2021-数据集成-Lec3-数据集成框架
数据集成
1. 数据集成概述
1.1. 数据集成的必要性

- 历史数据的价值
- 异构环境数据源
- 不同时期、不同的公司、不同的工具、不同的平台
- 购买供应上应用包的数量日益增加
- 冗余数据、垃圾数据,数据一致性问题
- 企业需要将内部数据进行发布和交换
- 大数据和虚拟化的催化剂
1.2. 数据集成的概念
- 对各种异构数据提供统一的表示、存储和管理, 以实现逻辑或物理上有机地集中
- 集成是指维护数据源整体上的数据一致性、提高信息共享利用的效率
- 透明的方式是指用户不必再考虑底层数据模型不同、位置不同等问题,能够通过一个统一的查询界面实现对网络上异构数据源的灵活访问
- 以一种统一的数据模式描述各数据源中的数据,屏蔽它们的平台、数据结构等异构性,实现数据的无缝集成
- 数据样例
- 运动的数据:数据治理、数据质量管理、集成
- 集成为通用格式——数据转换
- 数据从一个系统迁移到另一个系统
- 在组织内部移动数据
- 从非结构化数据中抽取信息
- 将处理移动到数据段。
- 简单场景:在下图的PPT下面

- 上图中是最全的一个场景
- 主数据:决定数据类
- 描述数据:描述数据的信息
1.3. 数据集成的特征
- 分布性:网络传输的性能和安全性
- 自治性:在不通知集成系统的前提下改变自身的结构和数据
- 异构性:运行环境、数据模型和数据语义
1.4. 数据集成的分类
- 批处理数据集成:将数据以成组的方式从源应用周期性地传输到目标应用
- 实时数据集成:为了完成一个业务事务处理而需要即时地贯穿多个系统的接口
- 大数据集成
- 数据虚拟化:使用多种数据集成技术以对多种数据源和技术的数据进行实时整合,而不仅仅结构化数据
1.4.1. 批处理数据集成
- 数据转换方法:松散集成, 通过转换工具实现应用系统之间的数据转换和交换,较低层次的集成
- 数据聚合方法:借助于中间件系统构造一个虚拟的全局数据模式, 是一种集中式管理、分布式存储的较高层次的集成模式
- 析取、转换和装载(ETL):通过对异构数据源中的数据进行分析、转换和装载, 建立一个数据仓库,面向企业决策的数据集成方法
1.4.1.1. 数据转换方法
- DBMS自带的转换、迁移工具
- Oracle的Migration Workbench
- Microsoft SQL Server的DTS
- 通用性不强
- 应用系统内部集成的转换工具
- 系统与其他应用系统之间的数据接口
- 两种规范,EDI
- 通用的、集成的数据转换工具
1.4.1.2. 数据聚合方法
- 将多个数据库集成为一个统一的数据库视图
- 利用中间件集成异构数据源,不需要改变原始数据的存储和管理方式
- 中间件系统位于异构数据源和应用程序之间
- 向下协调各数据库系统
- 向上为访问集成数据的应用系统提供统一的全局数据模式和数据访问的通用接口
1.4.1.3. ETL方法
- 从多个数据源中抽取数据, 然后进行数据转换和加载, 最终得到统一的、完备的数据仓库
- 原来分散的应用系统仍然独立运作, 原来存在的异构数据源仍然为各自的应用系统提供数据服务
- 不会破坏企业原有的应用架构, 比较适合于大量数据的迁移
- 可以提供复杂的数据转换功能
- 可以集成多种数据源和复杂的商业规则, 能容忍数据在时间上的延迟
1.5. 数据集成开发生命周期
- 项目范围:数据移动的基本需求、基本设置
- 概要设置:要和数据拥有者以及安全团队谈判持续到达一个可以接受的方案
- (被盖住了)
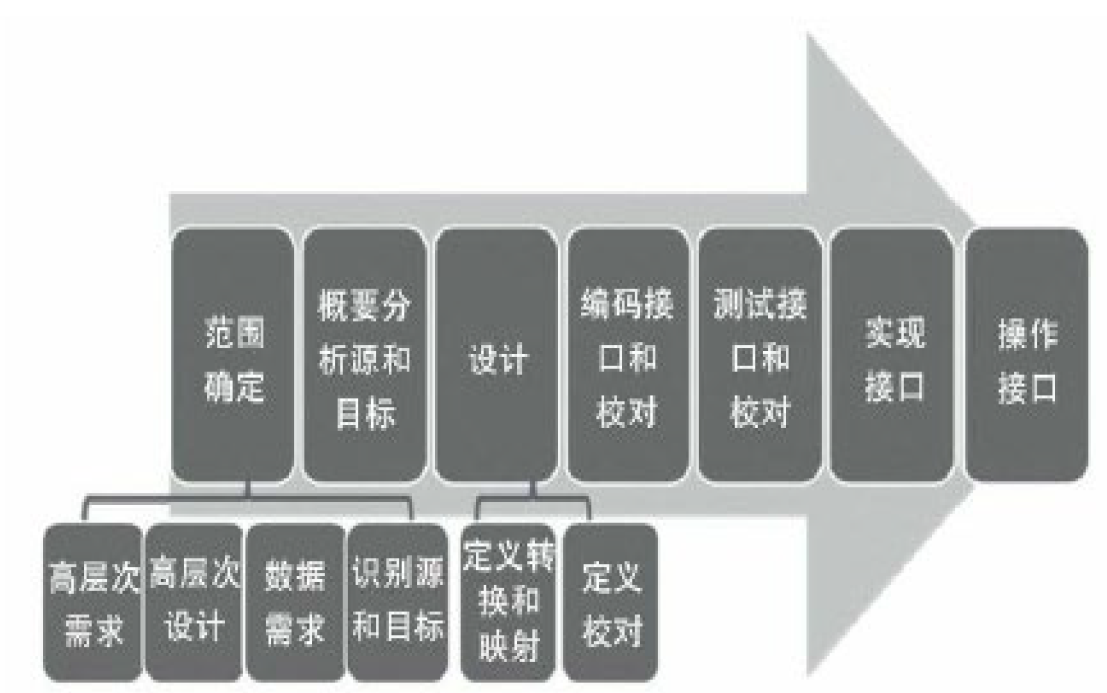
1.6. 关键问题
- 集成范围问题:一方面权限有限
- 数据资源所有权问题
- 全局模式问题:A、B、C三种数据源如何合并的问题
- 模式映射问题:冲突的规则如何进行确认
- 数据动态集成问题
1.7. XML在数据集成中的作用
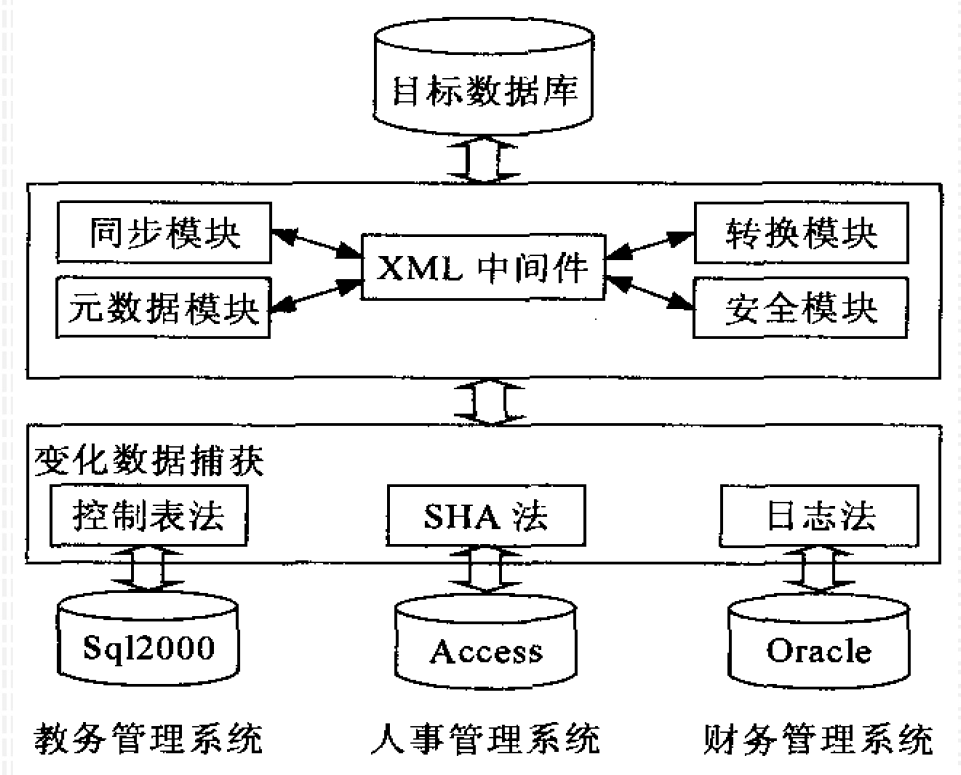
- 定义结构的好处
- 标准可以指定
- 方便进行管理
- SHA法:进行文件生成
1.8. 基于XML的异构数据集成

2. 元数据与数据映射
3. 数据库访问接口
3.1. 固有调用VS. 访问接口
- 数据库引擎带有自己的包含用于访问数据库的APl函数的动态链接库,应用程序可利用操纵数据库
- 执行效率
- 不通用
- 访问接口:透明连接
- 网络透明
- 服务器透明
- 语言透明
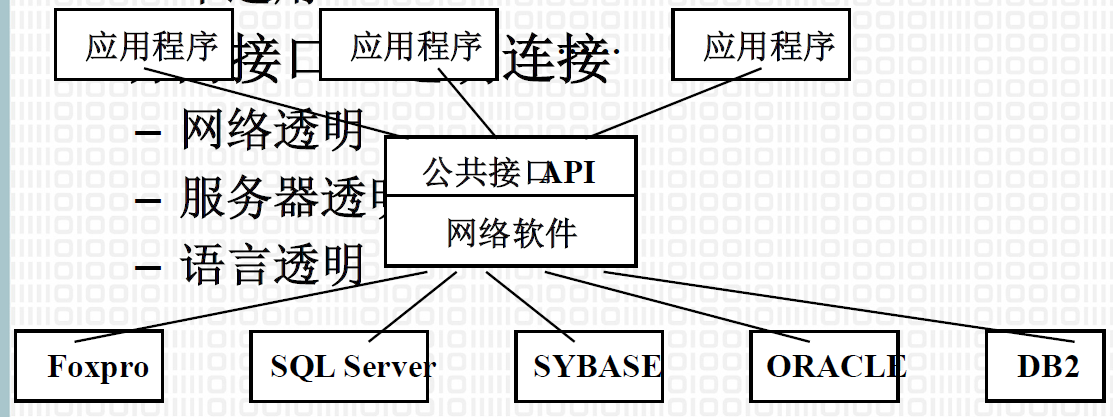
3.2. 主流的数据访问技术
- ODBC
- OLE DB
- ADO
- JDBC
- Hibernate
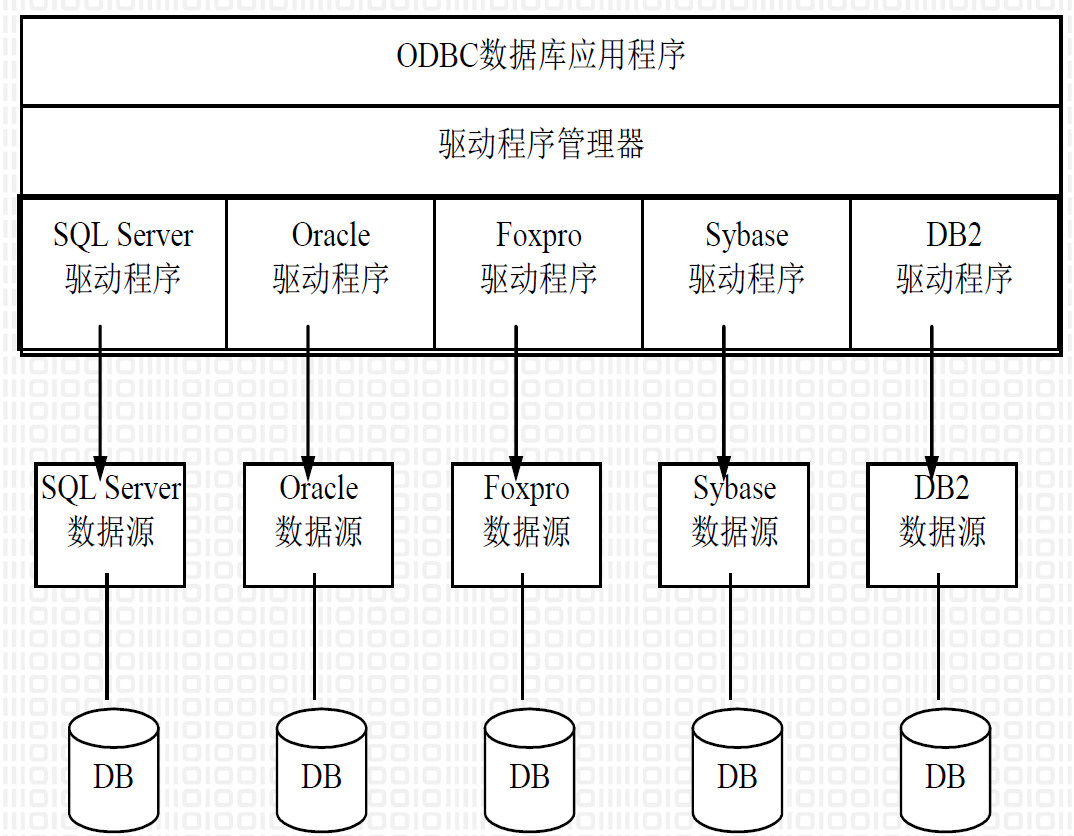
3.2.1. ODBC (Open DataBaseConnectivity )
- 应用程序:执行处理并调用ODBC API函数,以及提交SQL语句并检索结果
- 驱动程序管理器:根据应用程序需要加载/卸载驱动程序,处理ODBC函数调用,或把他们传送到驱动程序
- 驱动程序:处理ODBC函数调用,提交SQL请求到一个指定的数据源,并把结果返回到应用程序
- 数据源:包含了数据库位置和数据库类型等信息,实际上是一种数据连接的抽象
3.2.1.1. ODBC的API
- 核心级
- 最基本的功能:分配、释放环境句柄、数据库连接、执行SQL语句等
- 满足最基本的应用程序要求
- 扩展1级:增加一些函数,可在应用程序中动态了解表的模式,可用的概念模型类型等
- 扩展2级
- 主关键字和外来关键字的信息、表和列的权限信息、数据库中的存储过程信息等
- 游标和并发控制功能
3.2.1.2. ODBC接口函数
- 分配和释放内存
- 连接
- 执行SQL语句
- 接收结果
- 事务控制
- 错误处理和其他事项
3.2.1.3. 工作流程
- 调用驱动程序管理器,把目标数据源对相应的驱动程序调入动态连接库;
- 根据SQL语句,调用动态连接库中若干个相应的ODBC函数;
- 执行ODBC函数,把SQL语句以字符串的形式传到数据源处;
- 数据源执行所收到的SQL语句,把结果返回应用程序。

3.2.1.3.1. SQL语句的执行
1 | |
3.2.1.3.2. 执行SQL语句的函数
- SQL语句预备函数:SQLPrepare(jdk,szSqlStr,cbSqlStr)。其中,参数hstmt是一个有效的语句句柄,参数szSqlStr和cbSqlStr分别表示将要执行的SQL语句的字符串及其长度
- SQL语句执行函数:SQLExecute(jdk)。其中参数jdk是一个有效的语句句柄
- SQL语句查询结果的获取:
1 | |
3.2.1.4. ODBC数据库独立性
- ODBC是为最大的互用性而设计的,要求一个应用程序有用相同的源代码(不用重新编译或重新链接)访问不同的数据库管理系统(DBMS)的能力
- ODBC定义了一个标准的调用层接口(CLI)。包含X/Open和ISO/IEC的CLI规范中的所有函数,并提供应用程序普遍需要的附加函数
- 每个支持ODBC的DBMS需要不同的库或驱动程序,驱动程序实现ODBC API中的函数。当需要改变驱动程序时,应用程序不需要重新编译或者重新链接,只是动态加载新的驱动程序,并调用其中的函数即可。如果要同时访问多个DBMS系统,应用程序可加载多个驱动程序
- 如何支持驱动程序取决于操作系统,例如,在Windows操作系统上,驱动程序是动态链接库(DLL)
3.2.1.5. DBMS特有功能的支持
- ODBC为所有DBMS功能都定义了公共接口。这些DBMS功能比多数DBMS支持的更多,但只要求驱动程序实现这些功能的一个子集
- ODBC定义了API和SQL语法一致层,它规定驱动程序应支持的基本功能
- ODBC还提供两个函数(SQLGetInfo和SQLGetFunctions)返回关于驱动程序和DBMS能力的一般信息及驱动程序支持的函数列表。因此,应用程序可以检查DBMS支持的特殊功能
3.2.2. OLE DB
- 基于COM的数据存储对象,与ODBC 属于底层的数据库编程接口,对ODBC进行了扩展,可以访问非关系型数据库源
- OLEDB对ODBC进行了两个方面的扩展
- 提供了一个数据库编程的OLE接口,即COM
- 提供了一个可用于关系型和非关系型数据源的接口
- ODBC数据源是OLEDB的子集:ODBC OLE DB Provider
- OLEDB只针对C++的API
3.2.2.1. OLE DB中的COM对象
- 数据源(Data Source):对应于一个数据提供者,负责管理用户权限,建立与数据源的连接等初始操作
- 会话(Session):提供事务控制机制
- 命令(Command):执行各种数据操作,如查询命令、修改
- 行集(RowSet):数据的抽象表示,是应用程序的操作对象
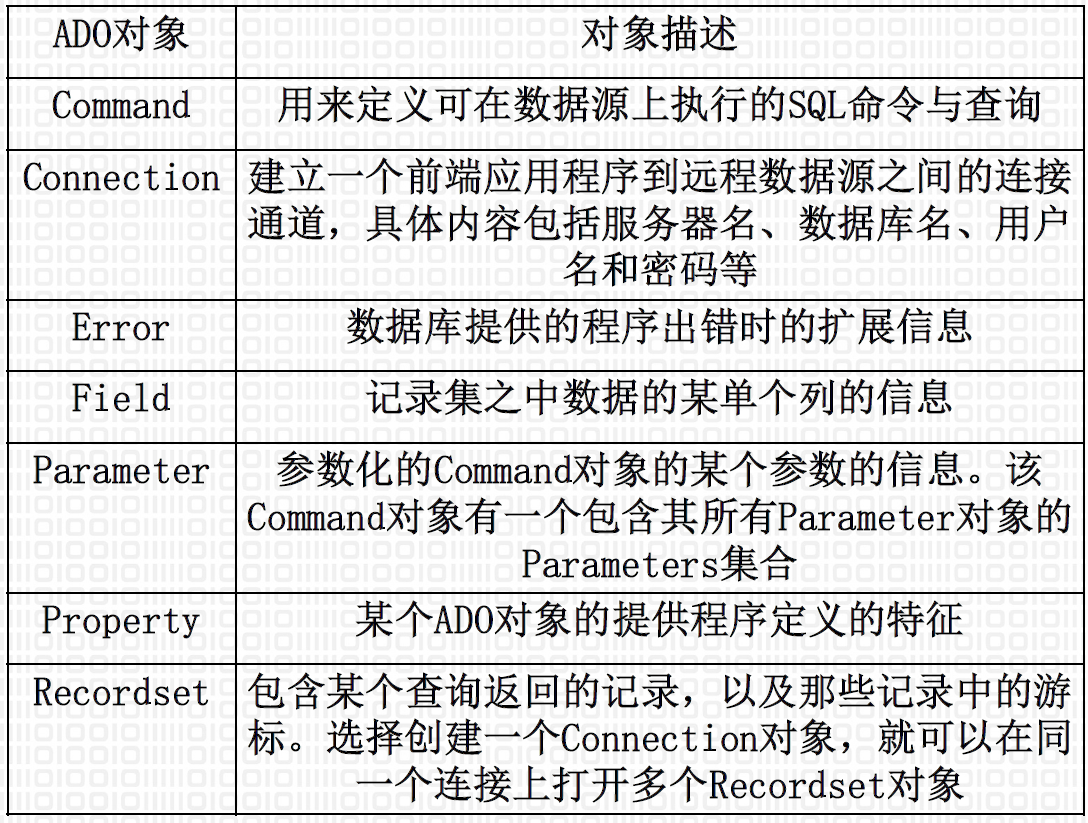
3.2.3. ActiveX Data Object(ADO)
- 建立在OLE DB之上,为操作OLE DB数据源提供了一套高层次自动化接口。ADO实际上是一个OLE DB客户程序,使用ADO的应用程序要间接地使用OLE DB
- 提供了一种数据库编程对象模型,简化OLE DB,属高层的数据库接口,适用的编程语言更多
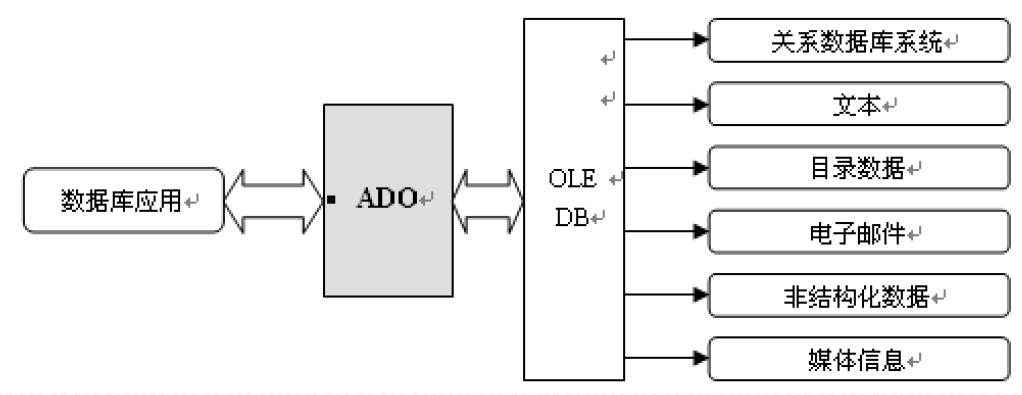
3.2.3.1. ADO(ActiveX Data Objects)
- 一种与编程语言无关的面向对象的编程接口
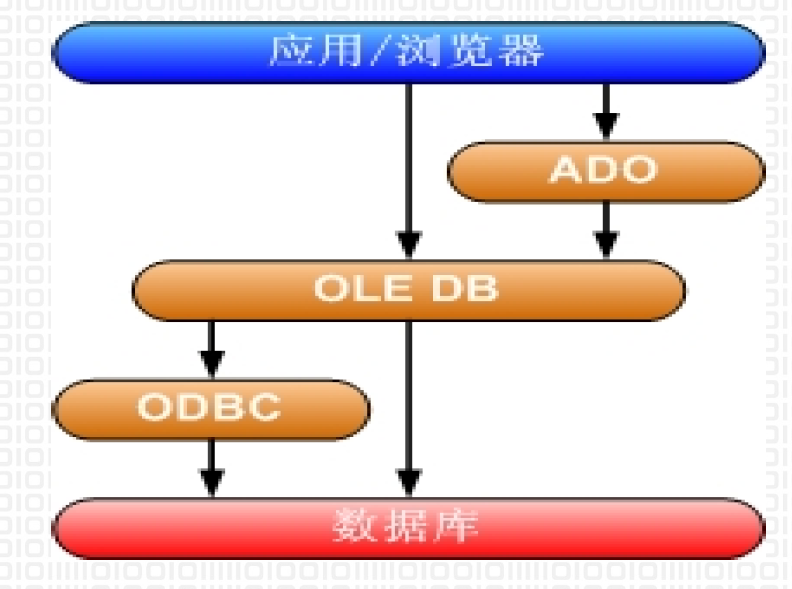
3.2.3.2. ADO对象
3.2.4. JDBC
3.2.4.1. JDBC VS. ODBC
- ODBC并不适合在Java中直接使用
- 完全精确地实现从C代码ODBC到JavaAPI写的ODBC的翻译也并不令人满意
- ODBC并不容易学习,它将简单特性和复杂特性混杂在一起,甚至对非常简单的查询都有复杂的选项;而JDBC刚好相反,它保持了简单事物的简单性,但又允许复杂的特性
- JDBC这样的JavaAPI对于纯Java方案来说是必须的
3.2.4.2. 四种JDBC驱动
- 基于JDBC-ODBC桥的java驱动
- 基于数据源本地驱动程序的虚拟java驱动
- 基于网络驱动协议的java驱动
- 纯java驱动
3.2.4.3. 常用的JDBC接口/类
- Java.sql.Driver:驱动程序实现的接口,提供连接数据库的基本方法
- Java.sql.DriverManager:管理JDBC驱动程序,提供获取连接对象的方法,建立于数据库的连接
- Java.sql.Connection:用于Java应用程序与数据库建立通信的对象,通过它进而创建Statement对象,执行SQL语句
- Java.sql.Statement:对SQL语句进行封装的特定对象,用来执行SQL语句进行数据库操作
- Java.sql.ResultSet:用于封装SQL语句查询的结果,是一个包含数据库记录的特殊对象
3.2.4.4. 直接连接数据库的步骤
- 建立数据源
- 装载驱动程序
- 建立连接
- 建立语句对象
- 执行SQL语句
- 查询结果处理
- 获取元数据
- 关闭对象
- 处理异常和警告
3.2.4.5. 示例
1 | |
3.2.5. Hibernate
- 一种Java语言下的对象关系映射解决方案,一种自由、开源的软件
- 用来把对象模型表示的对象映射到基于SQL的关系模型结构中去,为面向对象的领域模型到传统的关系型数据库的映射,提供了一个使用方便的框架
- 不仅管理Java类到数据库表的映射,还提供数据查询和获取数据的方法
3.2.5.1. Hibernate API中的接口
- 提供访问数据库的操作(如保存、更新、删除和查询对象)的接口:Session、Transaction和Query
- 用于配置Hibernate的接口:Configuration
- 回调接口,使应用程序接收Hibernate内部发生的事件,并作出相关的回应:Interceptor、Lifecycle和Validatable
- 用于扩展Hibernate的功能的接口,如UserType、CompositeUserType和IdentifierGenerator接口。需要时应用程序可以扩展这些接口。
3.2.5.2. 个核心接口
- Hibernate内部封装了JDBC、JTA和JNDI
- Configuration接口:配置hibernate,根启动hibernate,创建SessionFactory对象
- SessionFactory接口:初始化hibernate,充当数据存储源的代理,创建Session对象
- Session接口:负责保存、更新、删除、加载和查询对象
- Transaction:管理事务
- Query和Criteria接口:执行数据库查询
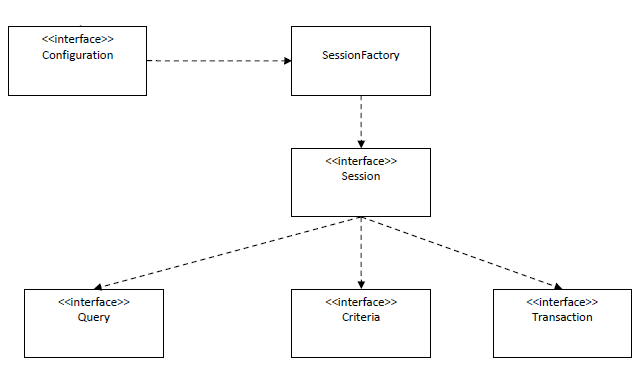
3.2.5.3. 使用Hibernate的步骤
- 创建Hibernate的配置文件
- 创建持久化类
- 创建对象-关系映射文件
- 通过Hibernate API编写访问数据库的代码
4. 元数据与数据映射
4.1. 数据编码
- 字符集
- ASCII
- 汉字编码
- Unicode
- UTP-8
- 编码之间的关系
4.1.1. 字符集
- Samuel F.B.Morse在1838年到1854年间发明了电
- Braille代码:一种6位代码,它把字符、常用字母组合、常用单字和标点进行编码
- Telex、Baudot以及CCITT #2代码都是包括字符和数字的5位代码
- 6位字符码系统BCDIC(Binary-Coded Decimal Interchange Code),8位EBCDIC IBM大型主机
- 美国信息交换标准码ASCII,1967年
- DBCS:double-byte character set
- Unicode解决方案
4.1.2. ASCII
- 7个位所能提供的128个编码位置
- 94个图形字符码和34个控制字元码
- 图形字符包括52个大小写英文字母﹑10个阿拉伯数字﹑9个标点符号﹑6个括号,以及17个其它符号,编码范围从33到126
- 控制字符则包括10个传输控制字符、6个版面调整字符、4个设备控制字元、4个信息分隔字符和10个特殊控制字符,其编码为0~32和127
- 扩展ASCII
4.1.3. 汉字编码
- GB2312 :小于127的字符的意义不变,两个大于127的字符连在一起表汉字7000
- 高字节从0xA1用到0xF7,把01-87加上0xA0
- 低字节从0xA1到0xFE,把01-94加上0xA0
- GBK:GB2312的扩展,主要扩展了繁体中文字的支持27000
- GB18030:解决汉字、日文假名、朝鲜语和中国少数民族文字组成的大字符集计算机编码问题。总编码空间超过150万个编码位,收录了27484个汉字
- BIG5:13,053个中文字,高位字节的编码范围0xA1-0xF9,低位字节的编码范围0x40-0x7E及0xA1-0xFE
4.1.4. Unicode
- Universal Multiple-Octet Coded Character Set的简称,支持世界上超过650种语言的国际字符集
- Unicode允许在同一服务器上混合使用不同语言组的不同语言
- 由一个名为Unicode 学术学会(Unicode Consortium)的机构制订的字符编码系统,支持现今世界各种不同语言的书面文本的交换、处理及显示
- Unicode是一种在计算机上使用的字符编码,为每种语言中的每个字符设定了统一且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求
- Unicode通过增加一个高字节对ISO Latin-1字符集进行扩展,当这些高字节位为0时,低字节就是ISO Latin-1字符
- Unicode中不同部分的字符都同样基于现有的标准,便于转换
- 中国、日本和韩国的象形文字(总称为CJK)占用了从0x3000到0x9FFF的代码
- Unicode只有一个字符集,没有歧
- Unicode在制订时没有考虑与任何一种现有的编码方案保持兼容
4.1.5. 通用转换格式UTF-8
- 用ASCII表示的字符使用UNICODE并不高效
- 网络通讯时数据高低位的解读方式,核对双方对于高低位的认识是否是一致,标志符FEFF,EFBBBF for UTF-8。Byte Order Mark
1 | |
- 以转换后第1字节起头连续设为"1"的标记位的数目表示转换成几个字节,第2~第4字节起头两个位被设为10当做识别
4.1.6. 一个例子
- 联通的内码
- c1 1100 0001
- aa 1010 1010
- cd 1100 1101
- a8 1010 1000
- UTF8编码
- 0000 0000 0110 1010:j
- 0000 0011 0110 1000
4.2. 元数据在集成中的作用
- 中央集线器确保Oracle电子商务套件与3个老的ERP系统之间一致的数据映射
- 大量的企业数据要么深锁在数据库中,要么就被封闭在应用中
- 随着企业跨应用组合不同的功能,这些数据模型也被混合在一起
- 对数据而言,始终存在一种上下文关系甚至当一个字段为空白时,不同应用会对它的含意做出不同的假设
4.3. 什么是元数据
- data about data
- 通过一组属性或元素来描述特定的资源
- 元数据模型提供了描述一类资源的具体对象时所有规则的集合
- 描述资源属性的术语:元数据元素
- 关系、结构约束、语法表示等
- 提供规范、普遍的描述方法和检索工具,为分布的、由多种资源组成的信息体系提供整合的工具与纽带
4.4. DBMS的元数据
- 某个数据库中的表和视图的个数以及名称
- 某个表或者视图中列的个数以及每一列的名称、数据类型、长度、精度、描述等
- 某个表上定义的约束
- 某个表上定义的索引以及主键/外键的信息
4.5. SQL Server系统表与元数据
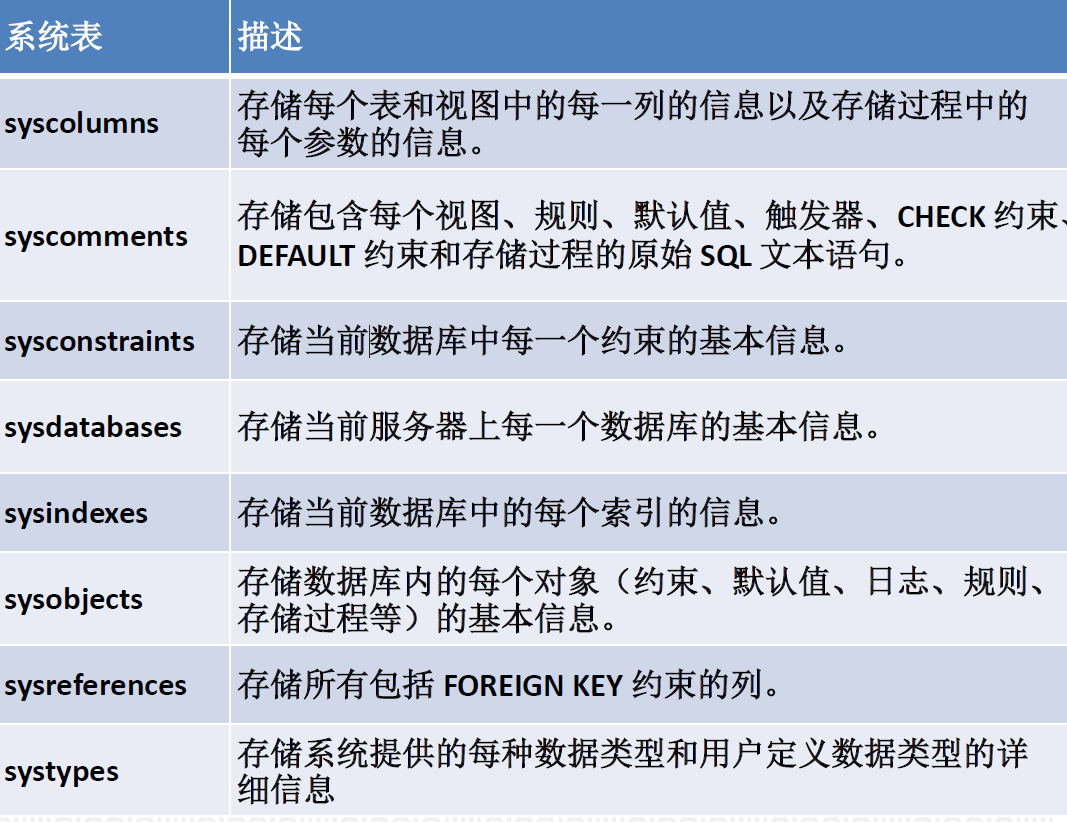
4.6. 元数据的分类
- 从元数据的作用角度
- 描述型元数据
- 结构型元数据
- 管理型元数据
- 从信息系统的角度
- 业务元数据
- 技术元数据
- 操作元数据
4.6.1. 业务元数据
1 | |
4.7. 元数据的层次
- 分层管理是解决复杂问题的一种思路。将资源按照一定的层次进行分类,便于管理
- 元数据可应用于不同层次,可以定义全局的元数据,也可以定义某一层次资源的元数据
- 可以在"计算机图书"类中加上"相关编程语言"这样一个属性
4.8. 元数据的功能
- 描述和发现资源
- 管理资源集合
- 保存数字化资源
- 提供数据互操作和数据转换方面的信息
4.8.1. 描述和发现资源
- 允许通过相关的标准来发现资源
- 标识资源
- 把相似的资源放在一起
- 识别不一样的资源
- 提供定位(位置)信息
4.8.2. 保存数字化资源
- 以一种统一和稳定的方式描述和组织存储在不同介质上的信息
- 创建描述性元数据的一个重要原因就是要使相关信息的发现更加容易
- 元数据是确保未来资源将存在并持续被访问的关键
- 通过资源发现,元数据可以有助于电子资源的组织,使交互操作和遗产资源集成,提供数据标识和支持存档和保存变得更加容易
4.8.3. 数据互操作
- 采用元数据来描述一个资源,允许资源在提升交互操作性的途径下被人和机器所理解
- 交互操作就是在多个不同硬件和软件平台、数据结构和接口的系统之间最小内容和功能丢失的交换数据的能力
- 利用被定义的元数据模式,被共享的协议和元数据模式之间的关联,跨网络的资源可以被无缝的查询
4.9. 元数据管理
- 元数据创建
- 元数据存储
- 元数据交换
- 元数据集成
- 元数据监督
- 元数据优化
4.10. 元数据管理的五种成熟度
- 第一级随机状态
- 第二级发现
- 第三级管理控制
- 第四级优化
- 第五级自动化
4.11. Resource Description Framework
- 一个用于描述Web 上的资源的框架
- 针对数据的模型以及语法,供不同的用户来交换和使用
- 使用XML 编
- W3C 语义网络活动的组成部分,是一个W3C 推荐标准(2004 年2 月)
- 描述购物项目的属性,如价格以及可用性
- 描述Web 事件的时间表
- 描述有关网页的信息,比如内容、作者以及被创建和修改的日期
- 描述网络图片的内容和等级
- 描述针对搜索引擎的内容
4.11.1. RDF 规则
- RDF 使用属性和属性值来描述资源
- 资源是可拥有URI 的任何事物,比如"http://www.w3school.com.cn/rdf"
- 属性是拥有名称的资源,比如"author" 或"homepage属性值是某个属性的值,比如"David" 或http://www.w3school.com.cn
- 描述资源"http://www.w3school.com.cn/rdf" 的RDF 文档
1 | |
4.11.2. RDF 陈述
- 资源、属性和属性值的组合形成一个陈述
- 陈述:“The author of http://www.w3school.com.cn/rdf is David.”
- 主体:http://www.w3school.com.cn/rdf
- 谓语:author
- 客体:David
4.11.3. RDF 陈述

4.11.4. 标准的资源描述框架
- 描述所有元数据格式,解决元数据互操作性
- XML以一种标准化的方式来建立数据表示的结构
- RDF明确表达元数据的语义、句法和结构
- 采用RDF Schema为RDF资源的属性和类型提供词汇表
4.12. 元数据映射
- 信息系统的整合与交互性问题
- 同一领域的元数据标准
- 不同领域不同专业
- 元数据标准映射:元数据分析、建立元数据对应关系字典、编制转换程序
- 非实时映射:将源元数据系统的数据映射到目标元数据系统
- 实时映射:根据元数据映射表建立转换接口
4.13. 元数据映射表
- 元数据语义映射描述元数据标准中元素的对应关系
- 一对一关系
- 一对多关系
- 多对一关系
- 无对应关系
- 元数据取值内容的映射关系
- 数据类型、取值范围、受控词汇
- 文本和数值类型间或文本和日期类型
- 自由文本和受控词,不同的受控词汇表
4.14. 元数据匹配差异
- 必备元素与可选元素的差异
- 可重复元素与不可重复元素的差异
- 子元素差异
- 元素层次错位
4.15. 元数据映射局限性
- 元素之间无法完全映射,信息丢失
- 随着元数据格式数量的增多,映射的工作量将大大增加

4.16. 基于XSLT实现元数据映射
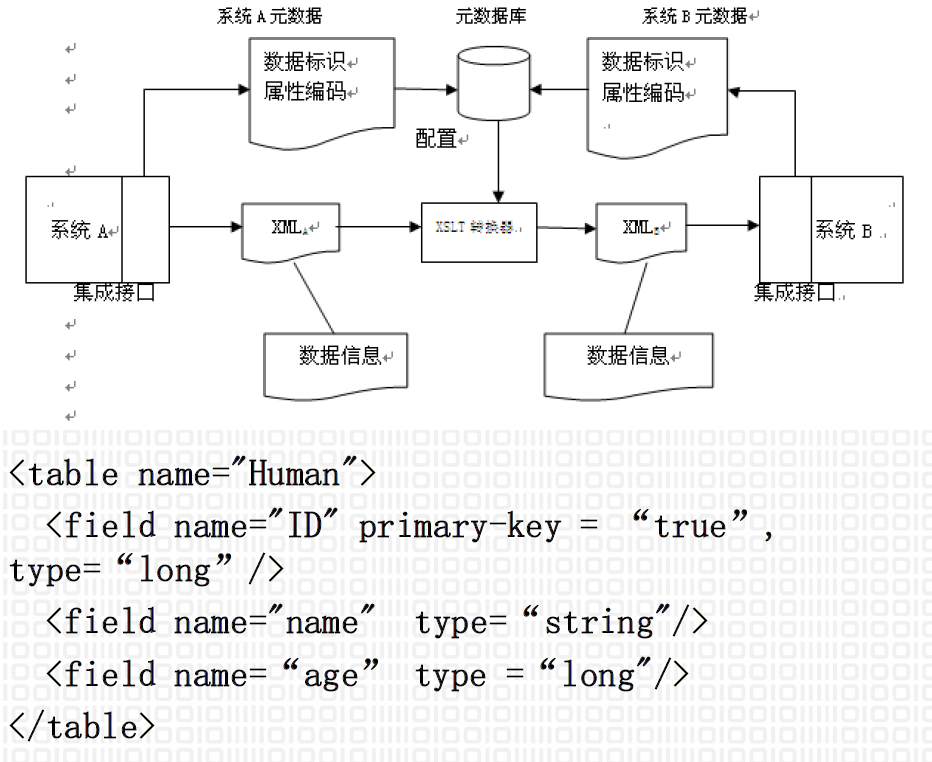
4.17. 实施步骤
- 盘点各系统的数据库,提取出元数据,设计出Schema确定其编码属性
- 开发适配器,将源信息从关系数据库向XML文件转换
- 确定集成信息的映射规则和编码属性的对照关系,利用XSLT实现源XML 文件向目标文件转换
- 集成目标XML文件中的资源信息
4.18. 数据异构冲突
- 命名冲突
- 同名异义、异名同义
- 全局命名映射
- 格式异构
- 类型转换函数
- 类型冲突
- 同一种数据类型精度不同
- 取舍
5. ETL技术
5.1. Extraction-Transformation-Loading
- 原本是构建数据仓库的一个环节:将分布的、异构数据源中的数据如关系数据、平面数据文件等抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础
- ETL是BI项目重要的一个环节,BI项目中,通常情况下ETL会花掉整个项目的1/3的时间
- ETL也越来越多地应用于一般信息系统中数据的迁移、交换和同步
5.2. 数据仓库
- 为决策支持服务的面向主题的、集成的并随时间变化的、相对稳定的数据集合
- 面向主题:数据仓库中的数据按照主题进行组织
- 集成:从多个数据源将数据集合到数据仓库中,并集成为一个整体;
- 稳定:数据仓库中的数据通常是历史数据,很少进行更新;
- 时变:数据仓库中的所有数据都有特定的时间标识.
5.3. 数据仓库、ODS和数据库的比较
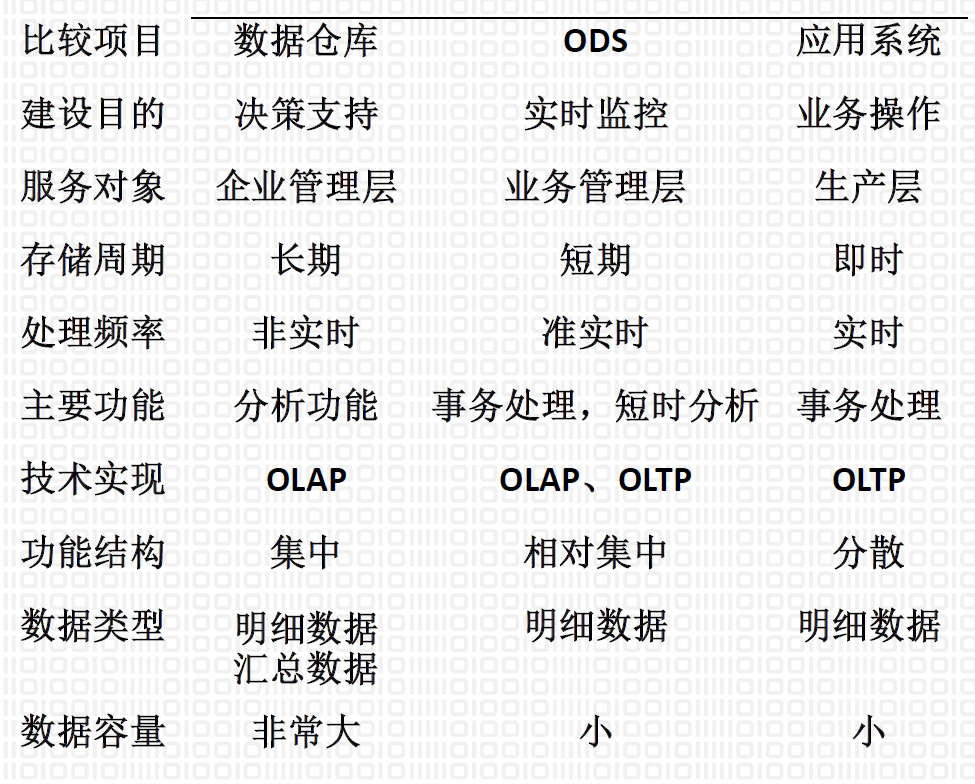
5.4. 数据仓库概念模型
5.5. 数据仓库的结构

5.6. 数据分析方法
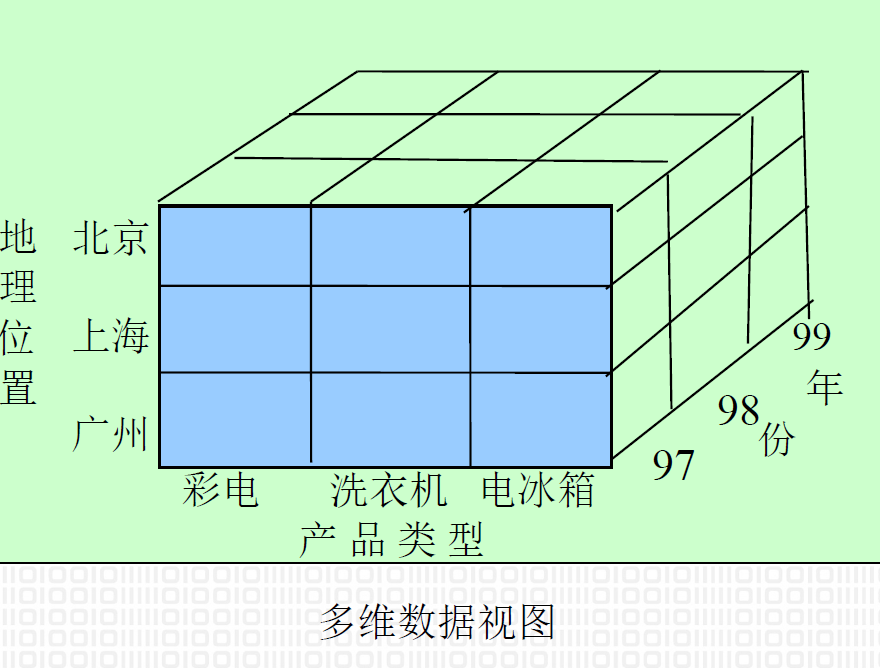
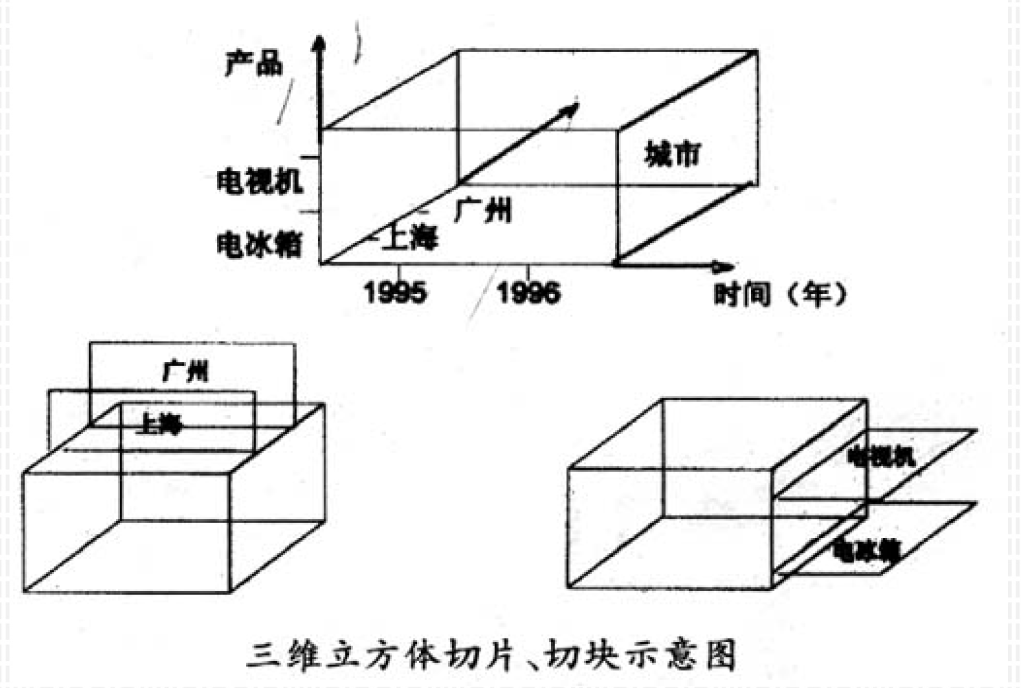
- 切片和切块(Slice and Dice):多维数据结构中,按二维进行切片,按三维进行切块,可得到所需要的数据。如在"城市、产品、时间"三维立方体中进行切块和切片,可得到各城市、各产品的销售情况
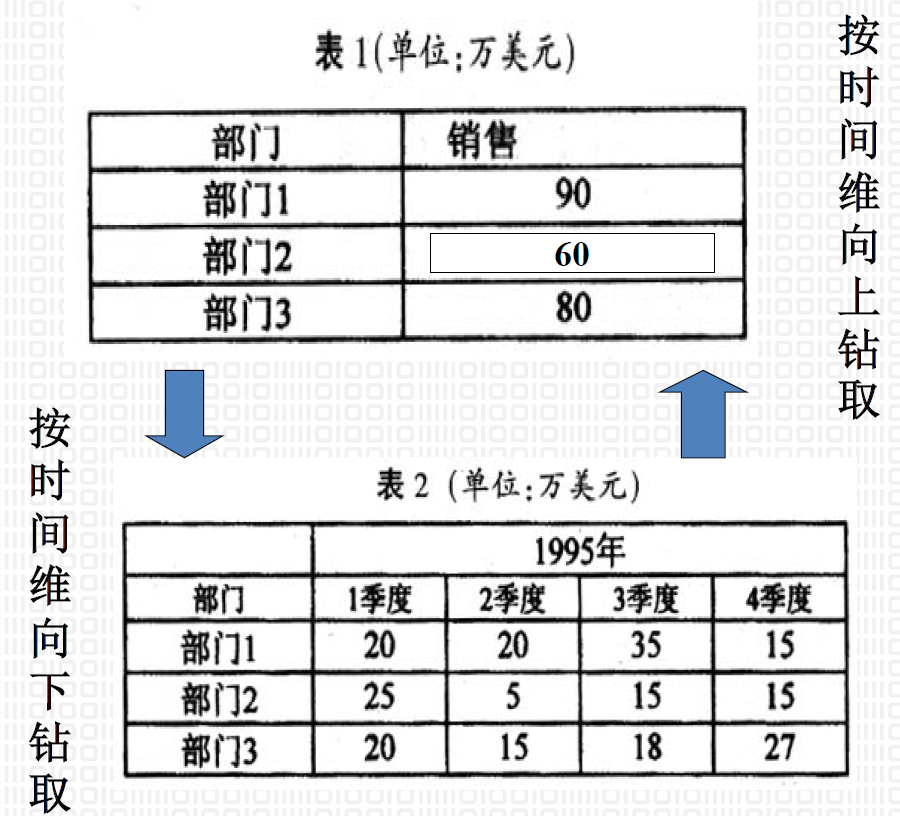
- 钻取(Drill):钻取包含向下钻取(Drill-down)和向上钻取(Drill-up)/上卷(Roll-up)操作,钻取的深度与维所划分的层次相对应
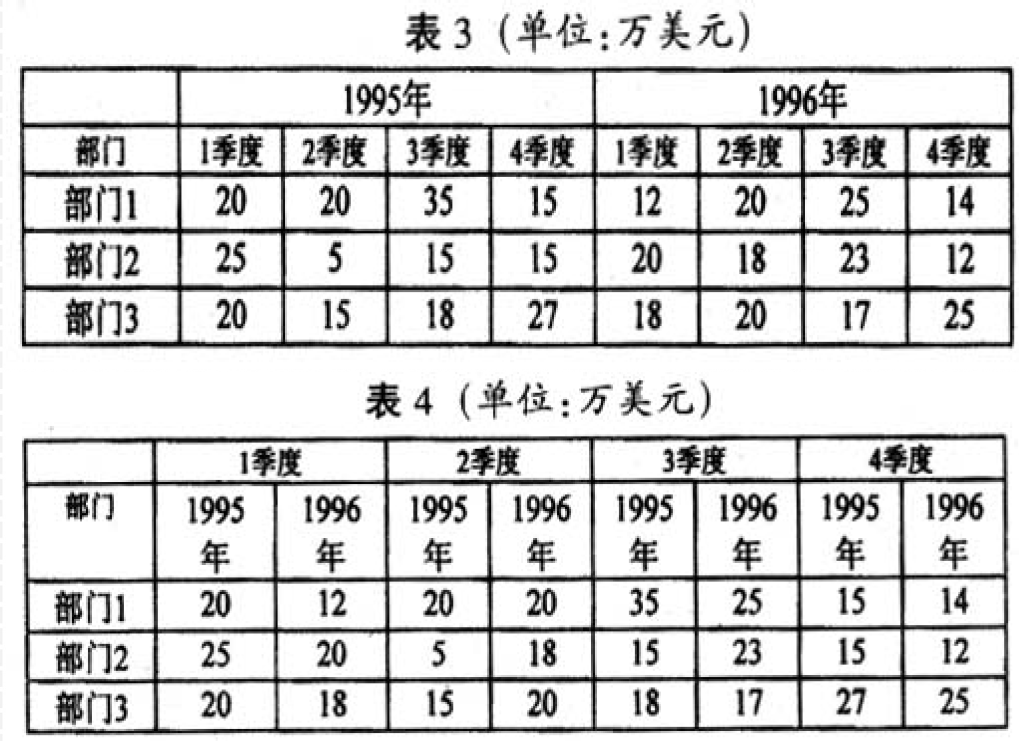
- 旋转(Rotate)/转轴(Pivot):通过旋转可以得到不同视角的数据
5.6.1. 切片、切块
5.6.2. 钻取
5.6.3. 旋转
5.7. 数据仓库的体系结构
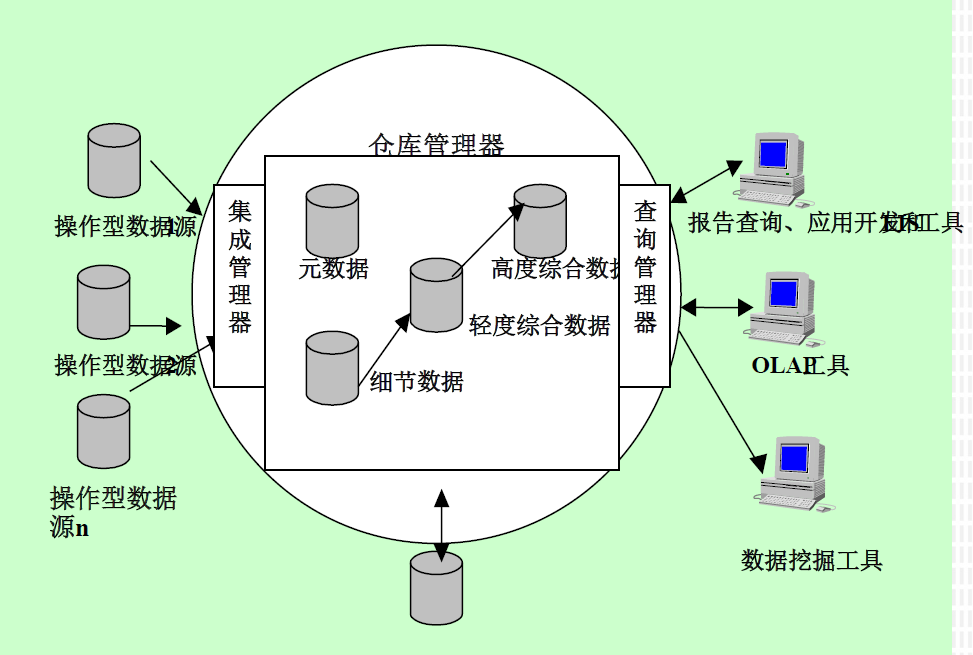
5.8. 数据仓库的元数据
- 管理元数据
- 所有建立使用DW的信息,源数据库
- 综合数据、维、层次信息
- 预定义的查询、报表和数据组织、分段
- 数据抽取、清洗、转换的规则
- 业务元数据
- 业务流程、数据的所有关系和存取控制策略
- 操作元数据
- 运行时管理信息
- 即时数据信息、监测信息
5.9. 数据仓库的数据组织
- 虚拟存储
- 语义层工具转换
- 适用理想状况
- 基于关系表存储
- 模型定义、数据抽取
- 多维数据库存储
- 多维数据文件存储数据
- 维索引管理
5.10. 维表(星型)

5.11. 维表(雪花型)
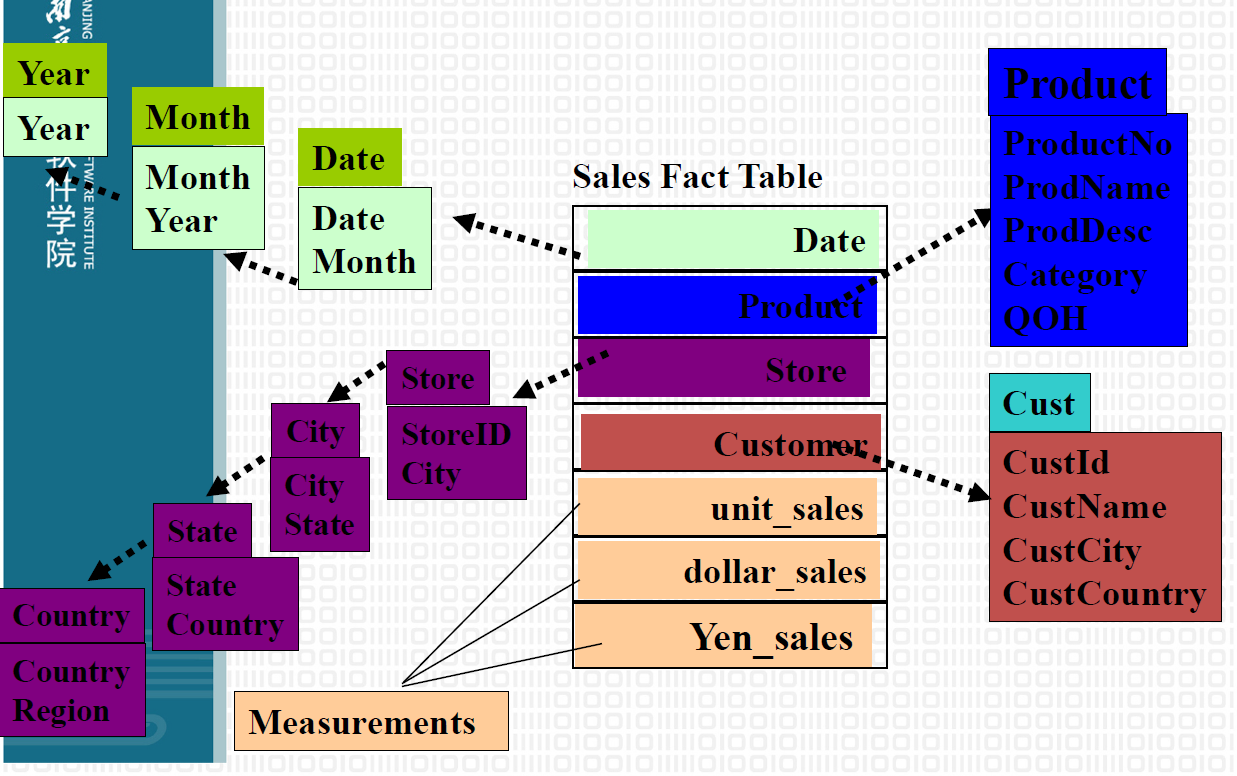
5.12. 数据仓库组成部分
- 数据源
- 数据抽取(extraction)、转换(transformation)和转载(load)工具
- 数据建模工具
- 核心仓储(Central Repository)
- 数据仓库的目标数据库
- 前端数据访问和分析工具
- 数据仓库管理工具
5.13. 体系结构

5.14. 数据集成领域中ETL
- 数据的差异性更大, 不仅是结构化数据, 可能还涉及到半结构数据和无结构数据, 并实现某些情况下的相互转换
- 数据抽取、转换和加载操作往往不在同一个地方, 在抽取和加载之间需要进行数据的远程传输
- 抽取和加载两个操作可能是完全独立的, 分别属于不同的企业或部门,具有高度的自治性
- 在数据仓库中一般只进行数据的增加,而数据集成应用可能还涉及到数据的删除和修改, 保证抽取方和加载方数据的一致性
5.15. ETL的过程
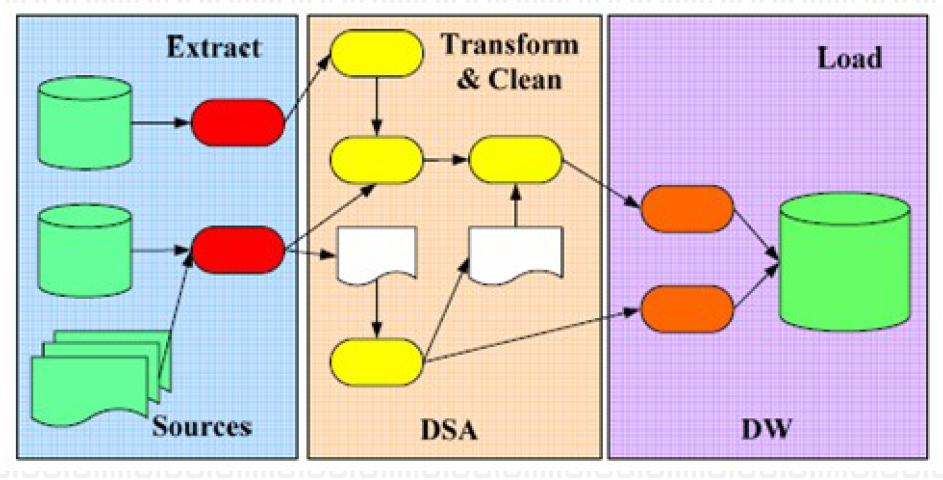
- 抽取、转换和加工、装载
- 节点代表操作:过滤,转变,传输,压缩,加密等
- 增量、转换、调度和监控等处理
5.15.1. 数据的抽取
- 与目标数据库系统相同的数据源:建立链接关系就可以写Select语句直接访问
- 与目标数据库系统不同的数据源
- 通过程序接口来完成
- 将数据导出成txt或者是xls文件,然后再将这些源系统文件导入到ODS中
- 文件类型数据源(txt, xls)
- 全量抽取和增量抽取:增量更新的问题
5.15.2. 数据的清洗
- 数据格式不一致、数据输入错误、数据不完整
- 源数据和目标数据需要进行数据模式或语义映射的转换
- 在数据库中进行数据加工
- 利用数据库本身提供的SQL、函数
- 在SQL查询语句中添加where条件进行过滤
- 重命名字段名与目的表进行映射
- substr函数、case条件判断
- ETL引擎:以组件化的方式实现数据转换:字段映射、数据过滤、数据清洗、数据替换、数据计算、数据验证、数据加解密、数据合并、数据拆分等
5.15.3. 数据装载
- 将转换后的数据装载到目标库
- 最佳方法取决于所执行操作的类型以及需要装入多少数据
- 目的库是关系数据库有两种装载方式
- 直接SQL语句进行insert、update、delete操作,进行了日志记录并且可恢复
- 采用批量装载方法,如bcp、bulk、关系数据库特有的批量装载工具或api,批量装载操作易于使用,并且在装入大量数据时效率较高
5.16. ETL中的关键技术
- 增量复制
- 数据的清洗转换
5.16.1. 增量复制
- 触发器
- 时间戳
- 快照方式
- 日志法
5.16.1.1. 控制表法(触发器)
- 插入、修改、删除建trigger,每当源表中的数据发生变化,就被相应的触发器将变化的数据写入一个临时表
- 控制表(变化表名、操作、主键、时间戳)
1 | |
5.16.1.2. 时间戳
- 一种基于快照比较的变化数据捕获方式
- 在源表上增加一个时间戳字段,系统中更新修改表数据的时候,同时修改时间戳字段的值
- 当进行数据抽取时,通过比较系统时间与时间戳字段的值来决定抽取哪些数据
- 有的数据库的时间戳支持自动更新,即表的其它字段的数据发生改变时,自动更新时间戳字段的值
- 不支持时间戳的数据库则触发器方式
5.16.1.3. 快照方式
- 快照是数据在某个时刻的一个备份
- 在上次发送时保留其快照, 在当前发送时, 可以通过比较当前数据与上次发送时的快照, 得到数据的增加、删除和修改情况
- 将二者的区别按照要求发送出去
5.16.1.4. 根据主键判断
- 当前实视图为New,上次发送时的快照为Old, t为当前实视图中的一条记录
- 若但, 则t是增加数据
- 若但, 则t是删除数据
- 当时, 若且, 但且, 或者且, 则t是修改数据
5.16.2. 数据的清洗转换
- 过滤不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取
- 数据清洗是一个反复的过程,注意不要将有用的数据过滤掉,对于每个过滤规则认真进行验证,并要用户确认
- 数据转换主要进行不一致的数据转换、数据粒度的转换,以及一些商务规则的计算
5.16.2.1. 数据清洗
- 不完整的数据:一些应该有的信息缺失,如供应商的名称、客户的区域信息缺失、业务系统中主表与明细表不能匹配等;过滤出来写入不同Excel文件向客户提交,要求在规定的时间内补全
- 错误的数据:业务系统不够健全,在接收输入后没有进行判断直接写入后台数据库造成的,比如数值数据输成全角数字字符、日期格式不正确、日期越界等;需要去业务系统数据库用SQL的方式挑出来,交给业务主管部门要求限期修正,修正之后再抽取
- 重复的数据:将重复数据记录的所有字段导出,让客户确认并整理
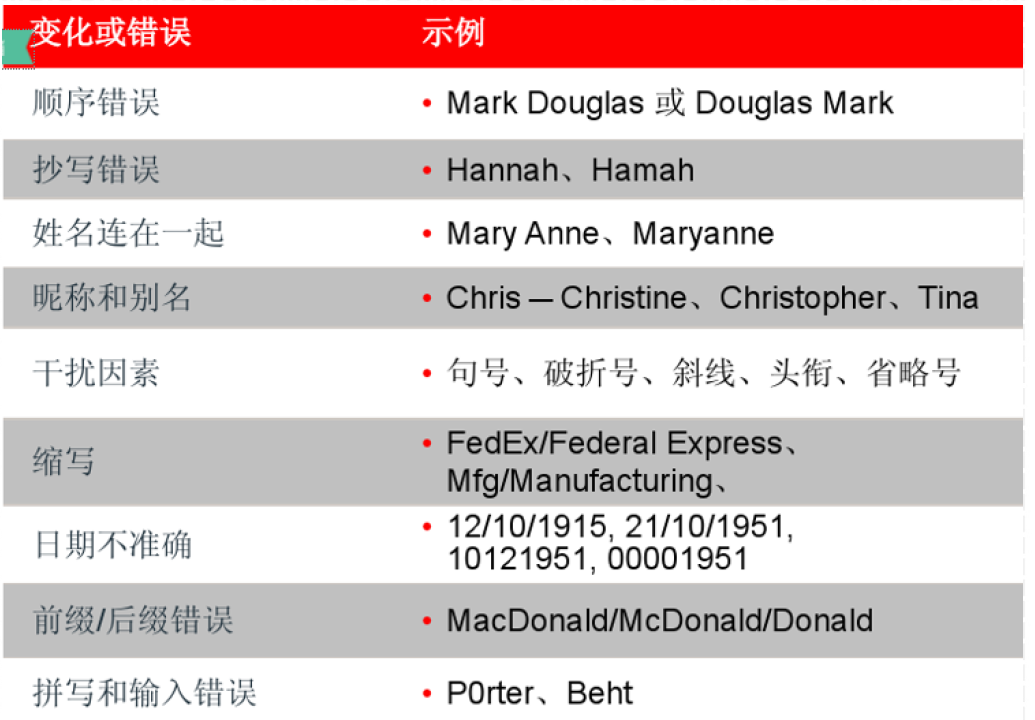
5.16.2.2. 姓名常见的错误和变化
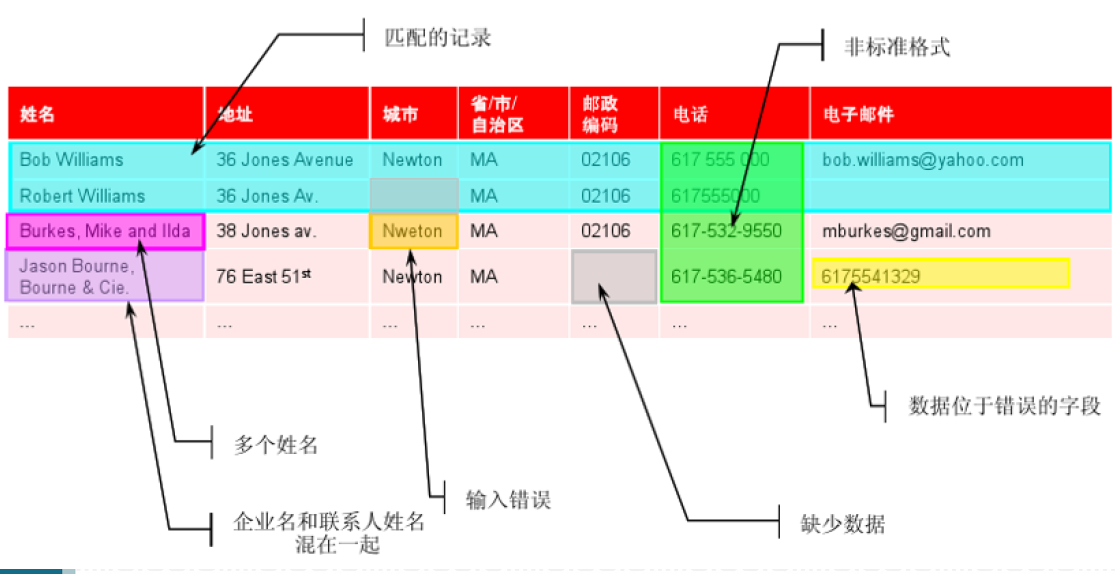
5.16.2.3. 数据质量问题示例
5.16.3. 清理、匹配、标准化
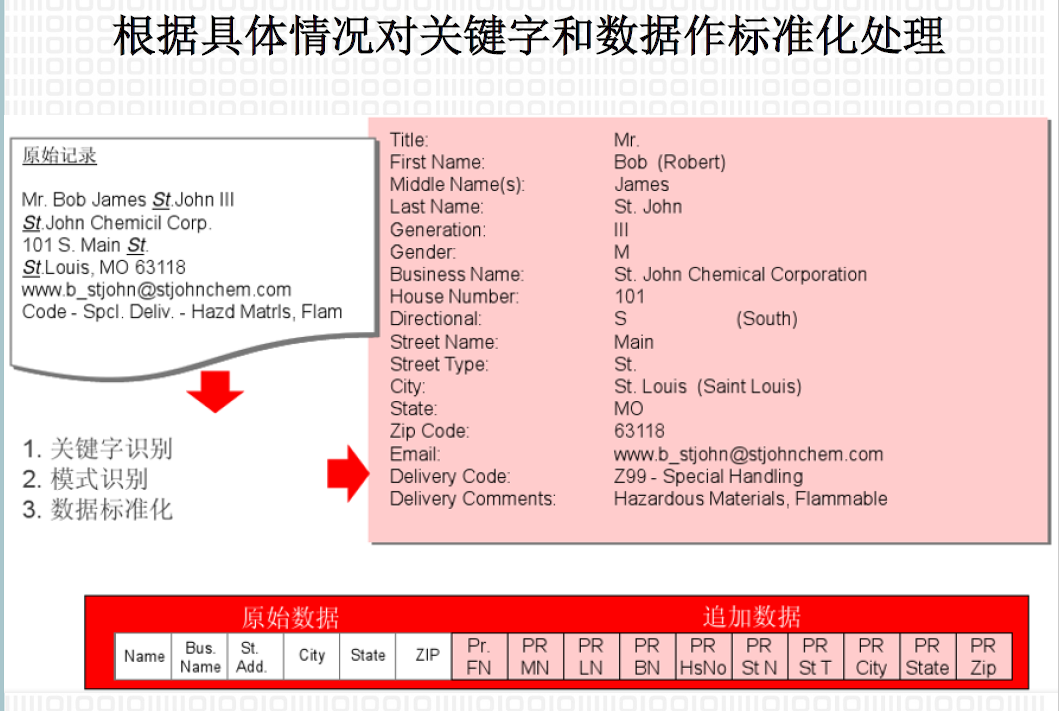
5.16.4. 数据匹配与合并
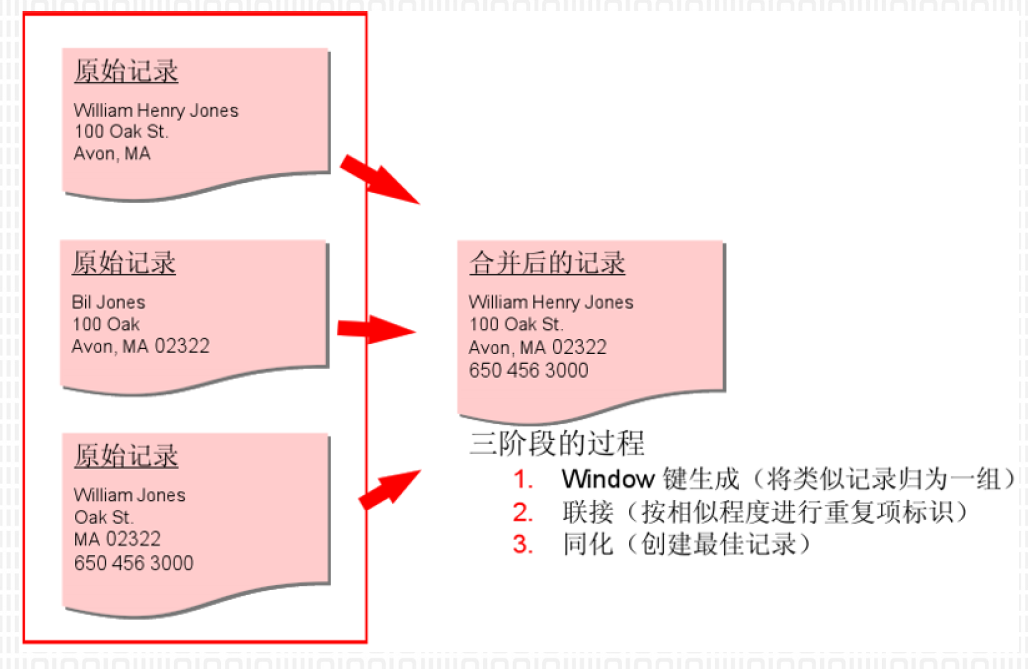
5.17. 数据转换
- 不一致数据转换:将不同业务系统的相同类型的数据统一,如同一个供应商在结算系统的编码是XX0001,而在CRM中编码是YY0001,这样在抽取过来之后统一转换成一个编码
- 数据粒度的转换:业务系统一般存储非常明细的数据,而目标数据是用来分析的,不需要非常明细的数据
- 商务规则的计算:不同的企业有不同的业务规则、不同的数据指标,这些指标有时需要在ETL中将这些数据指标计算后存储在目标数据库中,以供分析使用
5.18. ETL的三种实现方法
- 借助ETL工具:Oracle的ODI,SQL server 的SQL Server Integration Service:可以快速建立ETL工程,屏蔽了复杂的编码任务,提高的速度,降低的难度,但是缺少灵活
- SQL方式实现:灵活,提高ETL运行效率,但是编码复杂,对技术要求比较
- ETL工具和SQL相结合
5.19. 提高ETL的性能
- 如果条件允许利用数据中转区对运营数据进行预处理,保证集成与加载的高效性
- 如果ETL的过程是主动"拉取",而不是从内部"推送",其可控性将大为增强
- ETL之前应制定流程化的配置管理和标准协议
- 关键数据标准至关重要
5.20. 实施ETL的例子
- 往oracle数据库中插入excel文件中的数据
6. 基于XML的数据集成
- 整个系统位于异构数据源和应用程序之间,向下协调各种数据源,向上为访问集成数据的应用提供了统一的模式和访问的通用接
- 数据抽取层
- 中介层
- 用户接口层
6.1. 系统结构
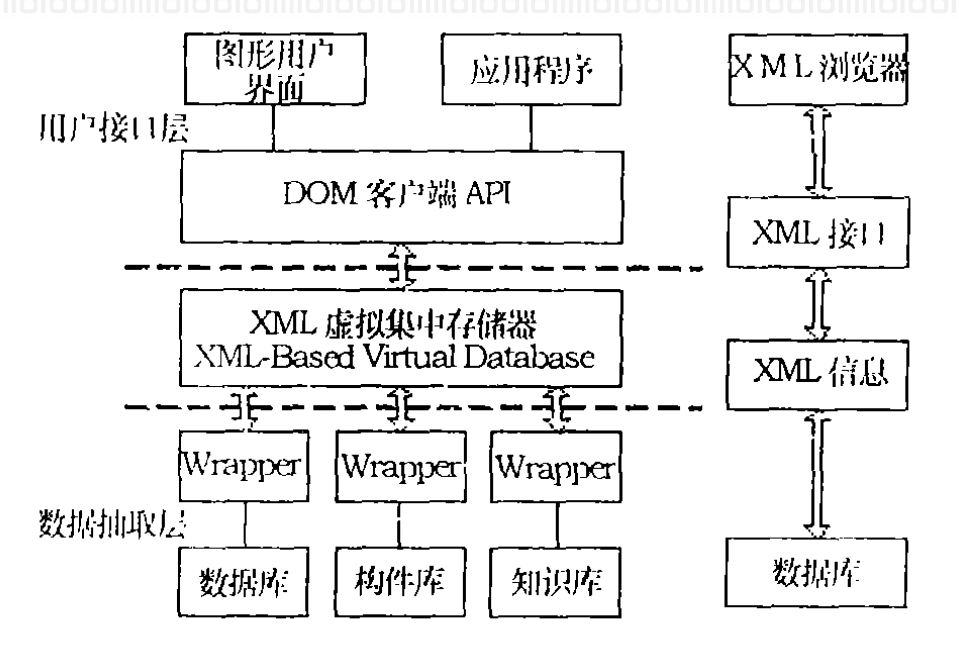
6.2. 数据抽取层
- 处于系统的最低层,是系统的数据提供者
- 提取和集成分布在多个异构数据源(数据库,知识库及构件库) 上的数据
- 采用Wrapper (包装器) 技术实现将一个从中介层得到的查询,翻译成能在经过封装的数据源上执行的操作,将查询结果抽取并打包到一个XML 文档,最后将该文档返回给中介层
6.3. 中介层
- 一方面对上接受用户通过DOM(Document Object Model ,文档对象模型客户端API 向系统提交的或应用程序发出的查询,将其转换成对XML 的查询,并将查询结果返回给用户或应用程序
- 另一方面对下将XML 查询分发给各个包装器,并将查询结果通过DTD 说明再转换成XML 格式
6.4. 用户接口层
- 用户接口层(User Interface Layer) 在中介层之上,负责将用户的查询命令提交给中介层,获得并解释查询结果,并将结果显示给用户
- 定义了XML文档的逻辑结构,访问及操作方法。由于数据显示与内容分开,XML 定义的数据允许指定不同的显示方式,使数据更合理的表现出来
- 本地的数据能够以客户配置,使用者选择或其他标准决定的方式动态的表现出来
2021-数据集成-Lec3-数据集成框架
https://spricoder.github.io/2021/05/01/2021-Data-Integration/2021-Data-Integration-Lec3-%E6%95%B0%E6%8D%AE%E9%9B%86%E6%88%90%E6%A1%86%E6%9E%B6/