2021-数据库开发-Lec2-开发数据库的要点
Lec2-开发数据库的要点
1. 开发成功数据库应用的特点
- 需要理解数据库体系结构
- 需要理解锁和并发控制特性:每个数据库都以不同的方式实现
- 最重要的是不要把数据库当"黑盒"
- 要了解每一个数据库的体系结构和特征
- 最常见的问题就是因为我们对数据库本身了解不足
- 性能、安全性都是适当的被设计出来的
- 用尽可能简单的方法解决问题:"创造"永远追不上开发的步伐
- DBA和RD之间的关系
2. 数据库体系结构的差异
- 不能把数据库当成"黑盒"使用,因为每个数据库都是非常不同的
- Oracle和MySQL的差别(连接等多方面),类似
- Windows和Linux的差别:进程
- iOS和Android的差别
- 虽然都是DBMS,但它们也有相当的差异
- Oracle的连接是很重量的(要先预处理很多的东西,所以反复断开和连接会导致性能下降),MySQL的连接是很轻量的。
- 了解这种差异,了解你所使用数据库的特性,是开发成功数据库应用的基础
3. 并发控制
3.1. 并发控制的问题
- 现实存在并发,我们需要保持数据的一致性,所以要做并发控制
- 并发数和消耗的资源时间并不是完全线性关系,当并行数到达一定数量后,消耗的资源时间会呈指数型上涨(管理排队队列时间等)
- 可能会导致上下文切换问题(整个数据库的问题)
- 最后可能导致整个数据库的问题,称为上下文切换
- 开发环境和生成环境的数据库是不一致的,可能会出现问题。
- 数据库的问题很难调试
- 锁机制,使得并发控制成为可能:二段锁等
- 不同的数据库,实现锁机制是不一样的
3.2. 比如:Oracle的锁机制就比较特别
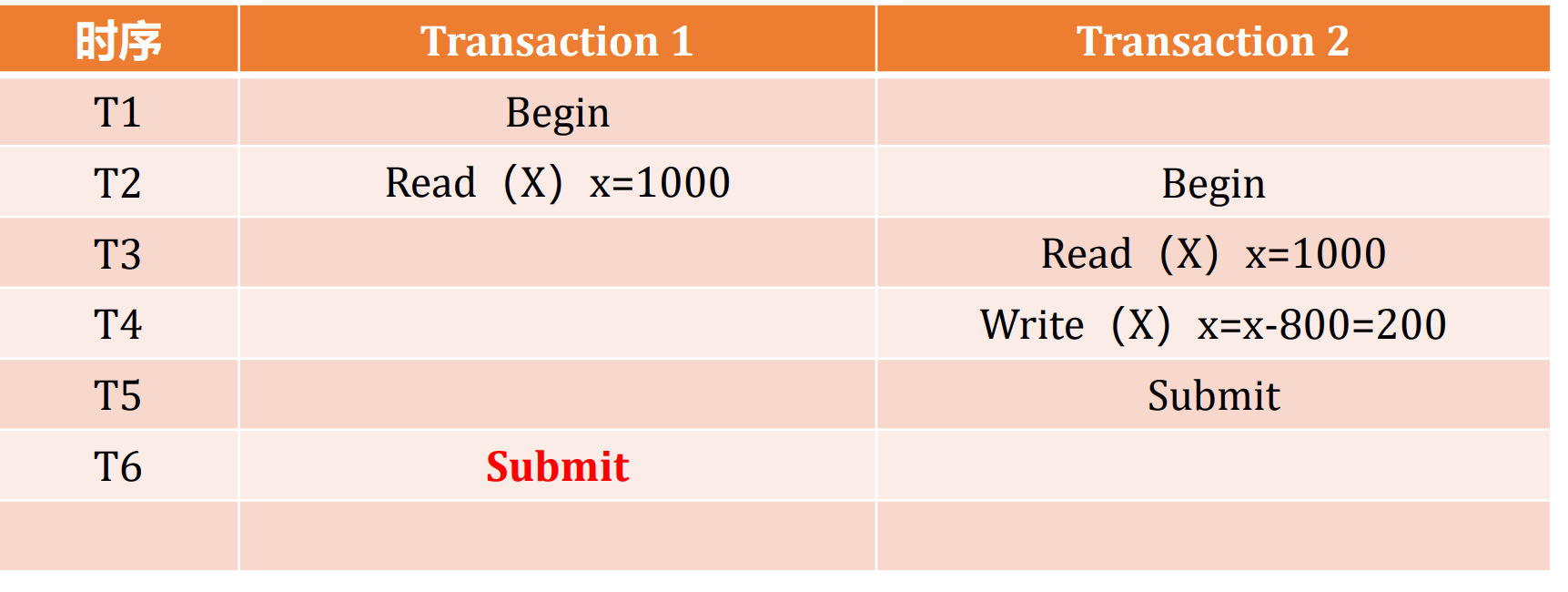
- 锁机制甚至会导致无法读取正确数据
- 这个时候T6,Transaction1能提交吗?
- 如果接受了这种提交,那么则会得到错误的值(Oracle的实现)
- 如果不接受这种提交,那么需要检查时间戳和退回
3.3. Oracle存在有时读不到正确数据的现象
- Oracle的多版本控制,读一致性的并发模型
- 读一致查询:对于一个时间点(point time),查询会产生一致的结果:永远能读到开始读的时间点的数据(而不是修改后的数据)
- 非阻塞查询:查询不会被写入器阻塞,但在其它数据库中可能不是这样的

- 对于左侧,打开游标时,不会读取数据,只有在读取游标时才会读取数据
- 对于右侧,如果我们删除了所有的表,但是我们在Oracle中仍然可以使用之前打开的游标来读取那个时刻的数据
- 事实上,打开游标的时候确实没有复制,删除数据的时候也确实删除了,但是删除数据的时候Oracle为我们使用Undo日志来保存了下来(我们记作Undo statement),是删除的回滚段,游标从这类读出数据。
3.4. Oracle这种锁机制的好处是什么?
- 读不阻塞写,可以极大程度上提高数据库的吞吐能力,我们将这个特征读作散回特性
- 例子:
ACCOUNTS(account_number, account_balance)一个银行的账户余额- 为了简单,只考虑一个仅有四行的表(同时假设每个数据库块中只存放一行数据。)
| 帐号 | 余额 |
|---|---|
| 1 | 500 |
| 2 | 250 |
| 3 | 400 |
| 4 | 100 |
- 我们想运行一个日报表,了解银行里有多少钱。下面是一个非常简单的查询:Select sum(account_balance) from accounts;
- Oracle和其它数据库在并发上的差别(一致性读):Oracle就没有读共享锁
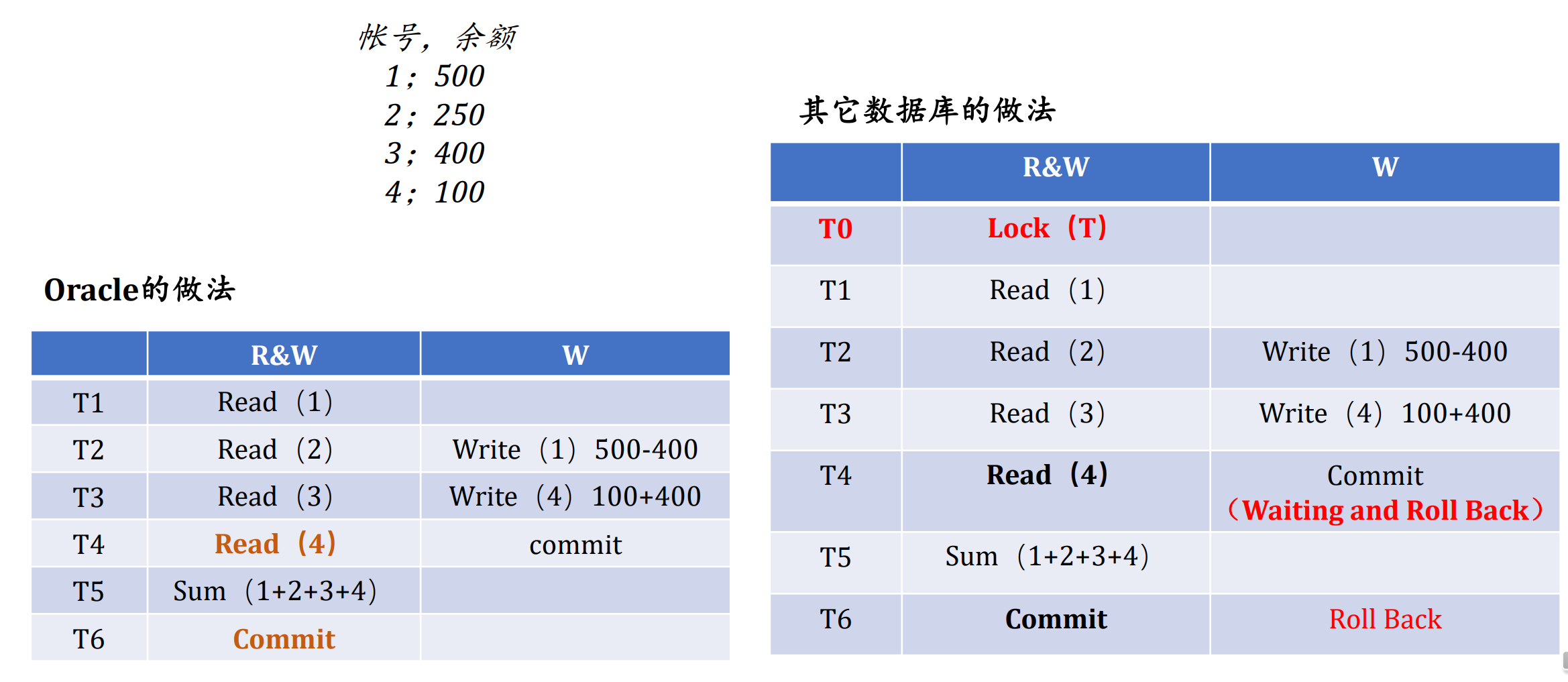
3.5. 从体系结构和特性中了解具体数据库的锁机制
- 比如Oracle实现的锁机制
- 只有修改才加行级锁
- Read绝对不会对数据加锁
- 读写器绝对不会阻塞写入器
3.6. 课后思考
- 对大多数码农而言,数据库锁机制好像都是自动和透明实现的,那么深入了解每个数据库的锁机制实现细节,对码农编码有什么影响嘛?
- 不同的数据库所对应的锁机制往往有一些不同
- 很容易出现意料之外的错误。比如orcale出现同时读写时的数据不一致
- 在选择数据库时会出现很大的困难。
- 很多时候在数据库默认的锁机制下,也会出现死锁现象,需要及时对其进行修改,修改的前提是对底层的了解。
- 锁机制作为底层的实现细节,其变化相比表层的语法而言,可以说变化很小。了解底层细节的码农,面对操作变化相对来说就有了更加大的灵活性。
- 不同的数据库所对应的锁机制往往有一些不同
- 根据这节课Oracle的锁机制特征的分析,你尝试去了解一下MySQL、SQLServer这些其它数据库锁机制实现的特征
- Mysql:
- 不同存储引擎支持不同的锁机制
- 读写操作前必须对数据上锁,且最好一次性请求足够级别的锁
- 读共享,写独占
- SQLServer:
- 支持多种锁级别和隔离级别
- 默认由系统自动管理锁和锁粒度,并负责锁升级
- Mysql:
3.7. 程序员的工作
3.7.1. 开发成功数据库应用的要点-黑盒的问题
对大多数码农而言,数据库锁机制好像都是自动和透明实现的那么深入
3.7.2. 问题是:这对我们码农有什么影响吗?
- Oracle的无阻塞设计有一个副作用,就是如果确实想保证一次只有一个用户访问一行数据,就得开发人员自己做工作。
- 例如:一个资源调度程序主要有两张表:
Resources(Resource_name,other_ data)Schedules(resource_ name, start_time, end_time)
- 往Schedules中插入一个房间预订之后,提交之前,应用将查询
1 | |
- 不能把数据库当成黑盒使用:必须深入了解你所使用的数据库体系结构和特征
- 什么时候,码农需要自己考虑并发的问题?不确定,这需要看具体的情况
4. 黑盒的问题
- 数据库黑盒和独立性的问题
- 数据库的某些细微差异会对开发造成影响
4.1. 黑盒和数据库独立性的问题
- 数据库有脱离实现级别的使用方法:Java和C++等需要在实现层面对内存进行管理,而SQL则只需要告诉引擎用哪些表按照什么条件来查询。
- 我的观点是
- 要构建一个完全数据库独立的应用,而且是高度可扩展的应用是极其困难的
- 实际上,这几乎是不可能的
- 要构建一个完全数据库独立的应用
- 你必须真正了解每个数据库具体如何工作
- 如果你清楚每个数据库工作的具体细节,你就会知道,数据库独立性可能并不是你真正想要的:避免死锁的存在,Oracle中需要用for update来实现串行化。
4.2. 例如:Null值造成的数据库迁移障碍
- 例子:在表T中,如果不满足某个条件,则找出X为NULL的所有行,如果满足就找出X等于某个特定值的所有行
- Oracle并没有返回NULL(不知道)的所有行
- Oracle中NULL == NULL 返回 NULL

- 那么我们使用了is null关键字,但是Oracle不会为空值建立聚簇索引,导致性能会大幅度下降
- 于是我们通过创建了一个基于函数的索引来解决这个问题。
4.3. 关于黑盒的问题总结几点
- 数据库是不同的。在一个数据库上取得的经验也许可以部分应用于另一个数据库,但是必须有心理准备,二者之间可能存在一些基本差别,可能还有一些细微的差别。
- 细微的差别(比如对NULL的处理)与基本差别(如并发控制机制)可能有同样显著的影响。
- 应当了解数据库,知道它是如何工作的,他的特性如何实现,这是解决这些问题的唯一途径。
4.4. 思考题
- 关于把数据库当成黑盒使用的错误,其实也会在你学习软件开发中遇到类似的问题,比如,对操作系统的黑盒化,比如对某些开发框架的黑盒化等等,请你思考一下,你的学习过程中,还能找到类似的例子嘛?
5. 设计的问题
5.1. 我能不能找一个大牛帮我调优
- 先把程序写出来,之后再让专家在生产环境中帮我调优:这个想法是错误的。
- 性能调优(目前情况下性能优化至最优)
- 根据当前CPU能力、可用内存、I/O子系统等资源情况来设置相应参数:DBA在做,性能提高20-30%
- 通过索引、物理结构、SQL的优化,具体提高某一个查询的性能
- 如果有个专家能通过一些参数、技巧提高了你的系统一个数量级的性能:不能说这个专家牛逼,大概只能说明你的程序太烂了。
5.2. 性能拙劣的罪魁祸首是错误设计
设计决定了性能的级别,其他任何调优只是在这个级别内进行调整
- 提高整体性能
- 技巧决定系统性能的下限
- 设计决定系统性能的上限
- 比如,新闻的门户网站
- 动态页面 vs 静态页面:百万量级的高并发下的动态网页导致大量的连接创建、I/O资源、CPU资源被消耗,导致负担过重。
- 静态页面 + 内容管理系统:这个管理系统远远复杂于动态页面,使用触发器等自动化部署手段来生成静态网页
- 为什么微信不支持信息的修改?
- 因为微信朋友圈后台使用的NoSQL的非关系型数据库,所有的数据都是顺序存储,才能满足大量的读写效率。
- 顺序文件的修改是非常麻烦的,因此也就不支持了。
5.3. 性能优化要考虑整体
- 性能指标都是有成本的、安全和优化中寻找平衡
- 性能指标以吞吐量为核心(每秒处理多少事务),而尽量不用一个事务几秒能处理完成
- 性能指标要考虑整体性
- 优化手段本身是有风险的,只不过潜在的风险可能没有被意识到罢了
- 任何一个技术可以解决一个问题,但必然存在另一个问题的风险
- 对于带来的风险,控制在可接受的范围才是有成果
- 性能优化技术,使得性能变好,维持和变差是等概率的事件
- 局部最优和全局最优的区别
5.4. 使用优化工具
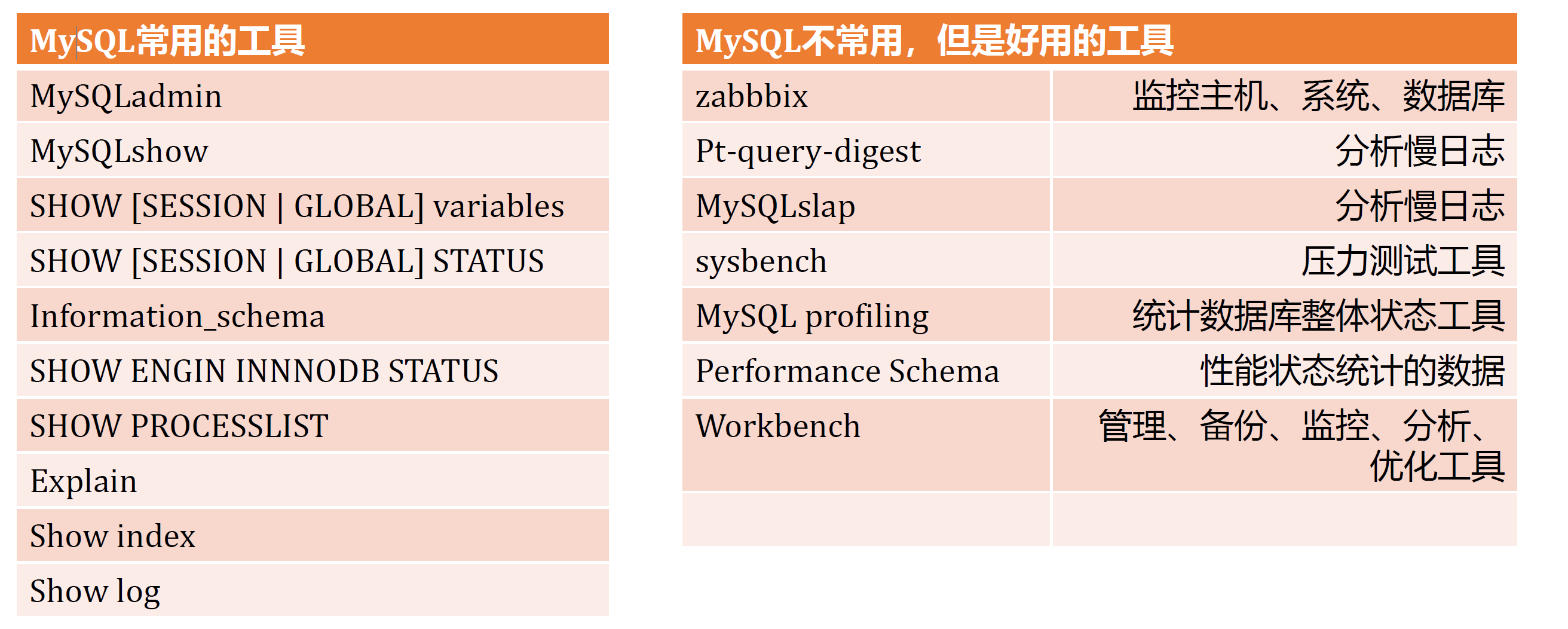
建议都尝试一下
5.5. 整体层面的性能优化考虑
- 问题一: CPU负载高, IO负载低
- 内存不够
- 磁盘性能差(磁盘问题、raid设计不好、 raid降级)
- SQL的问题
- 并发锁机制的问题
- 事务设计问题,大量小数据IO
- 大量的全表扫描
- 问题二:IO负载高,CPU负载低
- 大量小的IO执行写操作
- Autocommit,产生大量小IO
- 大量大的IO执行写操作
- SQL的问题
- IO/PS磁盘限定一个每秒最大IO次数
- 问题三: IO和CPU负载都高
- 硬件不够用了
- SQL存在问题
- 性能问题,90%的问题来源都是程序员的问题
- 开发环境到生产环境是一场灾难
5.6. SQL优化的方向

5.7. 思考
- 你对你常用的关系数据库关系系统中,去寻找一些针对优化的工具,去尝试使用一些性能的分析和监控工具(查看数据库官方Reference,首先使用官方的命令和工具)
2021-数据库开发-Lec2-开发数据库的要点
https://spricoder.github.io/2021/05/02/2021-Database-Development/2021-Database-Development-Lec2-%E5%BC%80%E5%8F%91%E6%95%B0%E6%8D%AE%E5%BA%93%E7%9A%84%E8%A6%81%E7%82%B9/