2020-编译原理-Overview
Lecture1-Overview
1. 源起
- Donald E. Knuth (1938 ∼) Turing Award, 1974的贡献:
- LR Parser (语法)
- Attribute Grammar (语义)
- ALGOL 58 Compiler
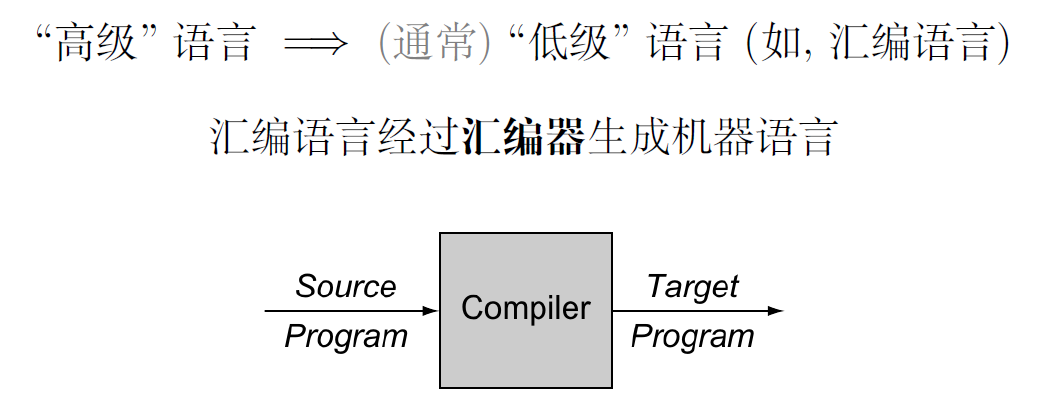
- 编译器一般而言是将一种语言转换成另一个语言,例如GopherJS(Go->JavaScript)
2. 机器语言是如何跑起来的
3. IR(Intermediate Representation) 中间表示
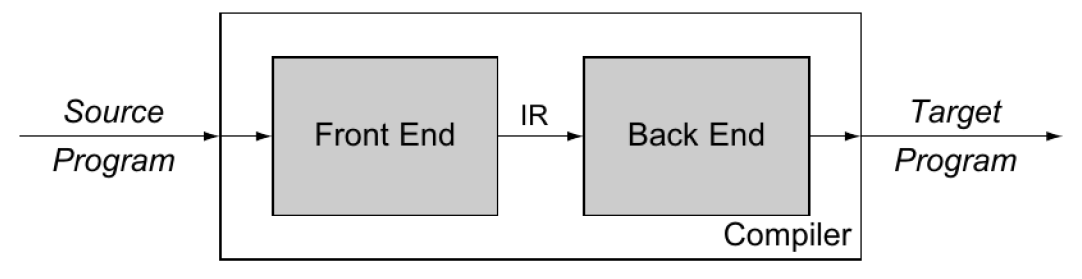
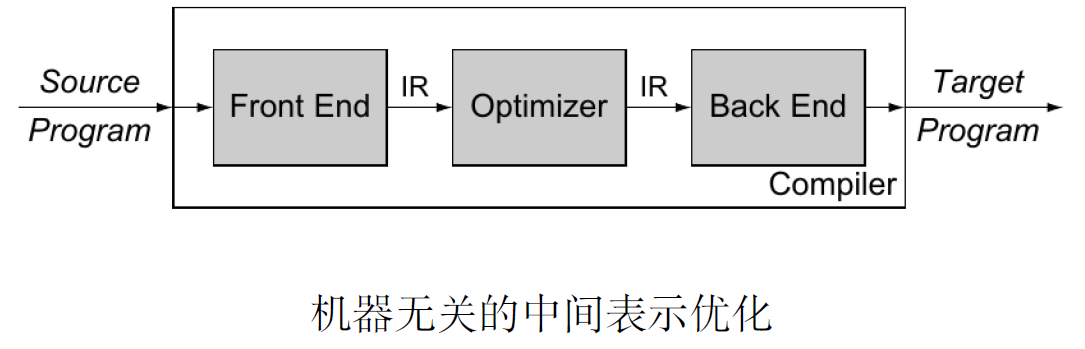
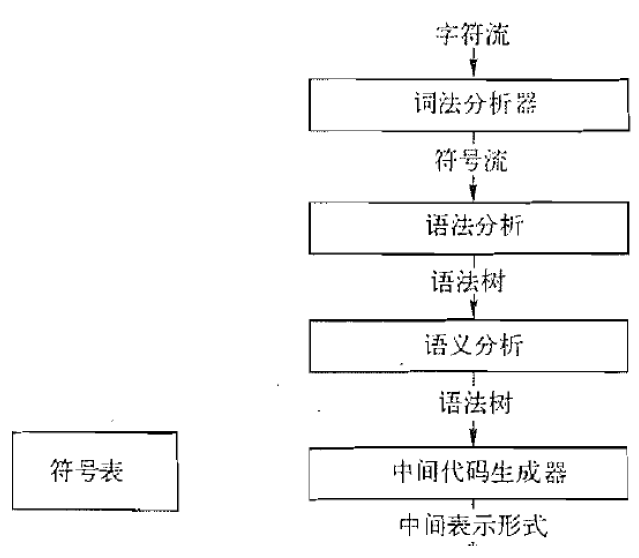
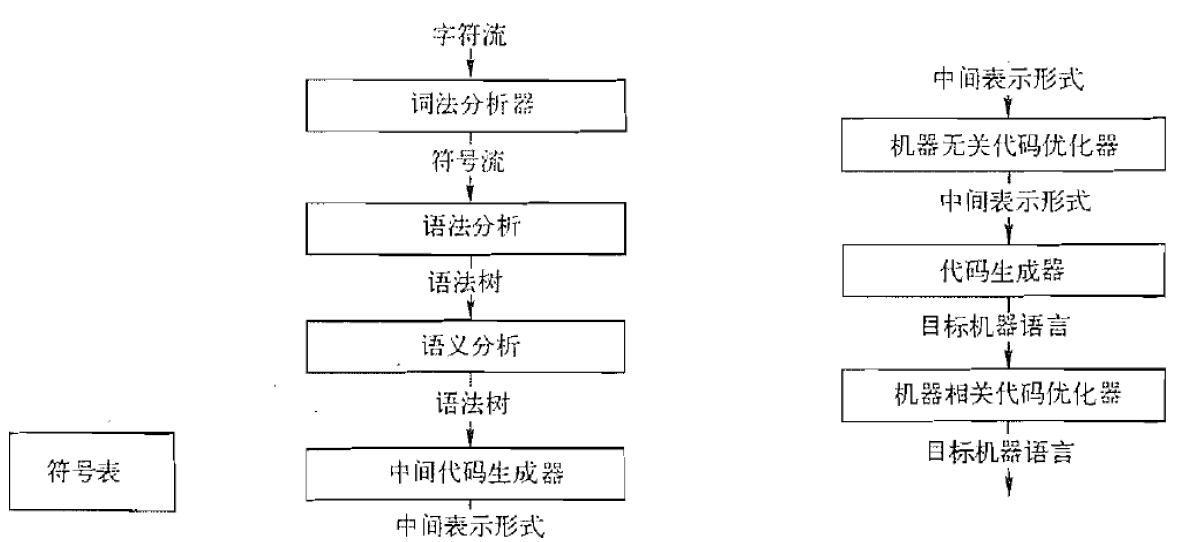
- 前端(分析阶段): 分析源语言程序, 收集所有必要的信息
- 后端(综合阶段): 利用收集到的信息, 生成目标语言程序
- 为什么不是一步到位,而是生成中间代码?
- 模块化
- 好处:例如C、Java、Python都可以生成同一种中间语言(与机器无关的),而中间语言可以生成不同的机器语言M1、M2、M3;如果没有模块化的话,则需要3*3的编译器。
3.1. 编译器前端:分析阶段
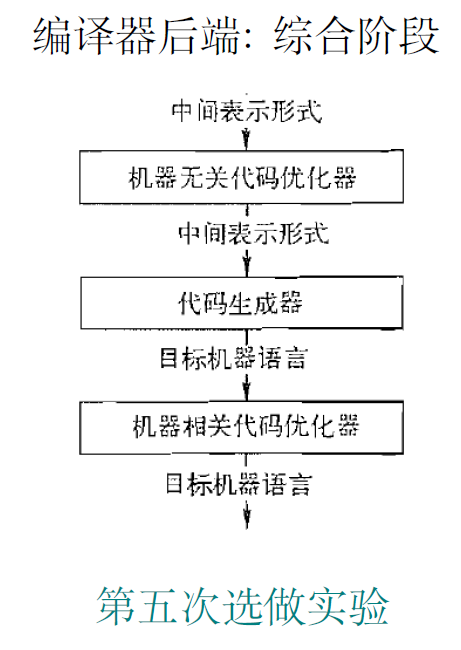
3.2. 编译器后端:综合阶段
3.3. 词法、语法、语义和物理定律
作为一名程序员,你看到了什么?
- 词法: 标识符、数字、运算符
- 语法: 包含算术运算的赋值语句
- 语义: position, initial, rate 是数值类型
- 物理定律: 当前位置 = 初始位置 + 速度 × 时间
- 我们希望编译器可以懂词法、语法、语义,但是作为编译器, 它仅仅看到了一个字符串
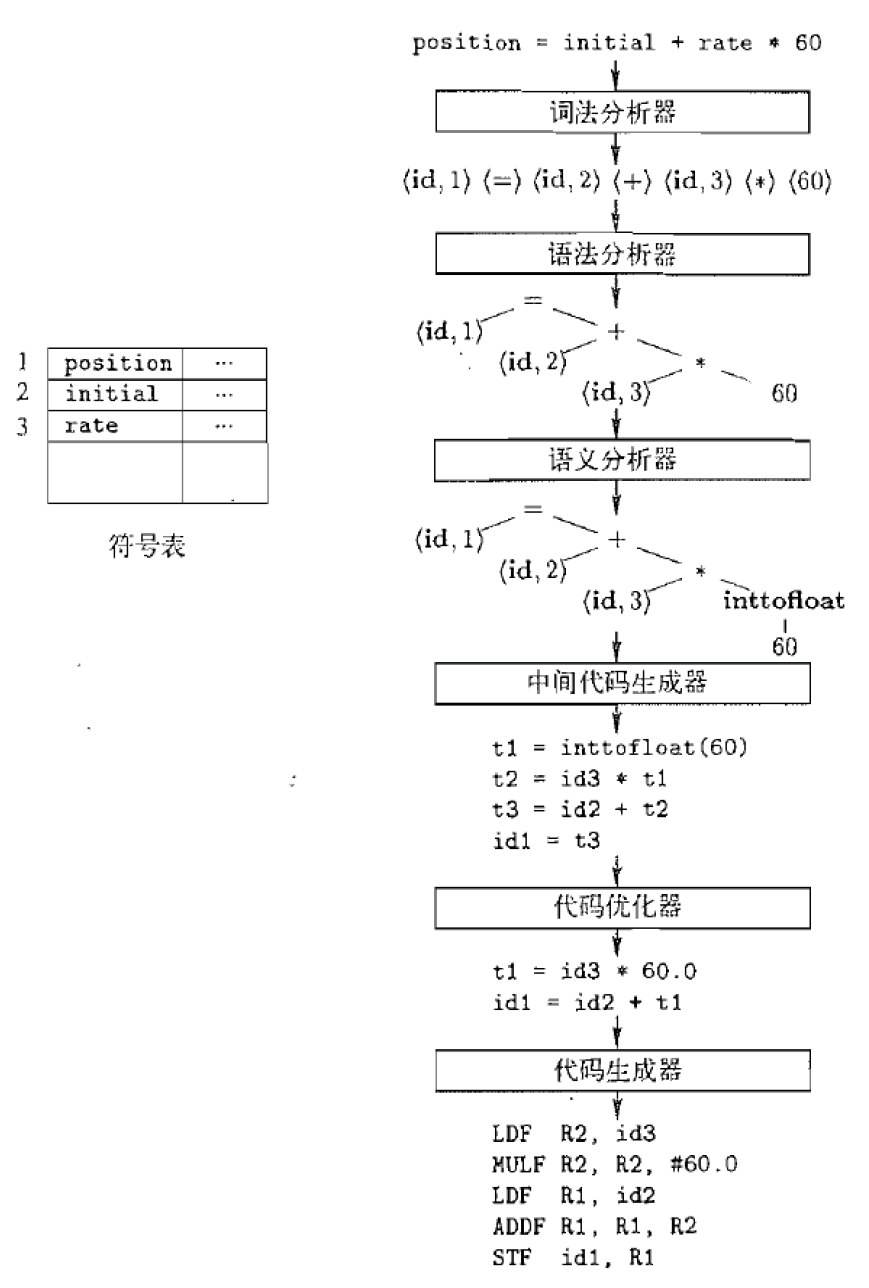
3.3.1. 词法分析器(Lexer/Scanner)
将字符流转化为**词法单元(token)**流。
token:<token-class, attribute-value>
- 属性值:收集到的信息(如内存地址、寄存器编号)
- 原形式:
position = initial + rat * 60 - 词法解析后结果:
⟨id, 1⟩ ⟨ws⟩ ⟨assign⟩ ⟨ws⟩ ⟨id, 2⟩ ⟨ws⟩ ⟨+⟩ ⟨ws⟩ ⟨id, 3⟩ ⟨ws⟩ ⟨∗⟩ ⟨ws⟩ ⟨num, 4⟩- ws表示空白符
- assign表示等号(赋值)
- 这里,1,2,3,4是指向符号表的指针
3.3.2. 语法分析器(Parser)
构建词法单元之间的语法结构, 生成语法树
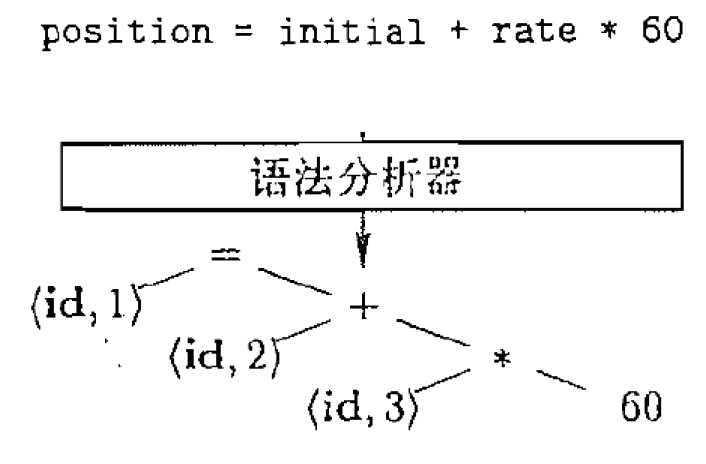
- 给定的程序是否符合语法规则,如果符合语法规则,则构建语法树;构建完成之后,源程序就使用不到了,所有的操作都将在语法树中进行。
3.3.3. 语义分析器
语义检查, 如类型检查、“先声明后使用” 约束检查
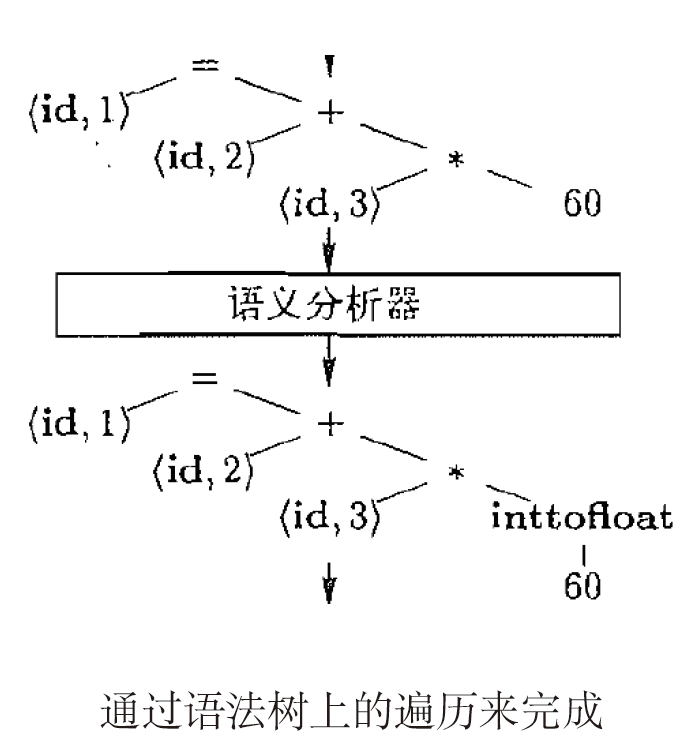
- 语义分析器:语义检查,如类型检查(最重要的检查)、"先声明后使用"约束检查
- 这里的inttofloat就是类型分析,即类型提升。
- “先声明后使用”:变量和函数在使用前是否声明过。
3.3.4. 中间代码生成器
生成中间代码, 如三地址代码
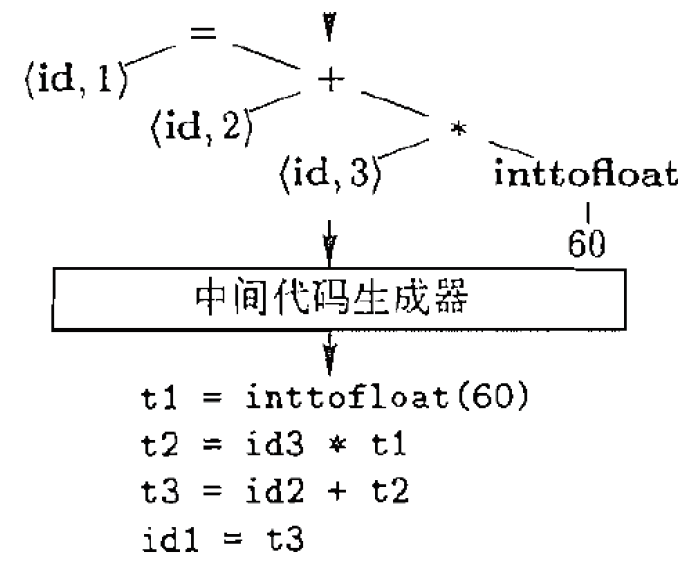
- 中间代码类似目标代码, 但不含有机器相关信息(如寄存器、指令格式)
3.3.5. 中间代码优化器
编译时计算、消除冗余临时变量
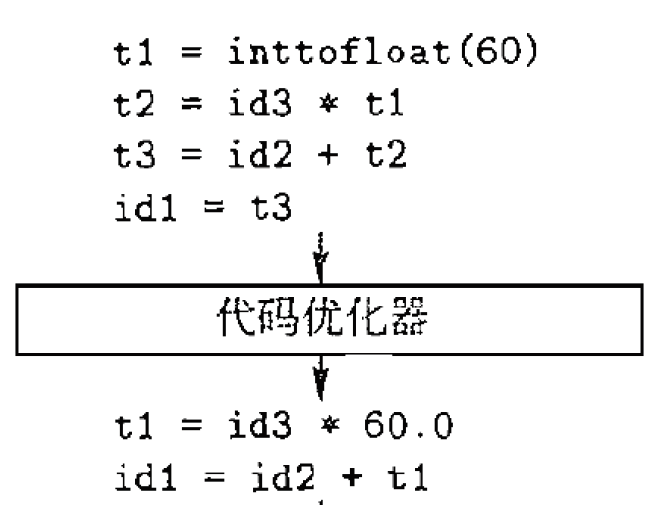
- 编译时计算、消除冗余临时变量
3.3.6. 代码生成器
生成目标代码, 主要任务包括指令选择、寄存器分配

- 注意:这里现将id3的地址是放到寄存器R2中的,由于计算的时候是需要放在寄存器中进行的。
3.3.7. 符号表
收集并管理变量名/函数名相关的信息
- 变量名:类型、寄存器、内存地址、行号(debug中可以使用到)
- 函数名:参数个数、参数类型、返回值类型
- 编译器最重要的数据结构是tree和hash table
- 符号表:红黑树(RB-Tree)、哈希表(Hashtable)

- 为了方便表达嵌套结构与作用域, 可能需要维护多个符号表
- 支持几个变量是重名的,可以作用在不同的作用域中。

3.4. 时间苦短, 来不及优化
但是, 在设计实际生产环境中的编译器时, 优化通常占用了大多数时间
2020-编译原理-Overview
https://spricoder.github.io/2021/01/16/2020-Compilation-Principle/2020-Compilation-Principle-Overview/