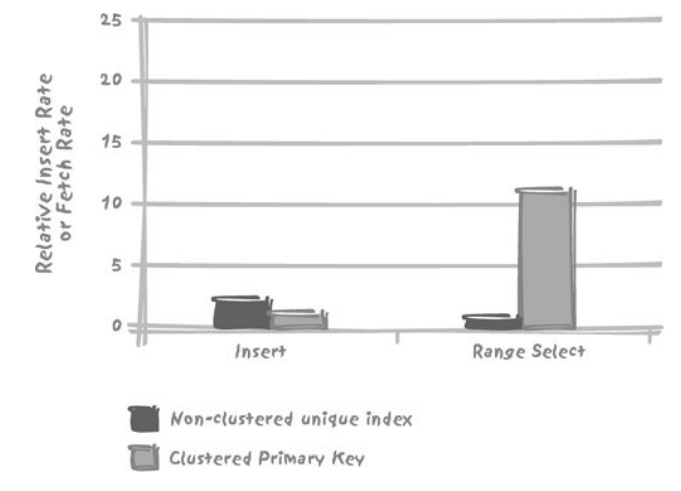
- IOT最大的优点:记录是排序的…(效率惊人)
- 记住一点:任何有序数据便于某些处理的同时,必将对其他处理不利
- 表变成了树状结构……
- 这是失传已久的"层次型数据库"
1.5. 思考题
- 程序开发中,没有银弹,任何技术都能解决一个问题,而同时带来新的问题,你能不能在你现在正在学习和使用的一些工具和技术中,总结一些他们能解决的问题,以及带来的新的问题是什么?期待你的留言。
2. 数据自动分组 - 分区
2.1. 数据自动分组(grouping)
- 分区(partition)也是一种数据分组的方式
- 提高并发性(concurrency)和并行性(parallelism):很多大型的表分成了很多的小型的表
- 从而增强系统架构的可伸缩性(scalable)
2.2. 循环分区
- 循环分区:不受数据影响的内部机制
- 分区定义为各个磁盘的存储区域
- 可以看作是随意散布数据的机制
- 保持更改带来的磁盘I/O操作的平衡
2.3. 数据驱动分区
- 根据一个或多个字段中的值来定义分区
- 一般叫分区视图(partitioned view),而MYSQL称为(merge table)
- 最早的分区方式:滑动窗口
- 自然的,我们可以使用时间进行分区,人们更倾向访问时间近的分区
- 分区的实现方式
- 哈希分区(Hash-partitioning):对分区键计算哈希值存放,不改善范围查询,负载均衡,提高并发能力
- 范围分区(Range-partitioning):非常适用于处理历史数据,按照范围来存储,设置Else分区来存放其他数据
- 列表分区(List-partitioning):定制特定的解决方案
- 很多分区是可以嵌套的
2.4. 分区是把双刃剑
- 分区能解决并发问题吗?不能
- 又回到了IOT类似的问题:“冲突”
- 通过分区键将数据聚集,利于高速检索
- 对并发执行的更改操作,分散的数据可以避免访问过于集中的问题
- 如果一次性更新52个周的条目呢
- 数据仓库中不存在这个问题,数据仓库更新是单线程插入的
- So,A or B……完全取决于您的需求
- 可以使用多层分区,用不同标准在不同层处理
2.5. 分区与数据分布
- 表非常大,且希望避免并发写入数据的冲突就一定要用分区吗?
- 例如客户订单明细表 如果大部分数据来自小部分用户,那么按照用户id进行分区就意义不大。查找80%的数据时,分区查询和全表查询区别不大
- 对分区表进行查询,当数据按分区键均匀分布时,收益最大
2.6. 数据分区的最佳方法
- 整体改善业务处理的操作,才是选择非缺省的存储选项的目标
- 更新分区键会引起移动数据,似乎应该避免这么做
- 例如实现服务队列,类型(T1…Tn)状态({W|P|D})
- 按请求类型分区:进程的等待降低
- 按状态分区:轮询的开销降低
- 取决于:服务器进程的数量、轮询频率、数据的相对流量、各类型请求的处理时间、已完成请求的移除频率
- 对表分区有很多方法,显而易见的分区未必有效,一定要整体考虑
2.7. Holy Simplicity
- 除了堆文件之外的任何存储方法,都会带来复杂性
- 除了单库单表之外任何的存储方式,都会带来复杂性
- 选错存储方式会带来大幅度的性能降低
- 总结
- 测试,测试,测试
- 设计是最重要的
- 任何设计都有时效性
2021-数据库开发-Lec5-数据表的物理实现
https://spricoder.github.io/2021/05/02/2021-Database-Development/2021-Database-Development-Lec5-%E6%95%B0%E6%8D%AE%E8%A1%A8%E7%9A%84%E7%89%A9%E7%90%86%E5%AE%9E%E7%8E%B0/