2021-数据集成-数据集成与大数据
Big Data & Data Integration
1. PC -> (移动)互联网

2. 移动互联网迅猛发展
- 移动互联网的到来以及用户行为习惯的变化 -> 新的应用模式、商业模式、营运模式
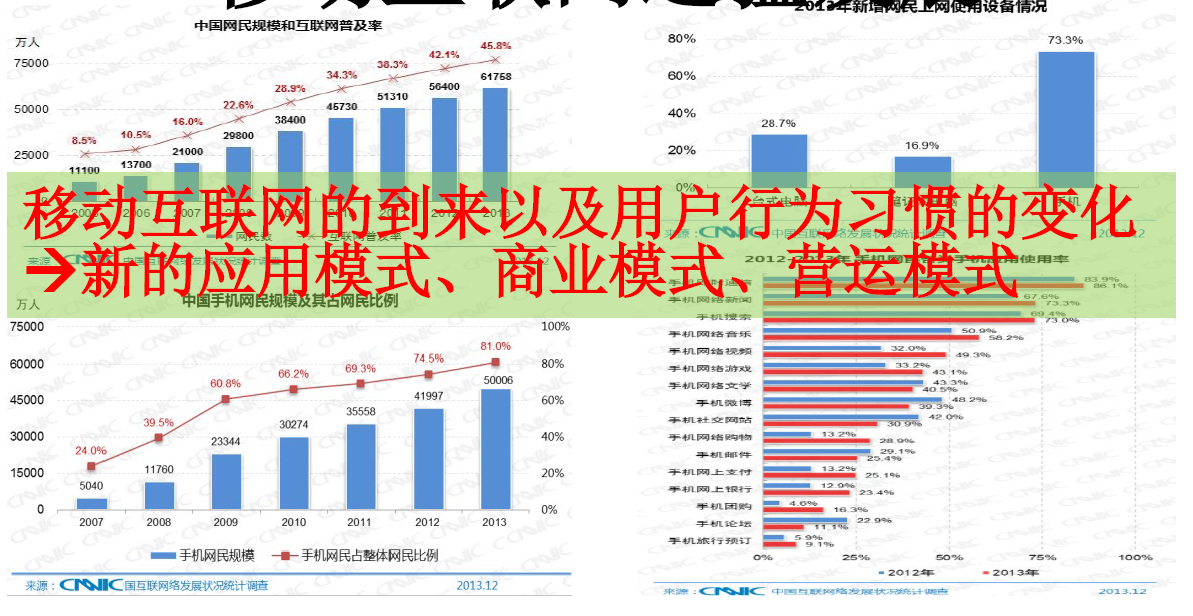
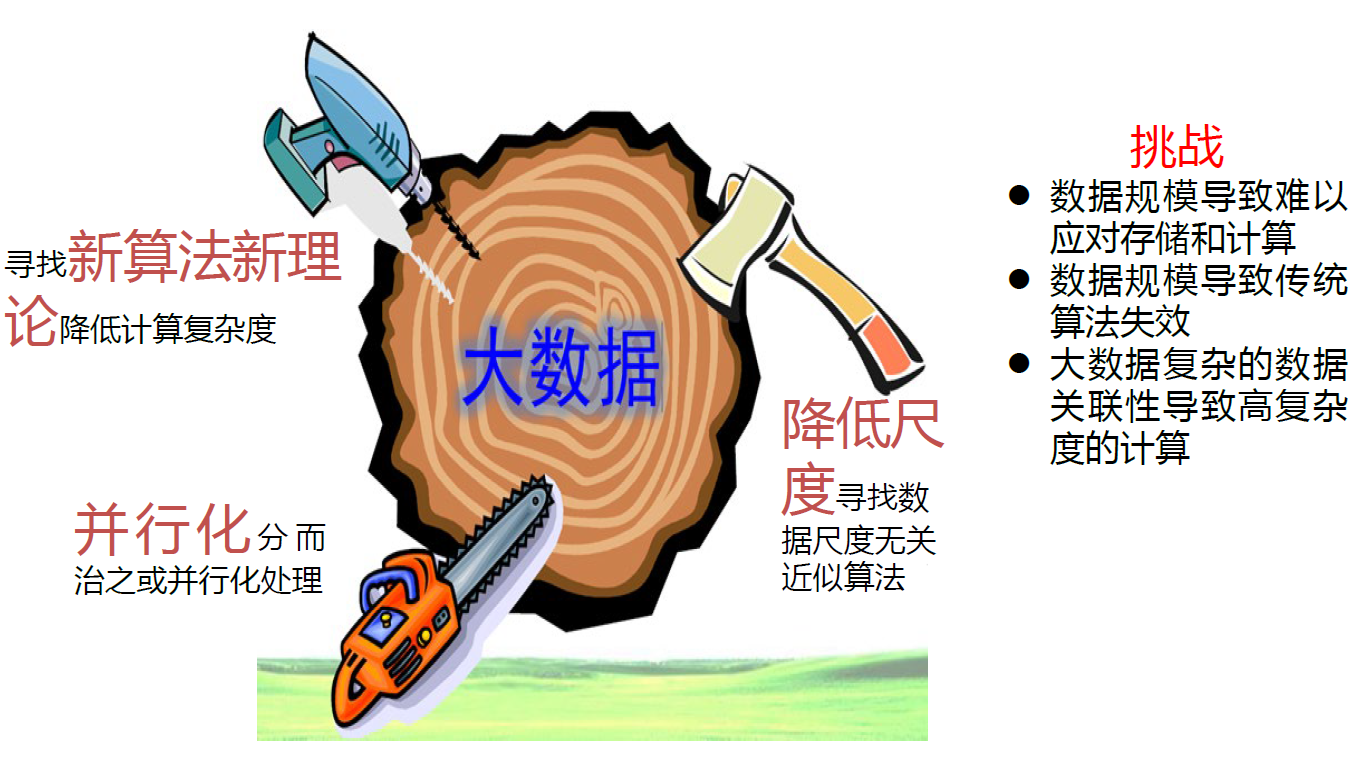
3. 大数据时代
- 移动互联网产生大数据大数据优化移动互联网
- 之前的那段历史很精彩之后的未来需要想象力
4. 生活在数据海洋中
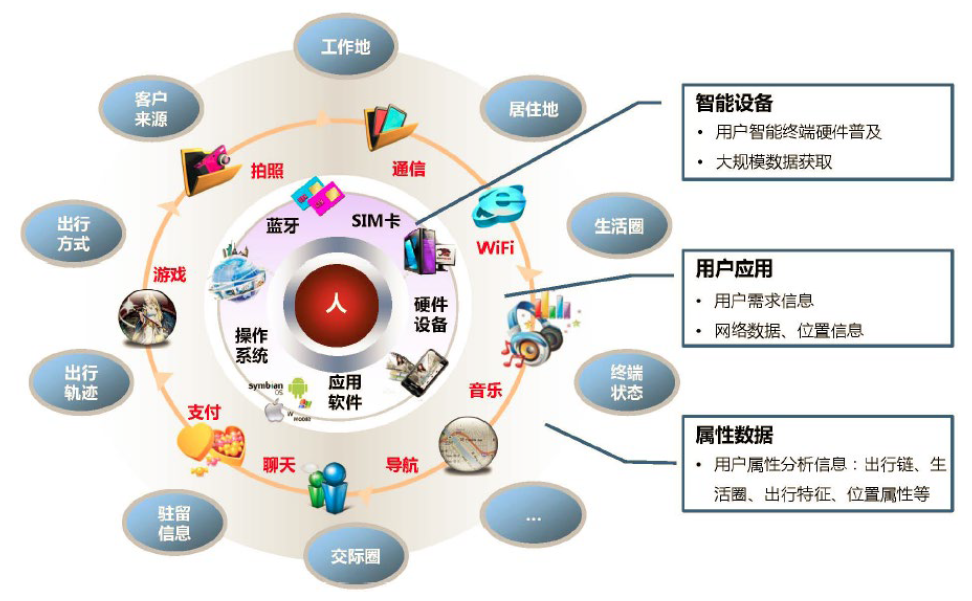
5. 互联网的1分钟
- 传送数据约640TB
- 发布2亿400万封邮件
- 下载4.7万个App
- 亚马逊卖出8.3万美元的货物
- Youtube视频被查看了130万次
- Facebook被查看了600万次、Pandora电台播放了总计6.1万小时的歌曲
6. 大数据事实
- 互联网每天产生1EB =1024PB
- 人类生产的所有印刷材料的数据量200PB=1024TB
- 人类全部数据中,有90%是最近两年内产生的
- 互联网数据平均每2年翻一番
- 还有更多数据无法估量:数据存量越来越大|数据种类越来越多|数据产生越来越快|数据价值越来越大
7. 大数据角力-产界
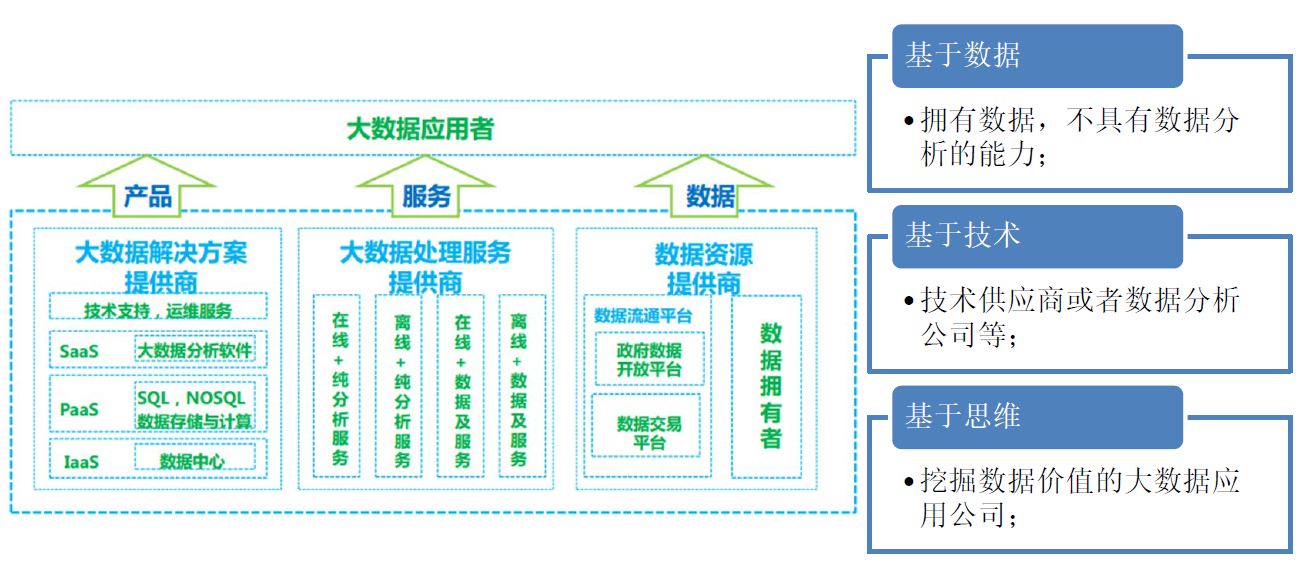
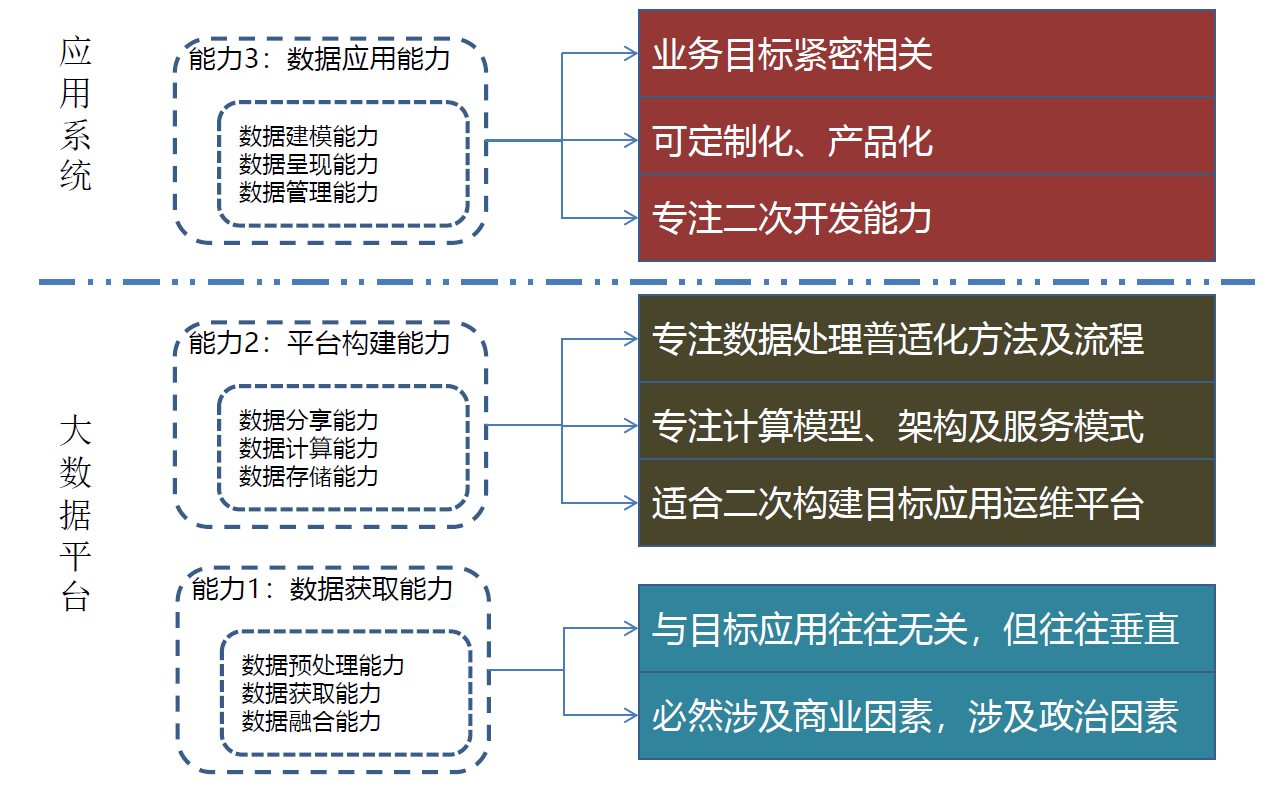
8. 大数据流程
8.1. 物联网思路复用(第一层次)
- 富集和整合目标应用各类数据
- 开发面向目标应用的分析套件
- 开发面向目标应用的运维系统

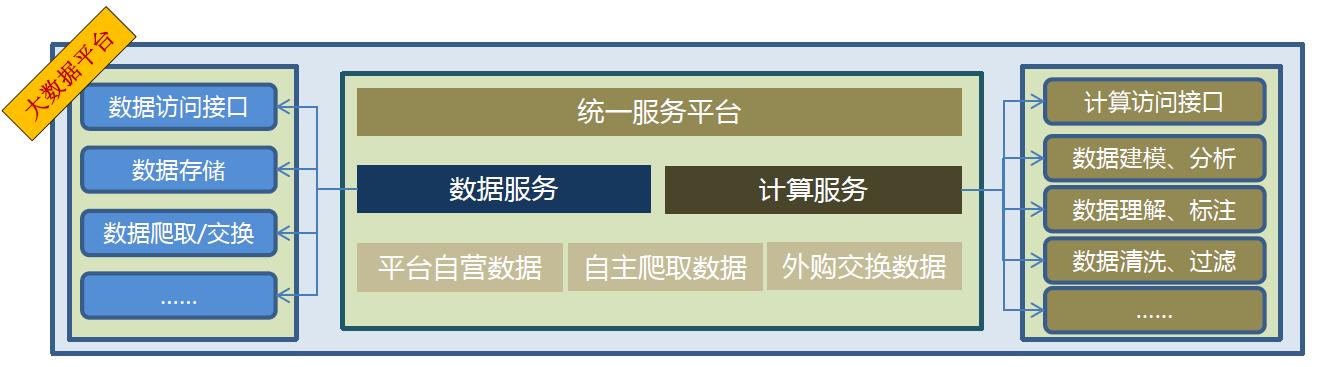
8.2. 数据交叉复用(第二层次)
- 构建数据平台,提供数据服务
- 构建计算平台,提供计算服务
- 开发统一服务平台,提供面向细分应用的开发平台
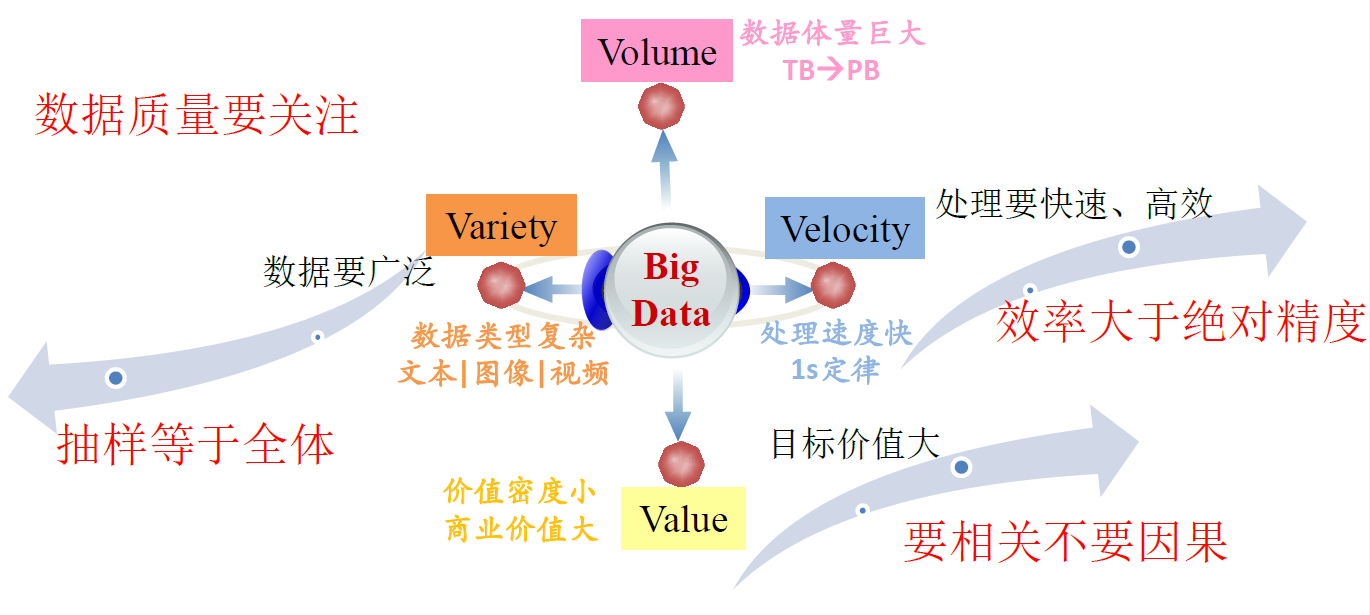
9. 大数据的4V特征
9.1. 数据交叉复用
- 大数据的终极目标是从大量的、复杂的数据集合中获取知识和洞见
- 大数据的价值特点
- 数据是知识的载体数据是有价值的
- 单一数据都是反映某个方面的,意味单一数据价值是低的
- 数据量太大价值密度稀疏的
- 集成思维充分利用数据的互补性
- 数据交叉复用化
- 数据是有价值的
- 同一数据可以被多次循环使用
- 同一数据可以为多个目标应用
- 同一数据与多个其他数据搭配
- 应用
- 大数据运用在基因工程
- 大数据运用在物联网
- 大数据运用在经济
- 大数据运用在社会学
9.2. 抽样=全体
- 样本量相同的情况下,置信水平越高,置信区间越宽
- 置信水平相同的情况下,样本量越多,置信区间越窄
- 置信区间不变的情况下,样本量越多,置信水平越高
- 数学思维样本量多到无穷,置信区间窄到0,置信水平高为1
- 问题可能出在哪里?
- 没有更大的数据支撑,归纳出不合理的结论
- 或者有知识和经验支撑,也能解决这个问题
- 厚数据的盼望
9.3. 效率大于绝对精度
- 大数据时代学会拥抱混乱
- 大数据的简单算法比小数据的复杂算法更有效
- 一个简单的算法,在数据只有500万时表现得很差,但是数据到达10亿时,它变成了表现最好的,而一个在少量数据下运行最好的算法,却变成了在大量数据条件下运行得最不好的
- 谷歌语料库的内容来自于未经过滤的网页内容,所以会包含一些不完整的句子、拼写错误等各种错误,从某种意义上说,是布朗语料库的一个退步。谷歌语料库是布朗语料库的几百万倍大,这样的优势压倒了缺点,使得谷歌的自然语言处理表现更优秀
9.4. 相关性甚于因果性
- 大数据的终极目标是从大量的、复杂的数据集合中获取知识和洞见
- 能够发现因果关系或许很(更)好,不能发现因果
- 不得已而为之相关性发现易于因果性发现
- 已经有用相关性也是知识和洞见
- 技术铺垫相关性的发现为因果发现提供支撑
- 科学伦理不允许带有歧视的视角理解数据
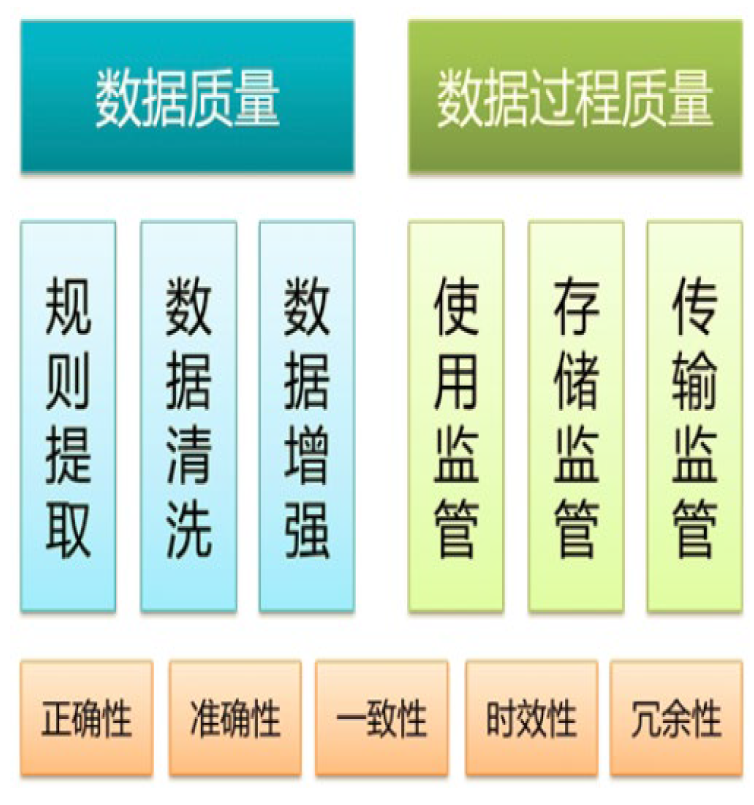
9.5. 数据质量溯源
- 任何数据都是有价值的,质量无优劣之分
- 数据质量监管思维必须贯穿数据生命周期
- 数据源的可信性及采集方法的正确性,即数据本身质量
- 数据分析流转中误差传递及错误迭代,即数据过程质量
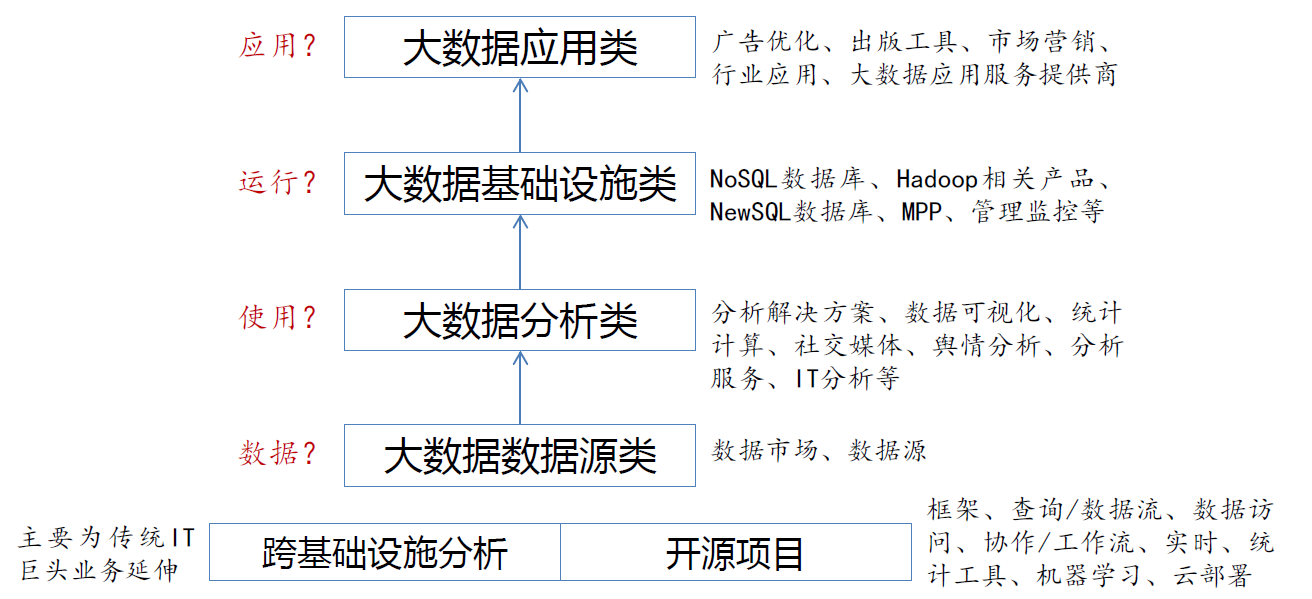
10. 大数据产业
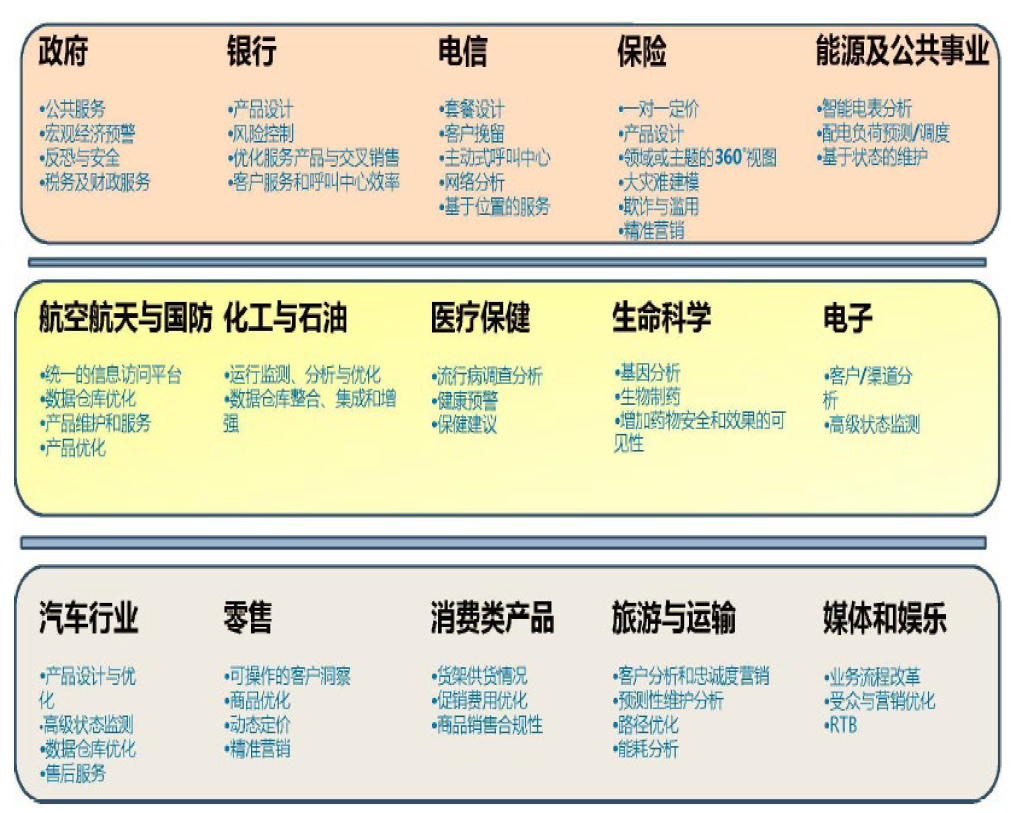
11. 大数据角力
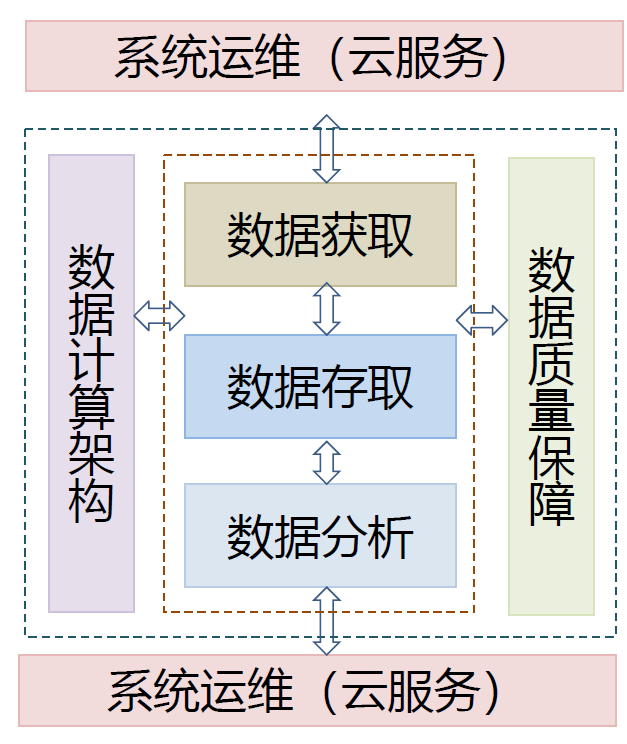
12. 大数据技术框架
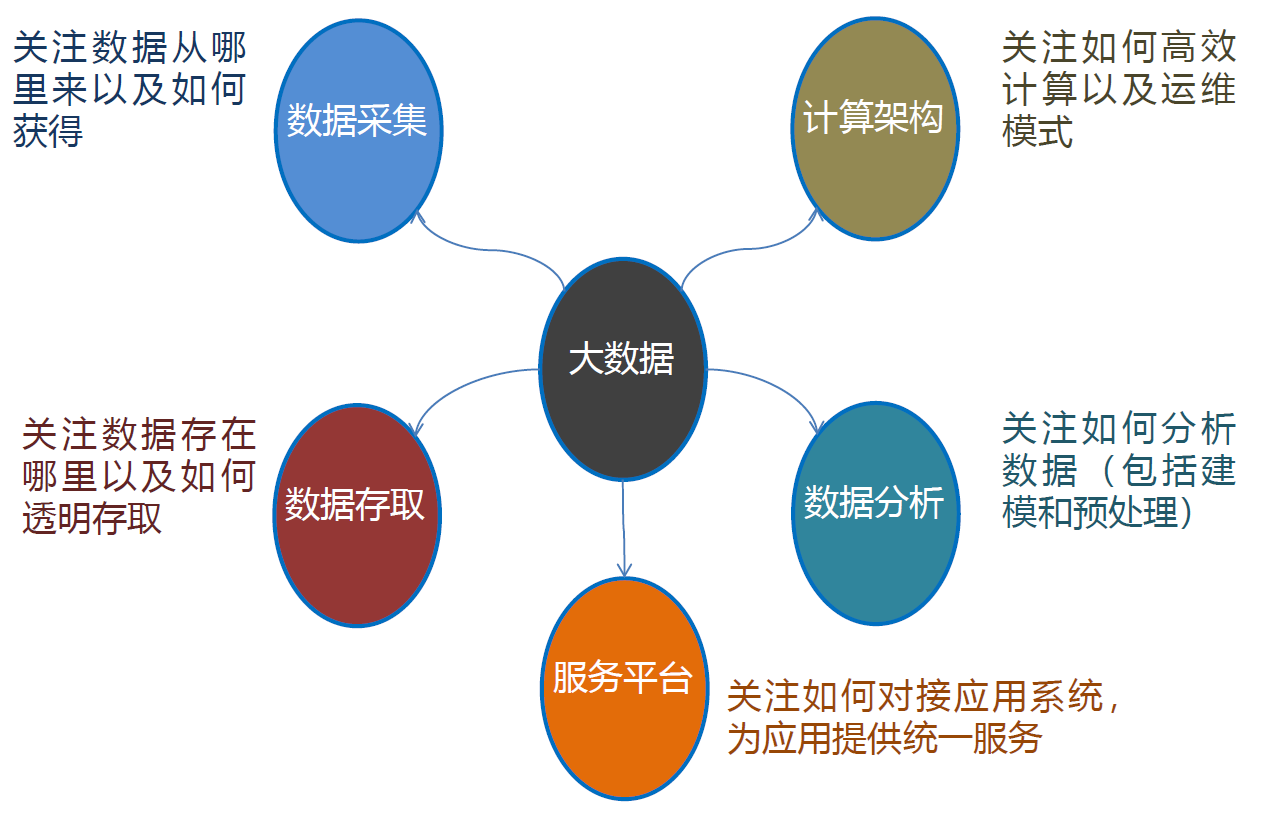
12.1. 数据采集层
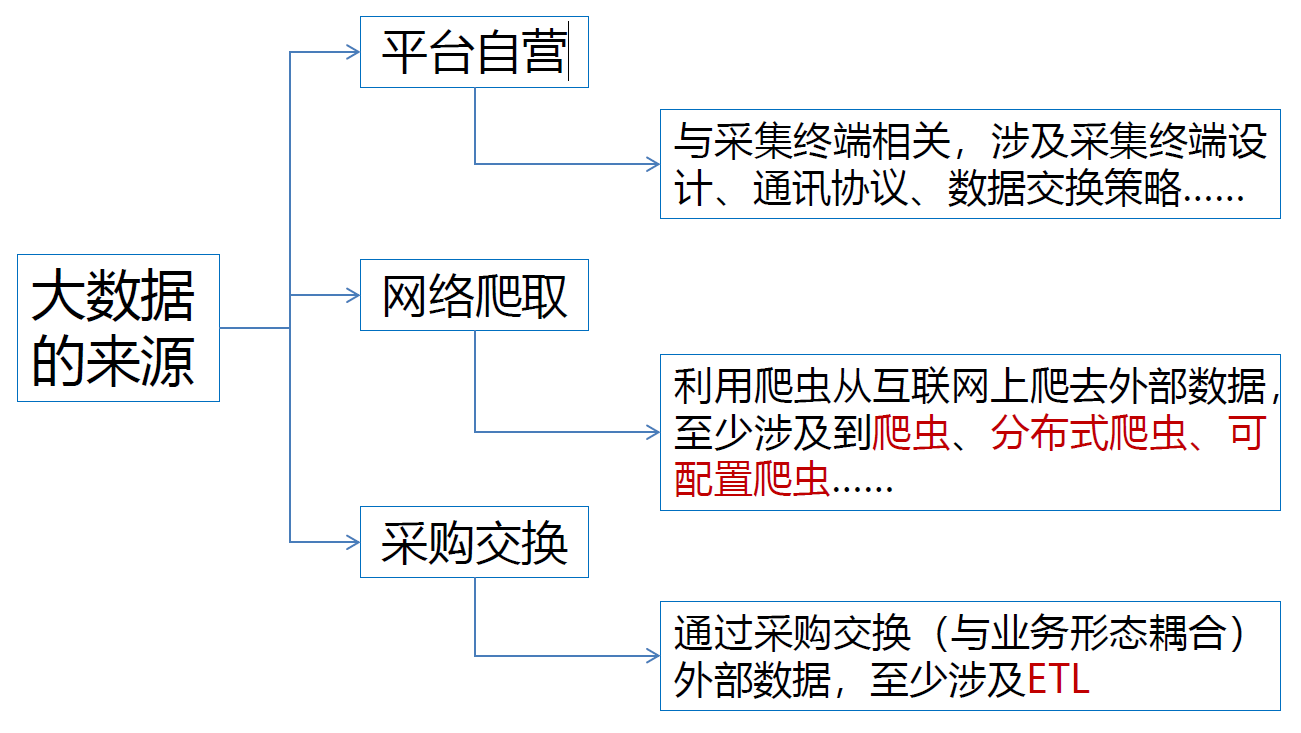
- ETL描述将数据从来源端经过萃取(Extract)、转置(Transform)、加载(Load)至目的端的过程
- 主流工具有:Informatica、Datastage、OWB、微软DTS、Beeload、Kettle
- 大数据环境下:ELT
12.1.1. 爬虫

12.1.2. 分布式爬虫
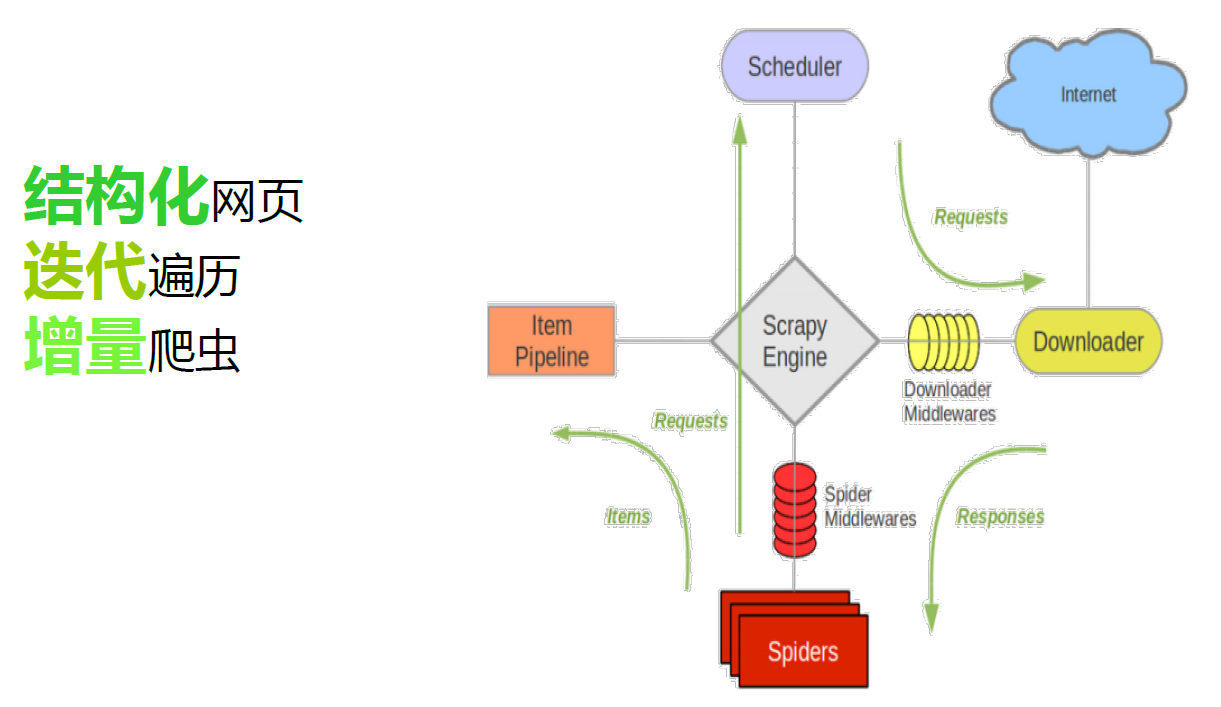 |
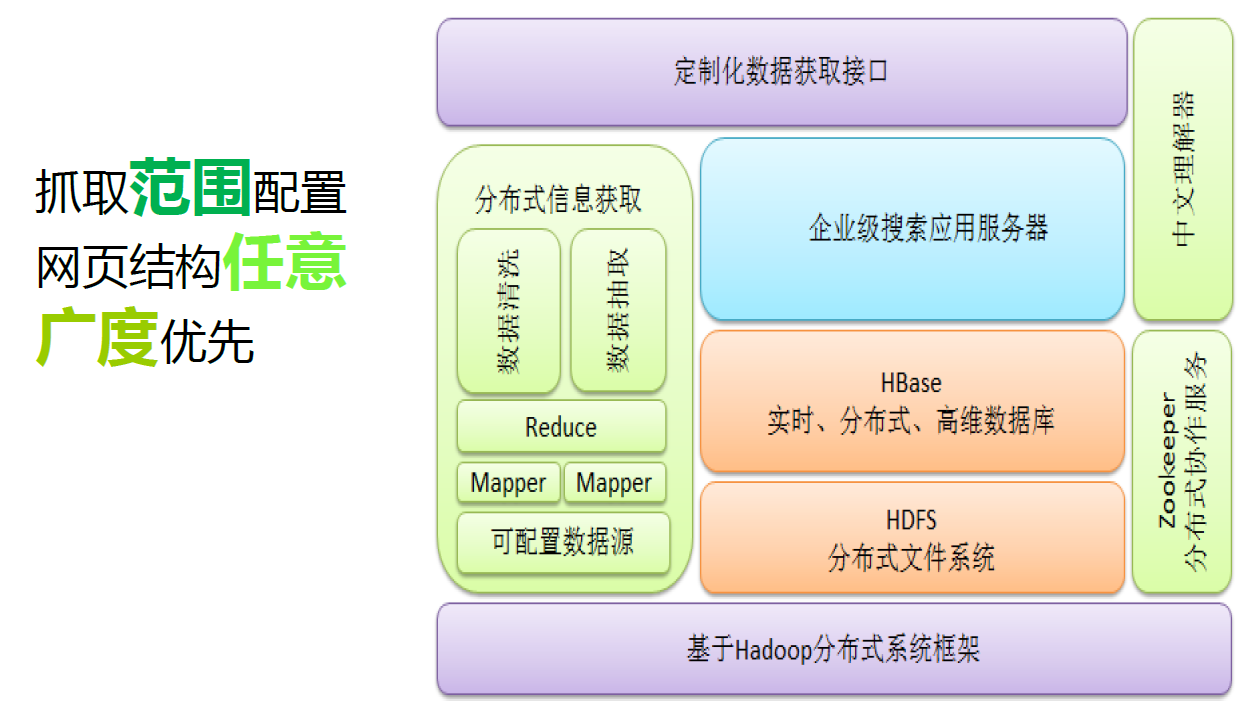 |
|---|
12.2. 数据存取层
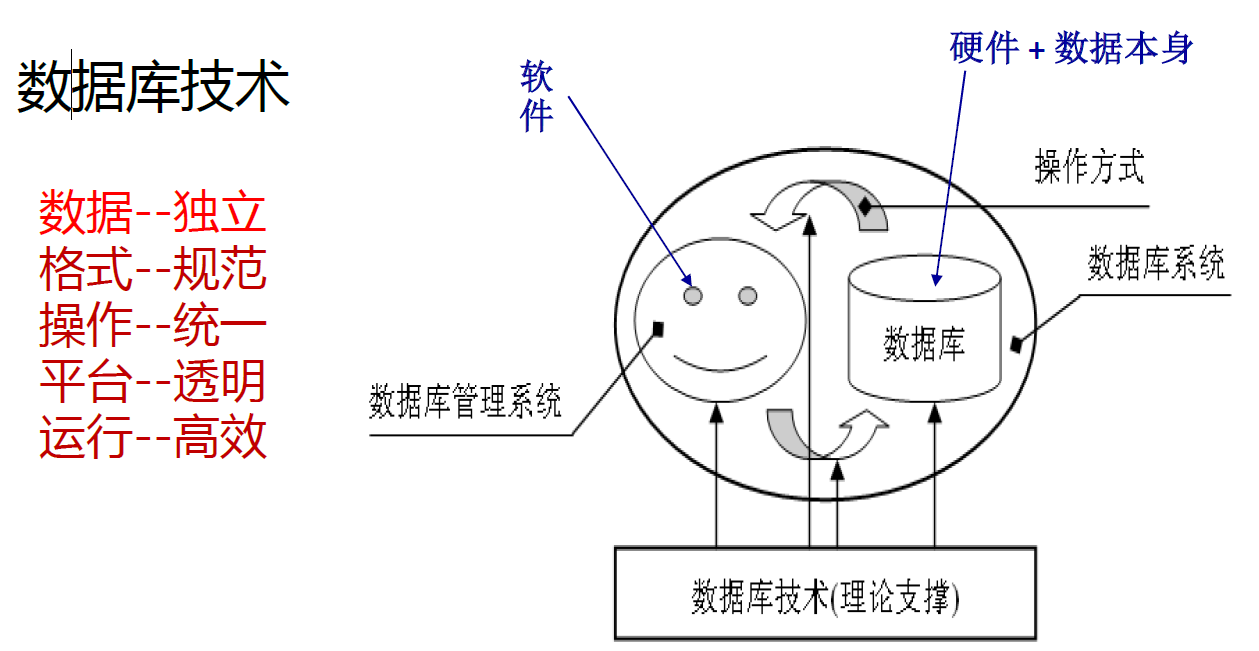
- 基于关系数据结构、关系操作集合、关系完整性约束的关系型数据库目前的热点:内存计算、软硬件一体化、列存储……
- 此外,适合大数据环境的新型数据库得到关注
- NoSQL,泛指非关系型的数据库
- 易扩展
- 高性能
- 数据模型灵活
- 高可用性

- 图形数据库(graphic database)是利用计算机将点、线、画霹图形基本元素按一定数据结同灶行存储的数据集合

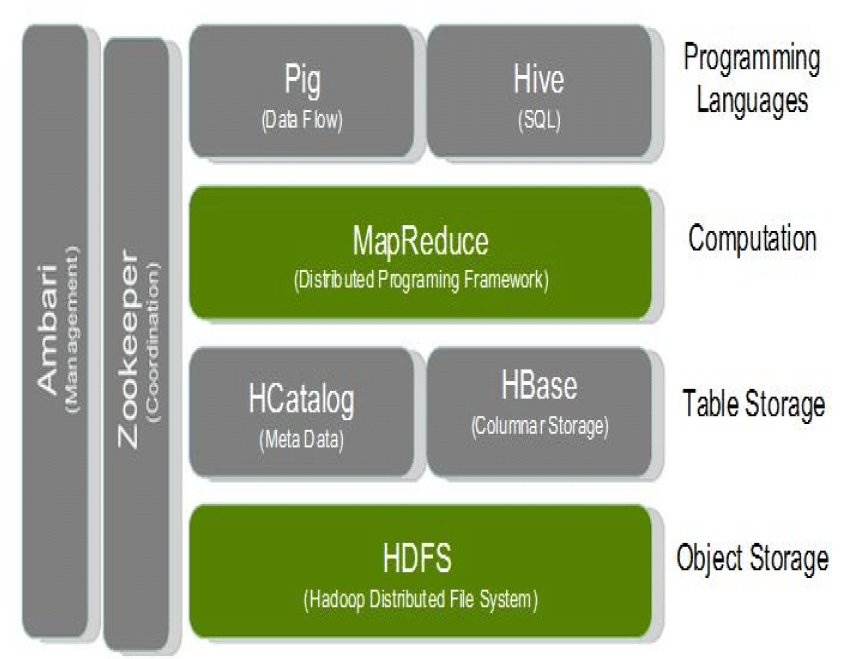
- Hadoop实现了一个分布式文件系统HDFS;
- HBase是一个分布式的、面向列的开源数据库;
- Hcatalog是apache开源的对于表和底层数据管理统一服务平台
- MapReduce并行计算框架;
- Hive数据仓库工具;
- Pig高级过程语言,查询大型半结构化数据集;
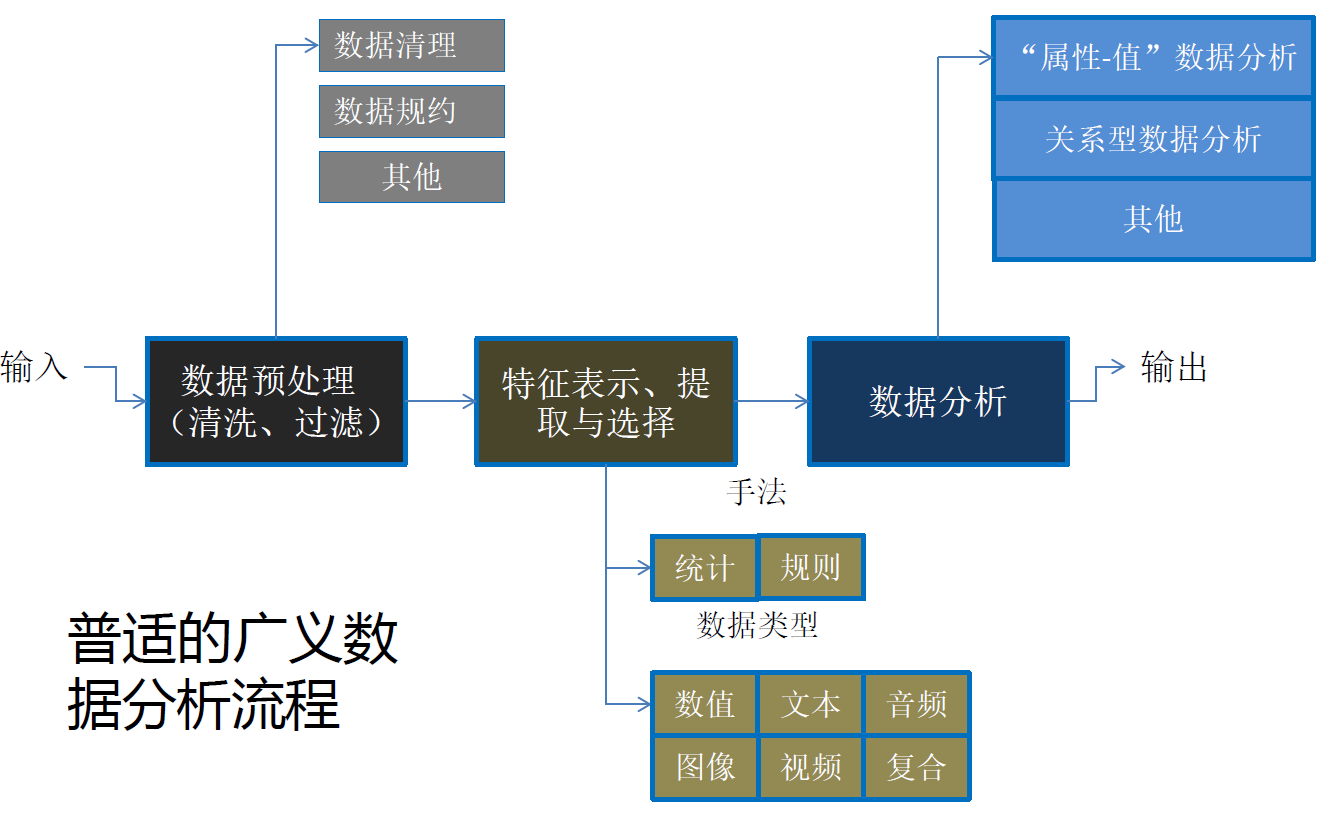
12.3. 数据分析层
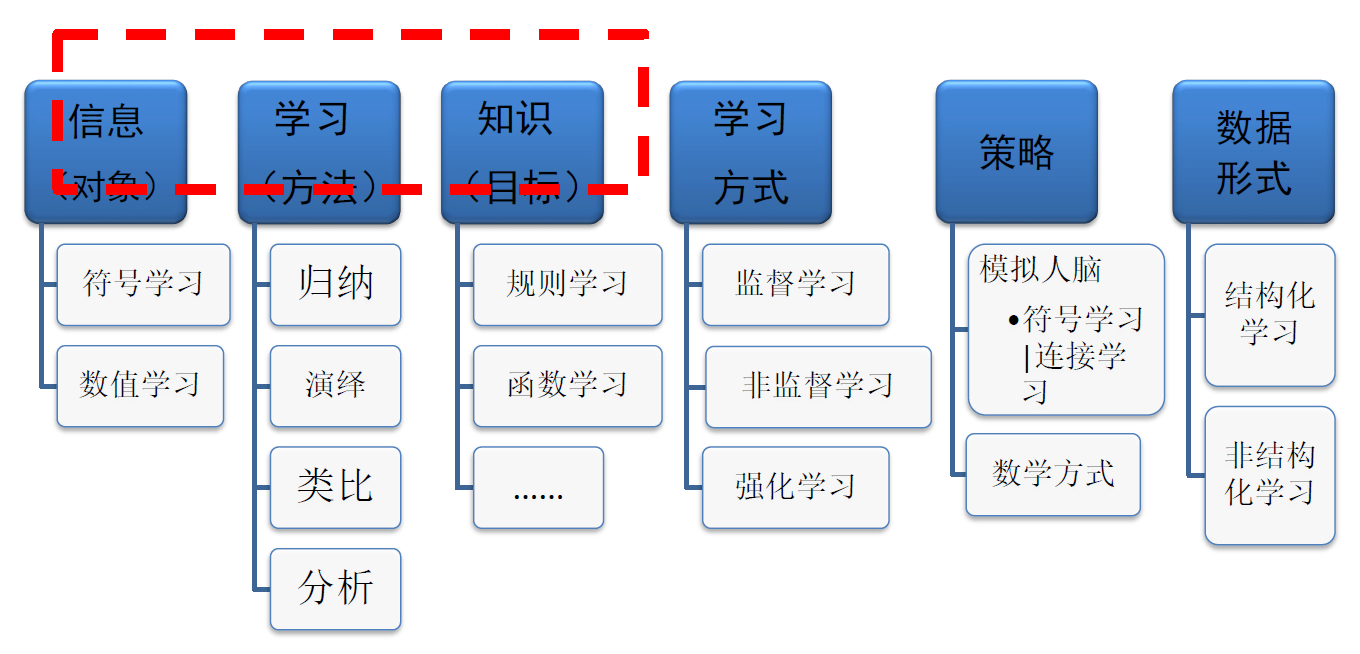
- 心理学中对学习的解释是学习是指(人或动物)依靠经验的获得而使行为持久变化的过程
- 百家争鸣,各有说法
- Simon认为:如果一个系统能够通过执行某种过程而改进它的性能,这就是学习
- Minsky认为:学习是在人们头脑中(心理内部)进行有用的变化
- TomM.Mitchell对于某类任务T和性能度P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么,我们称这个计算机程序从经验E中学习
- 技术层次:通过分析,从大量数据中寻找其规律的技术
- 商业层次:按企业既定业务目标,对大量的企业数据进行探索和分析,揭示隐藏的、未知的或验证已知的规律性,并进一步将其模型化的先进有效的方法

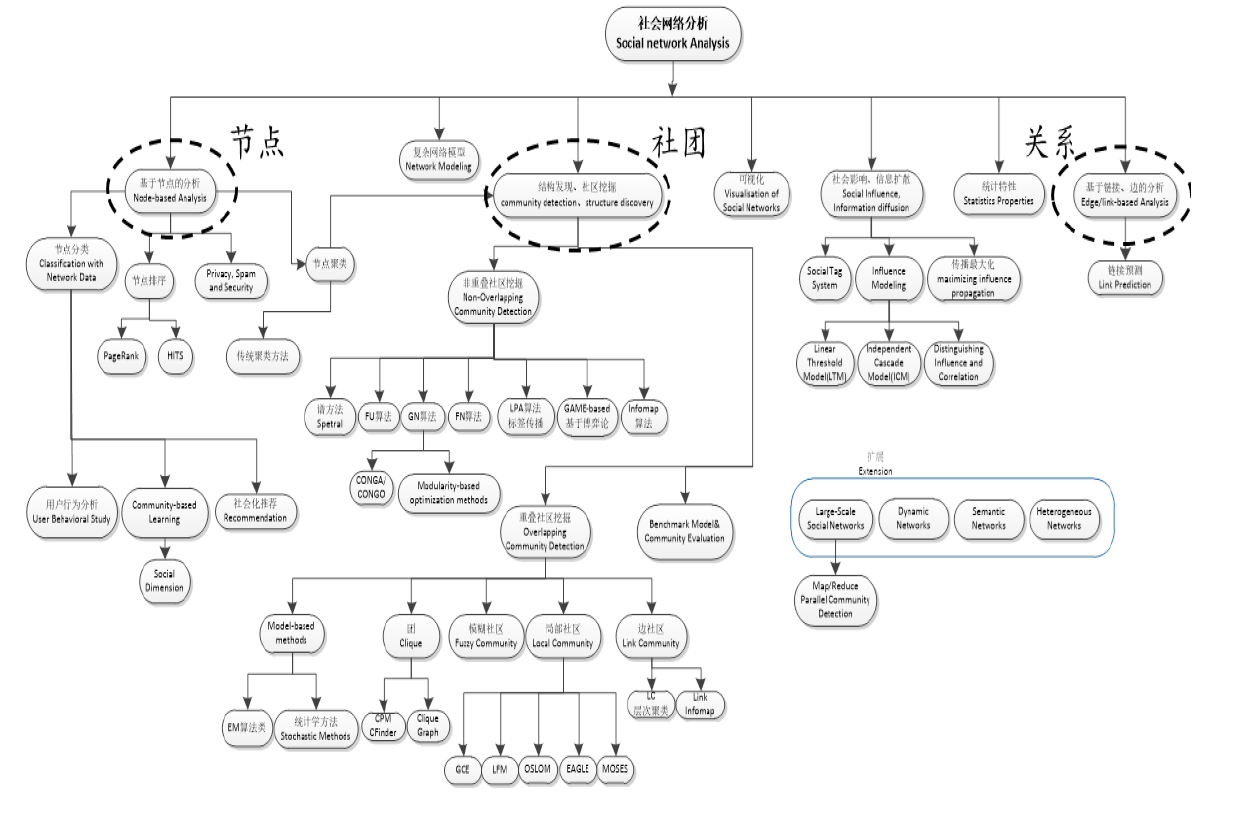
- 社会网络指的是社会行动者及其间的关系的集合,强调每个行动者都与其它行动者有或多或少的关系
- 社会网络分析者建立这些关系的模型,力图描述群体关系的结,研究这种结构对群体功能或者群体内部个体的影响
- 社会网络的研究起源于上世纪二三十年代英国人类学的研究
12.4. 计算架构层
- 并行计算模型:屏蔽并行计算底层细节,使得开发人员在不会分布式计算和分布式系统的情况下,便捷地开发基于并行计算的应用。
- 主流产品
- Hadoop MapReduce
- Spark
- Storm
- MapReduce是一种用于大规模数据集的并行运算模型,特点在于分而治之,包括两个步骤
- Map:简单说来,一个映射函数就是对一些独立元素组成的概念上的列表的每一个元素进行指定的操作。
- Reduce:对Map产生的元素,按一定的规则进行合并操作

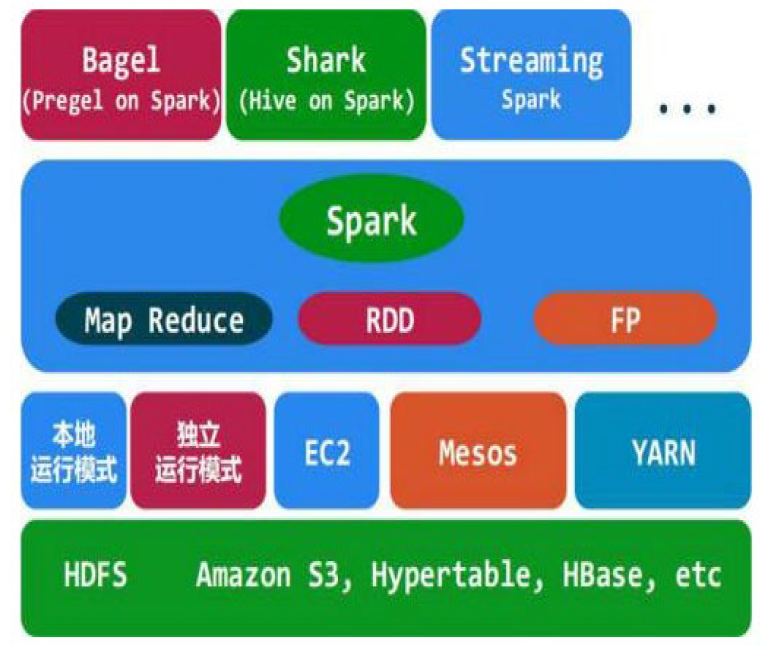
- Spark
- 基于MapReduce算法实现的分布式计算,拥有类似Hadoop MapReduce所具有的优点
- 中间输出结果可以保存在内存中,不需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法
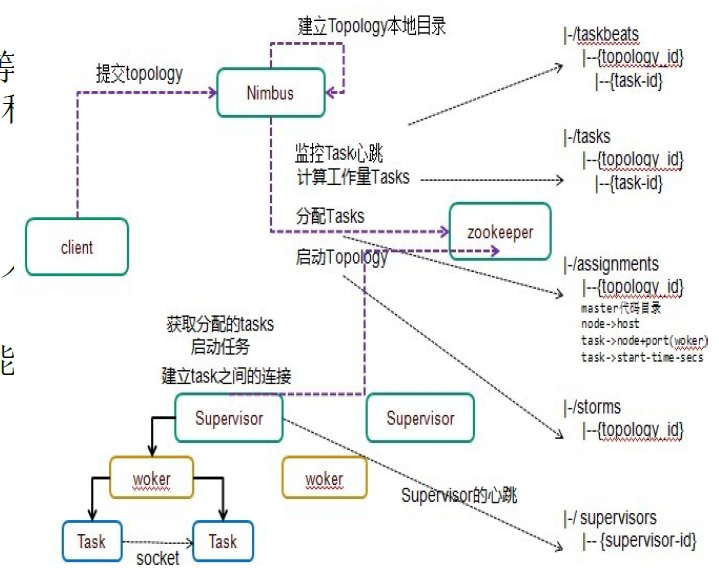
- Storm
- 类似Hadoop的编程计算模型,可以方便地在一个计算机集群中编写与扩展复杂的实时计算
- 默认支持Java、Ruby和Python等
- 容错性:Storm会管理工作进程和节点的故障
- 水平扩展:计算是在多个线程、进程和服务器之间并行进行的
- 可靠的消息处理:Storm保证每个消息至少能得到一次完整处理
- 快速:系统的设计保证了消息能得到快速的处理
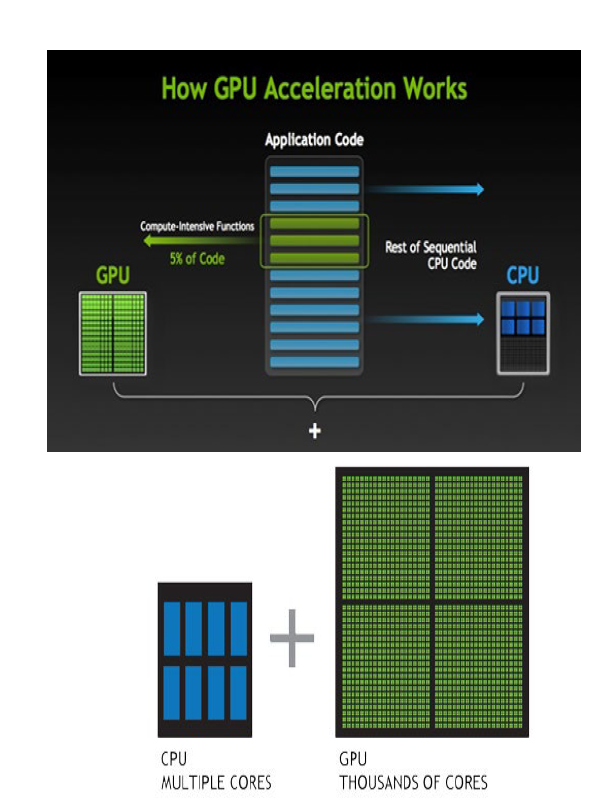
- GPU高性能计算
- GPU 加速是利用一颗图形处理器以及一颗CPU 来加速科学、工程以及企业级应用程序。
- CPU 由专为顺序串行处理而优化的几个核心组成。另一方面,GPU 则由数以千计的更小、更高效的核心组成,这些核心专为同时处理多任务而设计。
- GPU计算适用于:计算密集型的程序,易于并行的程序
12.5. 服务平台层
- 以服务为核心的价值体系
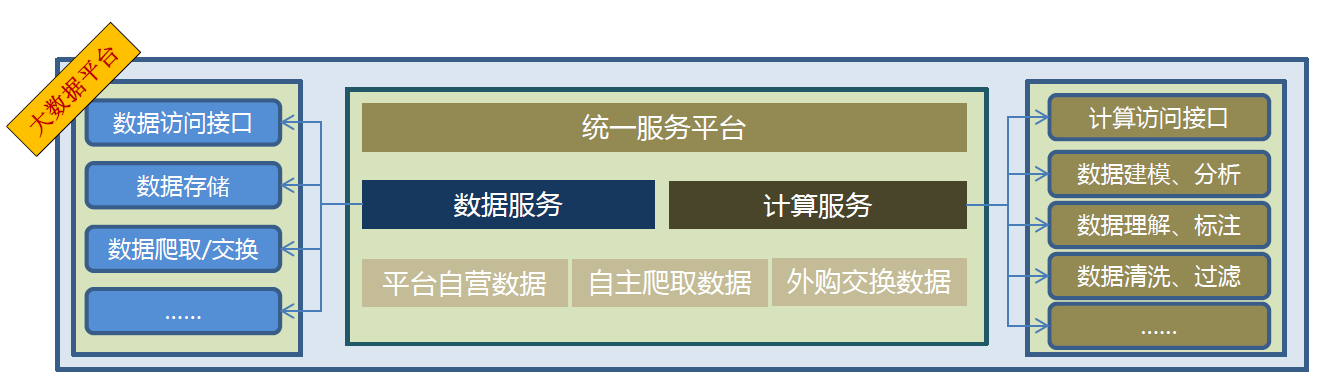
- 是SOA技术在消除商业服务与信息支撑技术之间的横沟方面的直接产物
- SOA(Service Oriented Architecture,面向服务的体系架构),解决的是技术平台和架构的问题
- Web服务、网格/效用计算(Grid & Utility Computing),解决是服务交付的问题
- 业务流程整合及管理(Business Process Integration & Management),解决的是业务本身的整合和管理
12.6. 数据质量层
云计算
- 计算分布在大量的分布式计算机上(未必是本地),并通过计算能力虚拟化和数据虚拟化根据需求弹性分配资源。是分布式处理、并行处理和网格计算的的商业实现
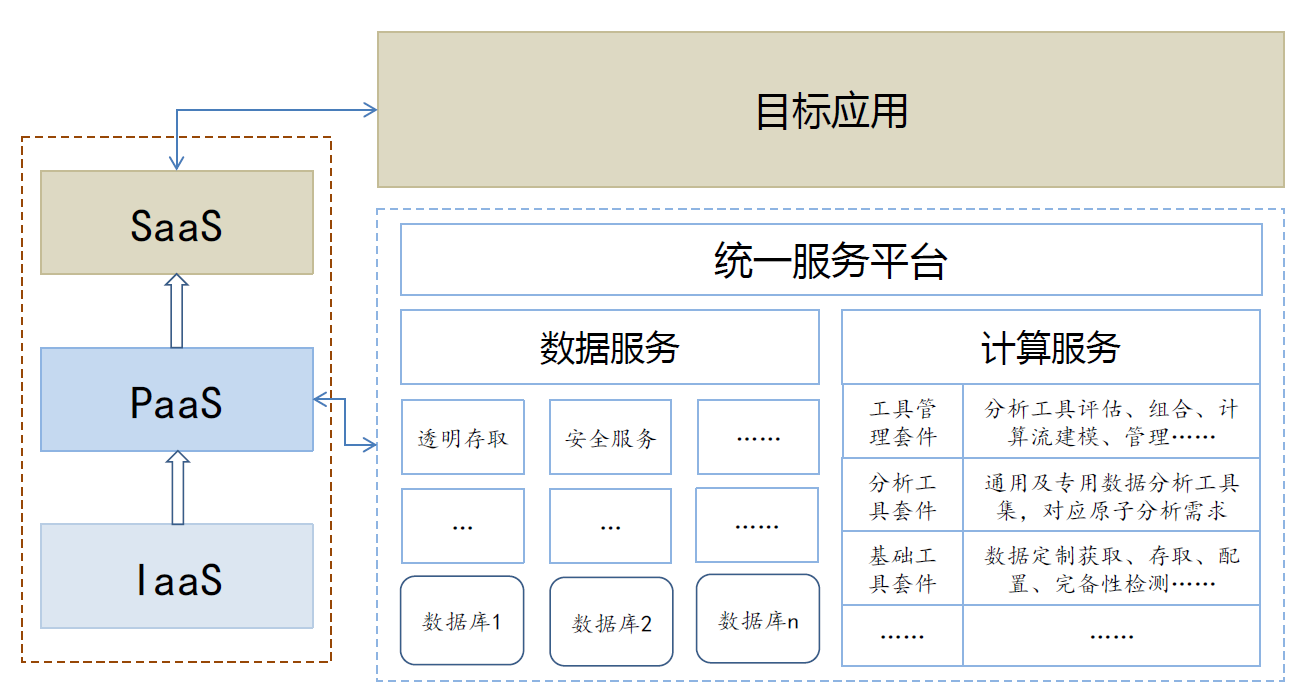
- 技术层次
- 计算虚拟化
- 数据虚拟化
- 云平台管理
- 非技术层次
- 一种应用模式
- 一种商业模式
- 一种盈利模式

2021-数据集成-数据集成与大数据
https://spricoder.github.io/2021/05/01/2021-Data-Integration/2021-Data-Integration-%E6%95%B0%E6%8D%AE%E9%9B%86%E6%88%90%E4%B8%8E%E5%A4%A7%E6%95%B0%E6%8D%AE/