1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
|
import os
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
from tqdm import tqdm
class extractFromPDF:
def __init__(self, pdf_name, pdf_root, save_root):
'''
初始化转换PDF的类
:param pdf_name:PDF的文件名
:param pdf_root:PDF存放的根目录
:param save_root:TXT保存的根目录
'''
self.pdf_name = os.path.join(pdf_root, pdf_name)
self.save_path = os.path.join(save_root, pdf_name.split(".")[0] + ".txt")
self.source = []
def _fresh(self):
'''
将得到的结果刷新到TXT中去
:return:
'''
with open(self.save_path, 'w', encoding="utf-8") as f:
for line in self.source:
f.write(line.strip() + "\n")
def run(self):
'''
执行对PDF的处理
:return:
'''
with open(self.pdf_name, 'rb') as pdf:
self.pdf = pdf
self._parse_pdfminer()
self._fresh()
def _parse_pdfminer(self):
'''
解释处理PDF,并将每一行放置到source中去
:return:
'''
parser = PDFParser(self.pdf)
doc = PDFDocument()
parser.set_document(doc)
doc.set_parser(parser)
doc.initialize()
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
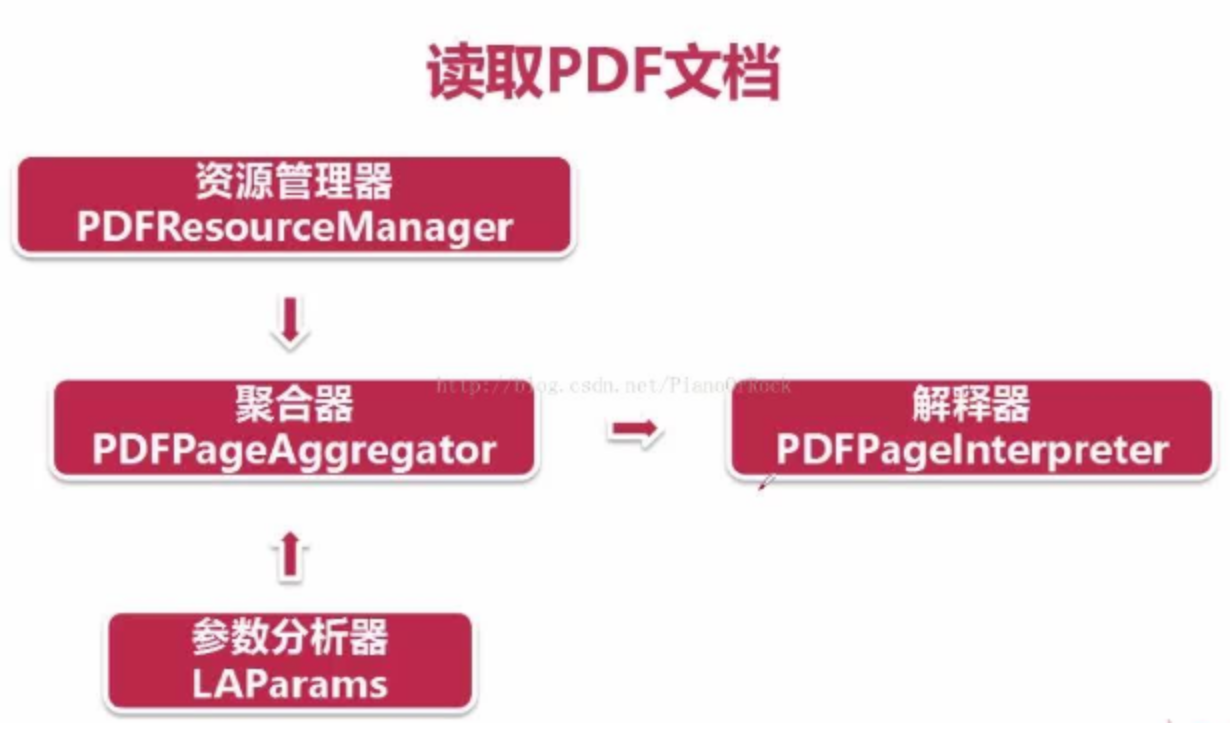
pdf_resource_manager = PDFResourceManager()
pdf_la_params = LAParams()
device = PDFPageAggregator(pdf_resource_manager, laparams = pdf_la_params)
interpreter = PDFPageInterpreter(pdf_resource_manager, device)
for page in doc.get_pages():
interpreter.process_page(page)
layout = device.get_result()
for x in layout:
if (isinstance(x, LTTextBoxHorizontal)):
result = x.get_text()
self.source.append(result + "\n")
pdf_root = "./ACL2020"
save_root = "./ACL2020_txt"
if __name__ == '__main__':
if(not os.path.exists(save_root)):
os.mkdir(save_root)
ACL_lines = os.listdir(pdf_root)
fail_lines = []
for ACL_line in tqdm(ACL_lines):
try:
tmp = extractFromPDF(ACL_line, pdf_root, save_root)
tmp.run()
except Exception as e:
fail_lines.append(ACL_line)
print(ACL_line, "失败")
print(str(e))
|