2020-大数据分析-Lecture9-知识图谱
Lecture9-知识图谱
1. 知识图谱
- 知识图谱概念
- 知识图谱内涵
- 知识图谱优势
- 知识图谱价值
- 典型知识图谱
2. 知识图谱概念
- 知识图谱(Knowledge Graph)本质上是一种大规模语义网络 (semantic network),富含实体(entity)、概念(concepts) 及其之间的各种语义关系 (semantic relationships)
- 作为一种语义网络,是大数据时代知识表示的重要方式之一
- 作为一种技术体系,是大数据时代知识工程的代表性进展
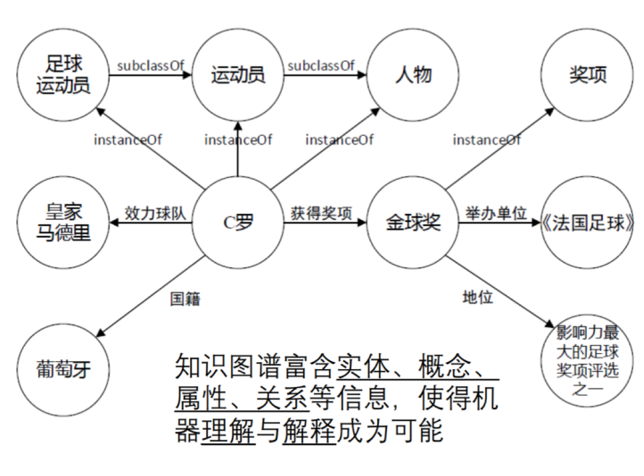
- 知识图谱示例子。知识图谱富含实体、概念、属性、关系等信息

2.1. 知识图谱分类
- 领域(行业)知识图谱 (Domain specific Knowledge Graph):聚焦于特定领域或者行业的知识图谱
- 企业知识图谱(Enterprise knowledge graph):贯穿企业各业务部门的知识图谱

2.2. 知识图谱的源头

2.3. 知识图谱应用
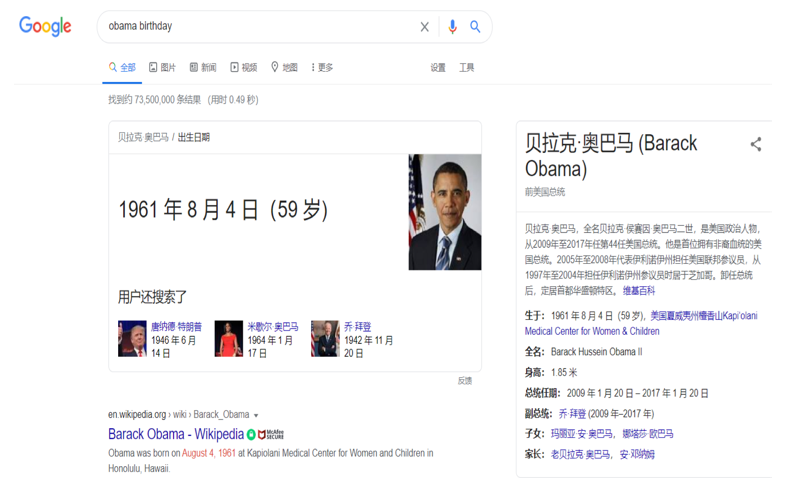
- 2012年5月,Google收购Metaweb 公司,并正式发布知识图谱
- 搜索核心需求:让搜索通往答案,但是机器无法理解搜索关键词,也很难精准回答。
- 根本问题
- 缺乏大规模背景知识
- 传统知识表示难以满足需求
3. 知识图谱内涵
- 开放和封闭的知识图谱:开放是可以添加知识进来,而封闭的则不可以
- 定义本体:在作知识图谱之前一定要先明确是开放还是封闭的
3.1. KG组成:Node-Entity
- Entity/Objects/Instances:维基百科:实体就是东西,它本身,作为主体或作为对象存在,实际上或潜在地,具体地或抽象地,物理地或非物理地存在。
- Concept:概念
- 在形而上学,尤其是本体论中,概念是存在的基本类别。
- 类别的(心理)表示
- Category:类别有共同点的实体组;
- Type/class:类型/类别,WIKITIONARY:基于共享特征的分组;一类。
3.2. KG组成:Node-Entity例子
- Date:特朗普 出生日期 1946年6月14日
- String:特朗普 简介"唐纳德·特朗普(Donald Trump),第45任美国总统,1946 年6月14日生于纽约,美国共和党籍政治家"
- Numeric:特朗普 年龄 71
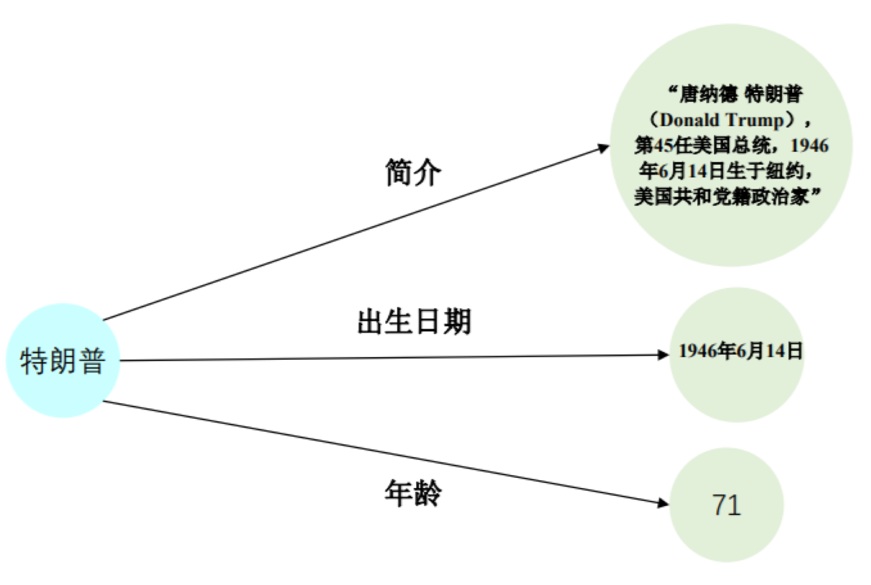
- 每一个信息都是node,这个node是可以被重用的,比如年龄71的点
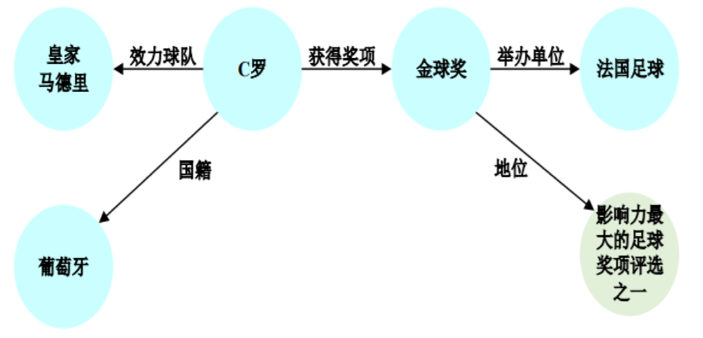
3.3. KG组成:Edge
- Relation:
- 侧重实体(indvidual)之间的关系
- 例子:
- 坐着:坐在桌子上的苹果
- 更高:华盛顿纪念碑比白宫高
- Property/Attribute/Quality(属性)
- 描述对象的特征/质量
- 例子:对象的大小,颜色,重量,成分等
4. 知识图谱源起
4.1. 知识工程(KE)的缘起-Symbolism,符号主义
- 符号主义的主要观点
- 认知即计算
- 知识是信息的一种形式,是构成智能的基
- 知识表示、知识推理、知识运用是人工智能的核心

- 物理符号系统
- 物理符号系统具有一般智能操作的必要和充分手段
- 可以将思维视为根据正式规则对信息进行操作的设备。
- GOFAI(老式人工智能,由John Haugeland提出),专注于此类高水平符号,例如
<dog>和<tail> - AI System = Knowledge + Reasoning
4.2. 代表人物和时间节点
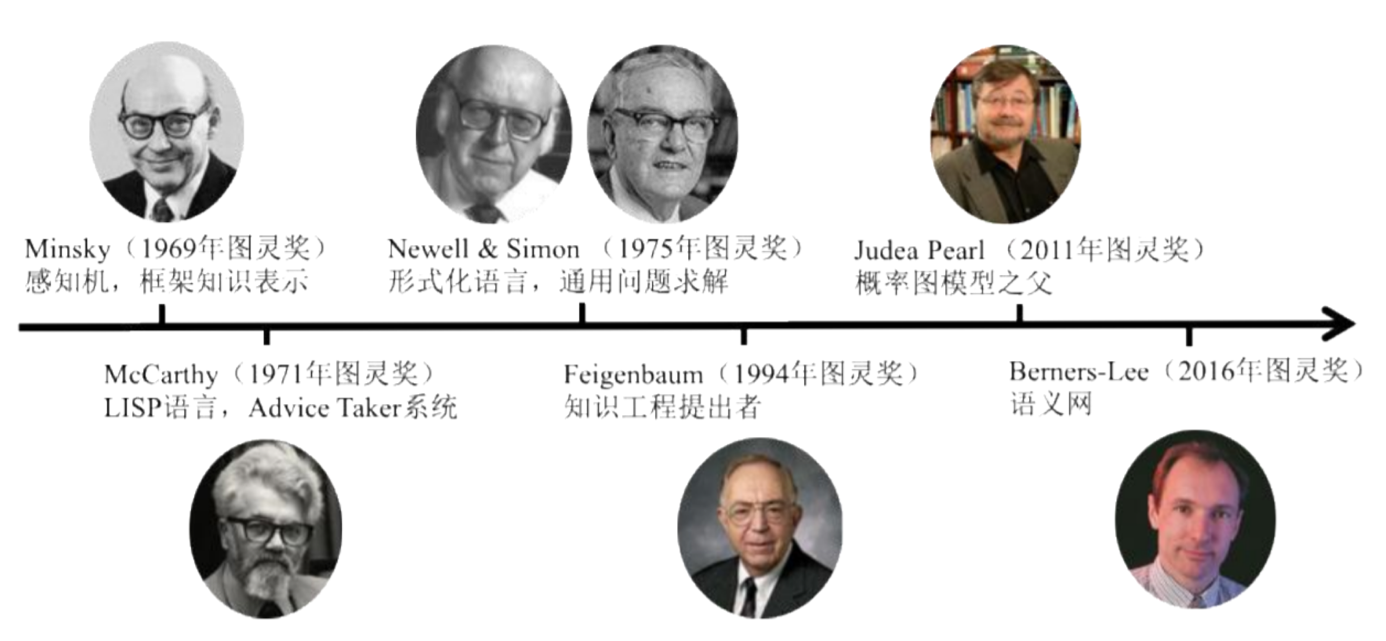
- KE(知识工程)是一门工程学科,涉及将知识集成到计算机系统中,以解决通常需要高水平专业知识的复杂问题。 参考维基百科
- 知识工程是以知识为处理对象,研究知识系统的知识表示、处理和应用的方法和开发工具的学科的方法和开发工具的学科
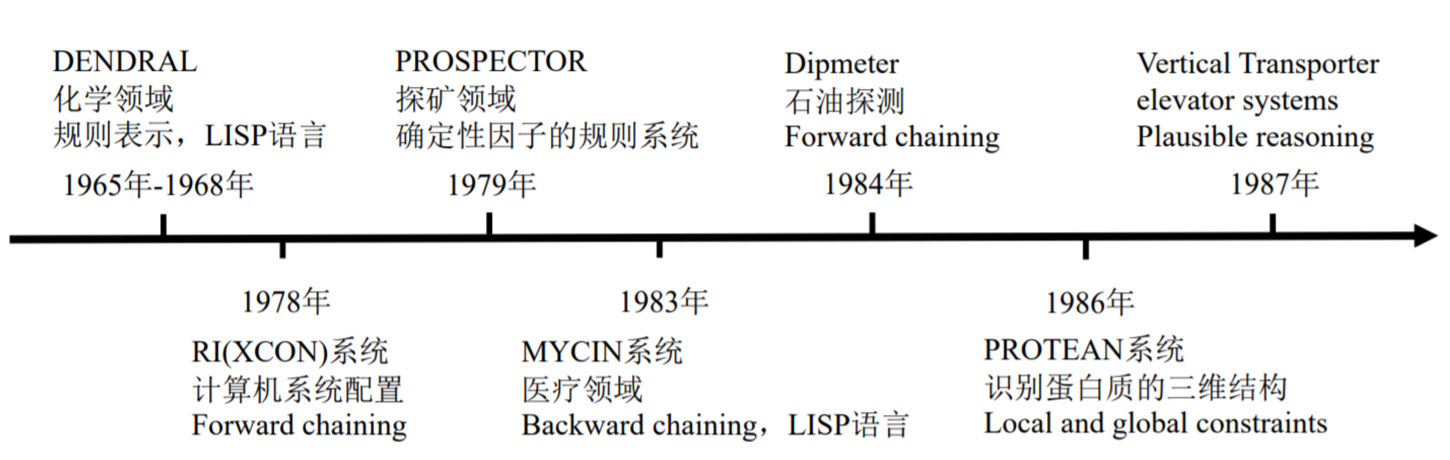
传统知识工程在规则明确、边界清晰、应用封闭的应用场景取得了巨大成功
4.3. 传统KE的基本特点
- 自上而下:严重依赖专家和人的干预
- 规模有限
- 质量存疑
4.4. 传统KE的主要挑战:知识获取困难
- 隐性知识、过程知识等难以表达,专家不一定愿意分享出来,不同专家之间的知识可能不一致。
- 如何表达做蛋炒饭的知识?
- 老中医看病用到了哪些知识。
- 领域知识的形式化表达较为困难。
- 专家知识不可避免地存在主观性,比如都是做一个方向的,表达方式、研究路径可能不一致。
- 知识表达难以完备,缺漏是常态。
4.5. 传统KE的主要挑战:知识应用困难
- 应用易于超出预先设定的知识边界
- 很多应用需要常识的支撑
- 难以处理异常情况
- 难以处理不确定性推理
- 知识更新困难
- Example:
Can pig fly? - Rule:鸟是可以飞的
行业应用中的知识需求难以封闭于预设的领域知识边界内
4.6. 互联网应用催生大数据世代知识工程(BigKE)
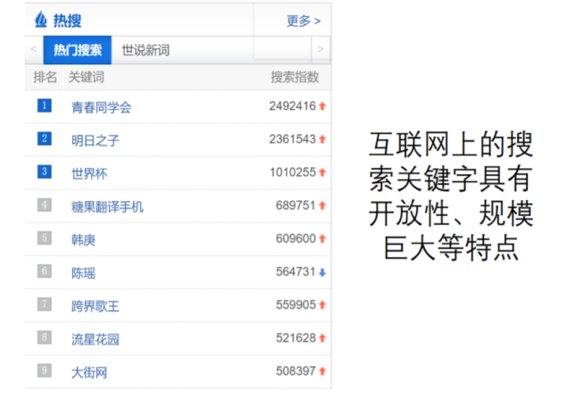
- 大规模开放性应用
- 永远不知道用户下一个搜索关键字是什么
- “创造101”、“吃鸡”、“纸片人”、“蛙儿”
- 精度要求不高:搜索引擎从来不需要保证每个搜索的理解和检索都是正确的
- 应用/推理简单
- 大部分搜索理解与回答只需要实现简单的推理
- 简单推理:姚明的身高是多少,一跳就可以解决
- 复杂推理:姚明老婆的婆婆的儿子有多高,需要几跳才可以解决
- 互联网时代的大规模开放性应用需要全新的知识表示,谷歌知识图谱诞生,知识工程迈入大数据时代
 |
 |
|---|
4.7. 数据驱动的大规模自动化知识获取
- 自下而上:网页文本、搜索日志、购买记录
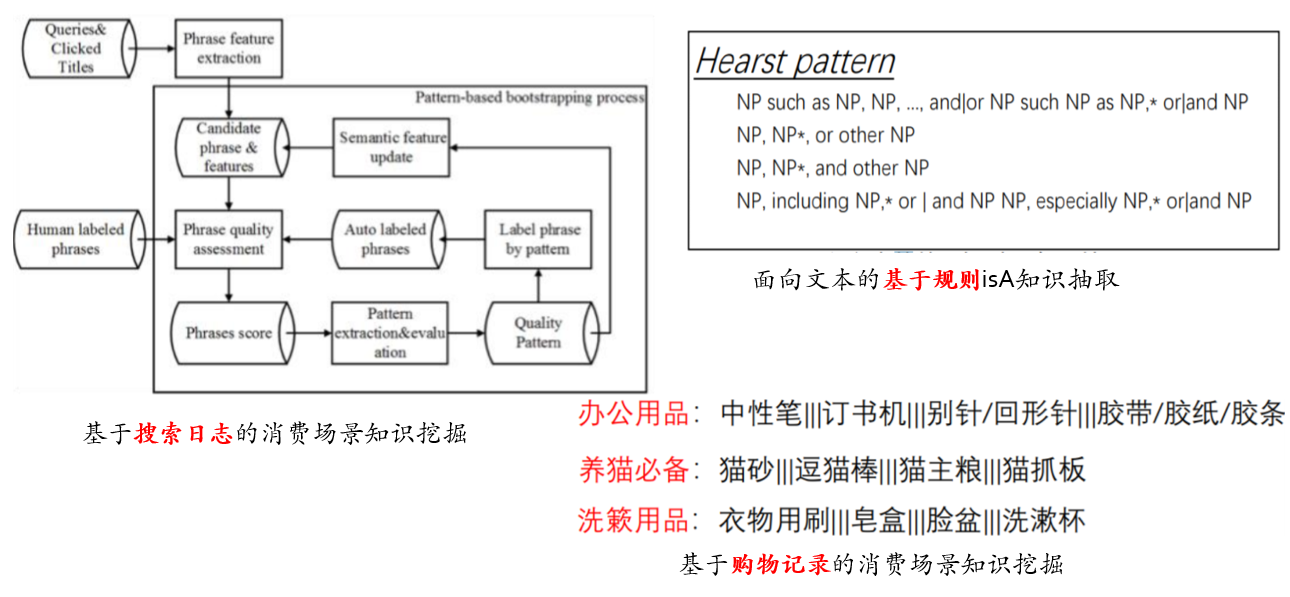
4.8. 大数据时代的机遇——众包技术
- 众包与群智成为大规模知识获取的一条新路径
案例1: 基于知识问答验证码的知识获取:复旦大学知识工场实验室提供知识验证码服务,通过众包的方式对现有知识进行验证

案例2:基于众包的Taxonomy构建,DBpedia通过众包方式构建了DBpedia Ontology

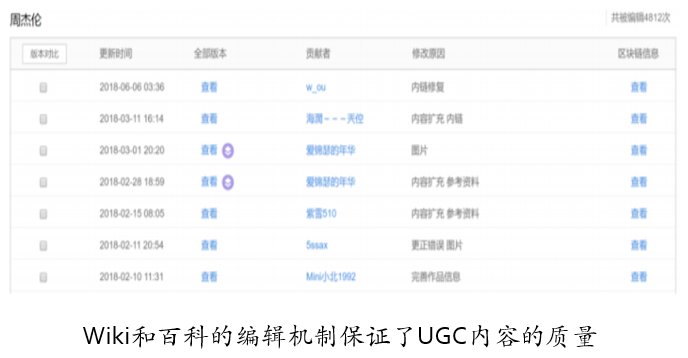
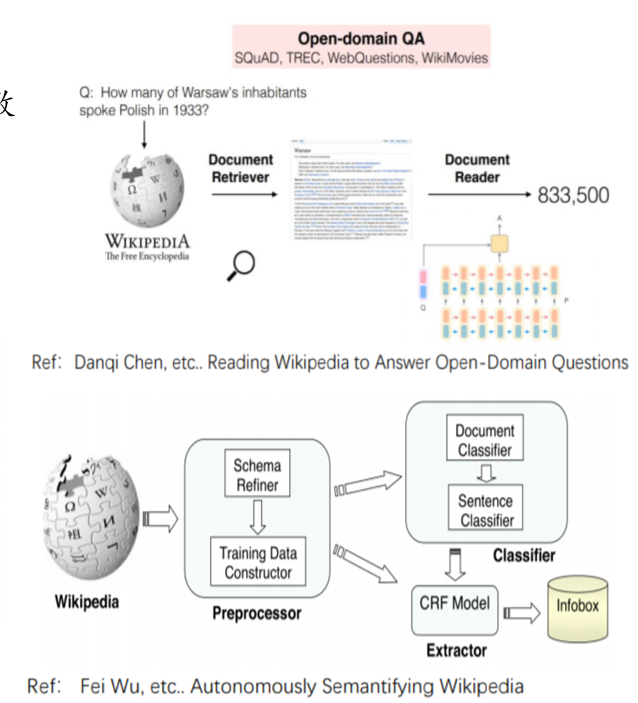
4.9. 大数据世代的机遇——高质量UGC
- Web2.0时代到未,产生大量的高质量UGC(User Generated Content)
- 提供获得得广大用户一致认可的高质量数据源
- 维基百科, 百度百科
- 为自动挖掘知识提供了高质量数据源
- 为构建抽取模型提供了高质量样本
 |
 |
|---|
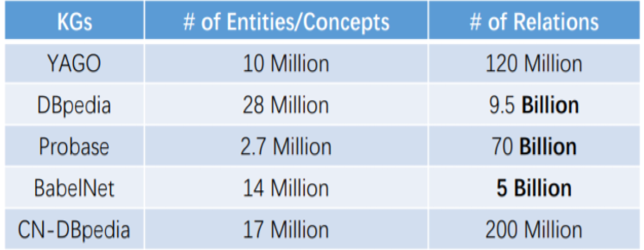
5. 知识图谱优势
5.1. 大规模
- 对实体和概念的更大覆盖
 |
 |
|---|
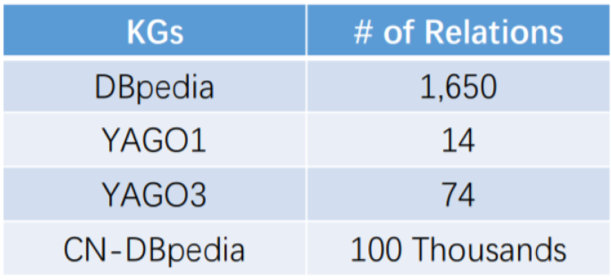
5.2. 语义丰富
覆盖更多语义关系
 |
 |
|---|
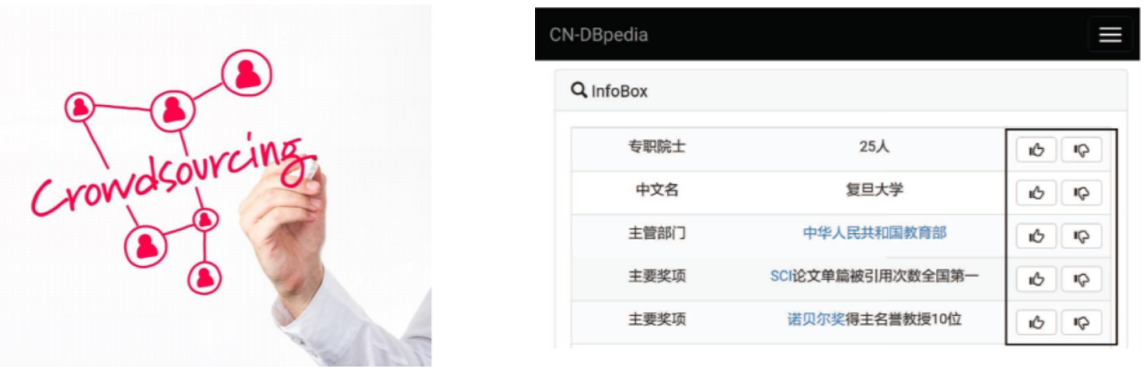
- 高质量数据
- 大数据:多种来源的交叉验证
- 众包:质量保证
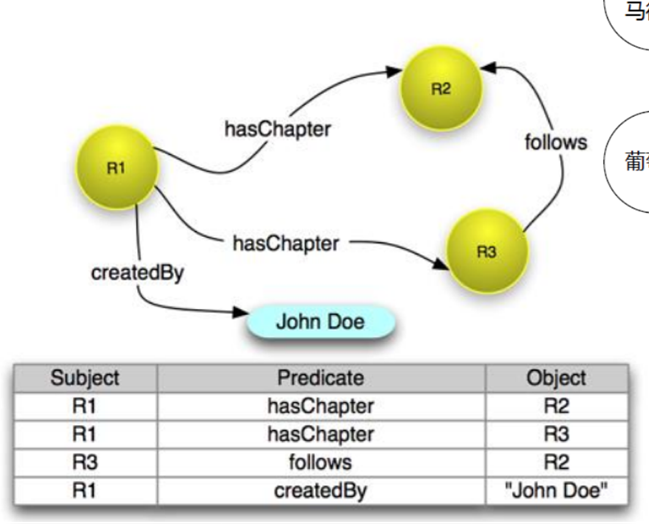
5.3. 友好的结构
结构化的组织
- 通过RDF
- 按图
 |
 |
|---|
6. 越来越多的知识图谱应运而生
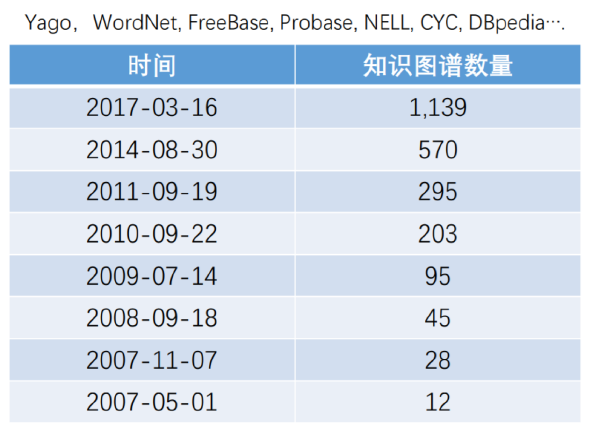 |
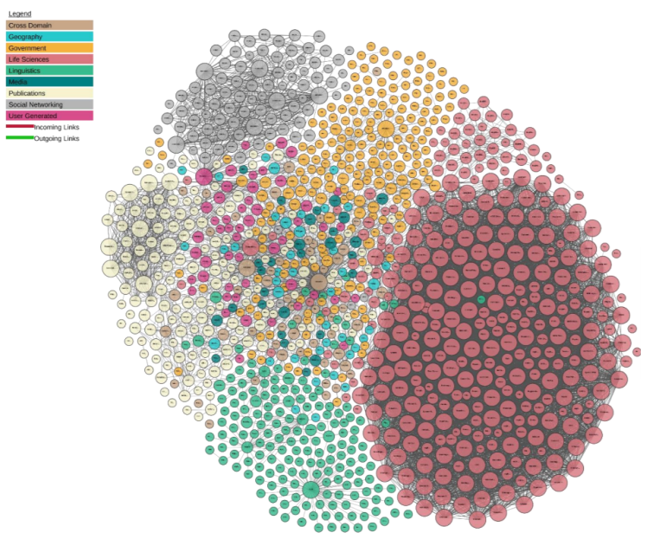 |
|---|
7. 知识图谱的价值
7.1. 未来已至:人类已经进入智能时代
- 大数据的日益积累、计算能力的快速增长为人类进入智能时代奠定了基础
- 大数据为智能技术的发展带来了前所未有的数据红利
- 机器计算智能、感知智能达到甚至超越人类

7.2. 智能化升级与转型
- 智能化升级与转型已经成为各行各业的普遍诉求
- 从信息化走向智能化是必然趋势
- AI+成为AI赋能传统行业的基本模式
- 战略意义
- 全方位、深度渗透到各行各业、各个环节
- 颠覆性影响,重塑行业形态,甚至社会形态
7.3. 认知智能是智能化的关键
理解与解释是后深度学习时代人工智能的核心使命之一
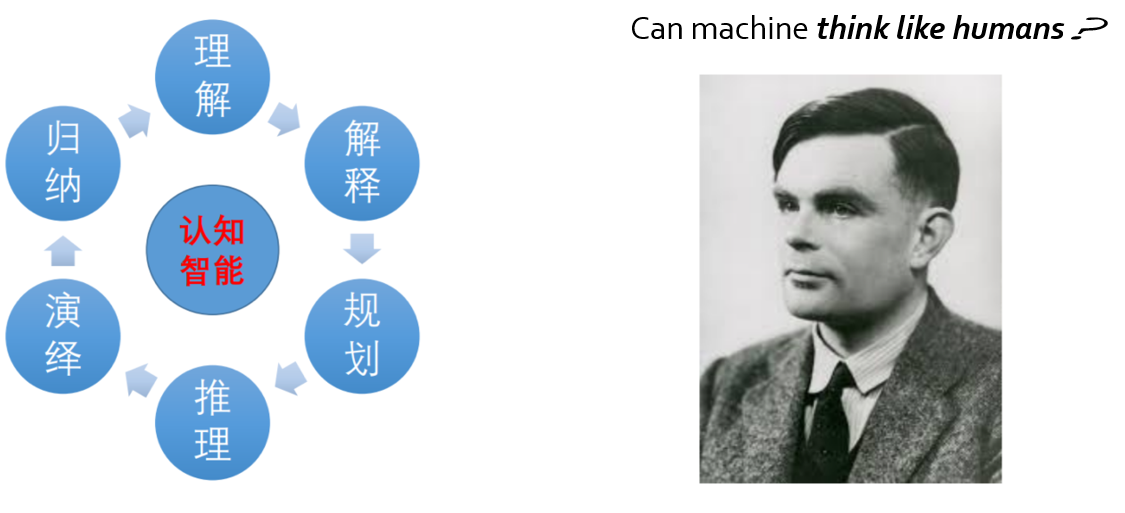
7.4. 知识图谱使能认知智能
- 机器理解数据的本质:建立从数据到知识库中实体、概念、关系的映射
- 机器解释现象的本质:利用知识库中实体、概念、关系解释现象的过程
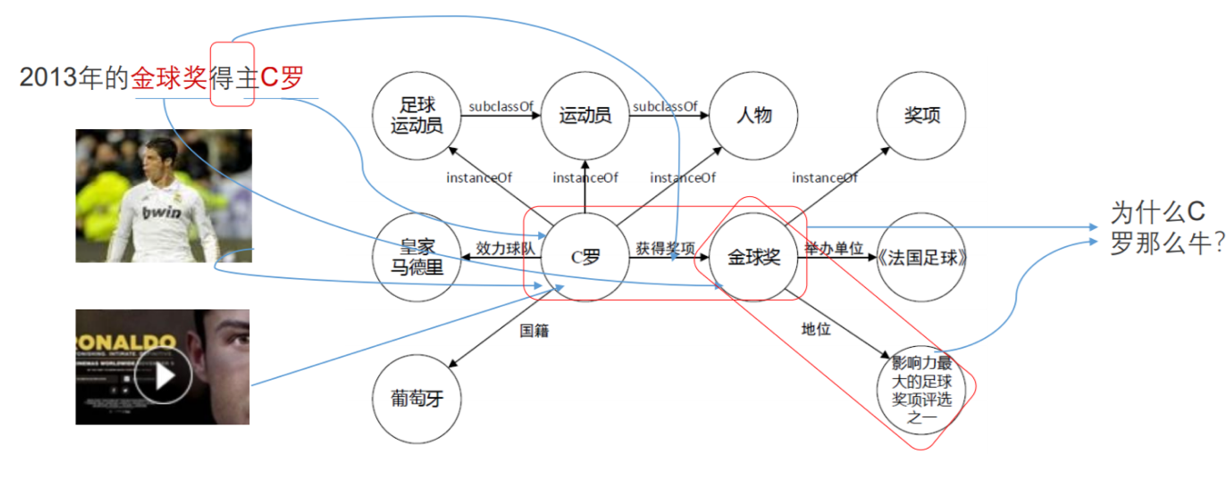
7.5. 知识图谱使能机器语言认知
- 对机器的语言理解需要知识库
- 大规模
- 语义丰富
- 友好的结构
- 高质量
- 传统知识表示不能满足这些要求,但是KG可以
- 本体
- 语义网络/框架
- 文字
- NLP + KB = NLU
- NLP =自然语言处理
- NLU =自然语言理解
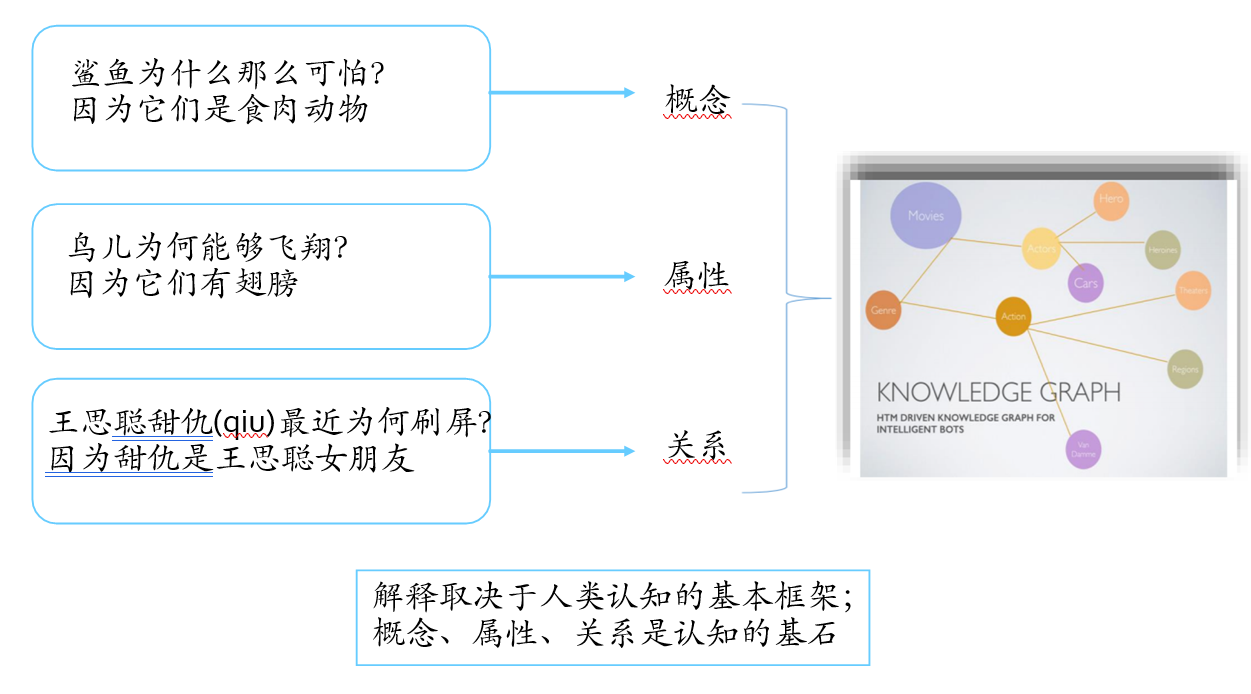
7.6. 知识图谱使能可解释人工智能
解释取决于人类认知的基本框架;概念、属性、关系是认知的基石。
7.7. 知识引导成为解决问题的主要方式
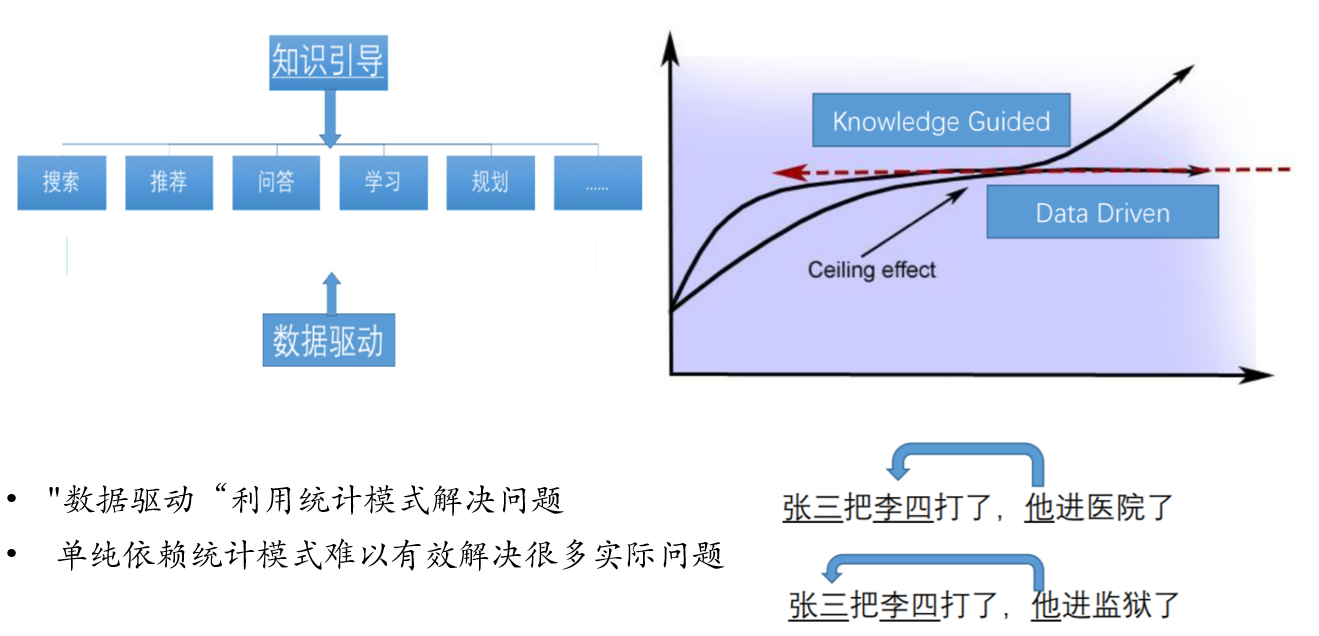
- 数据驱动利用统计模式解决问题
- 单纯依赖统计模式难以有效解决很多实际问题
7.8. 知识将显著增强机器学习能力
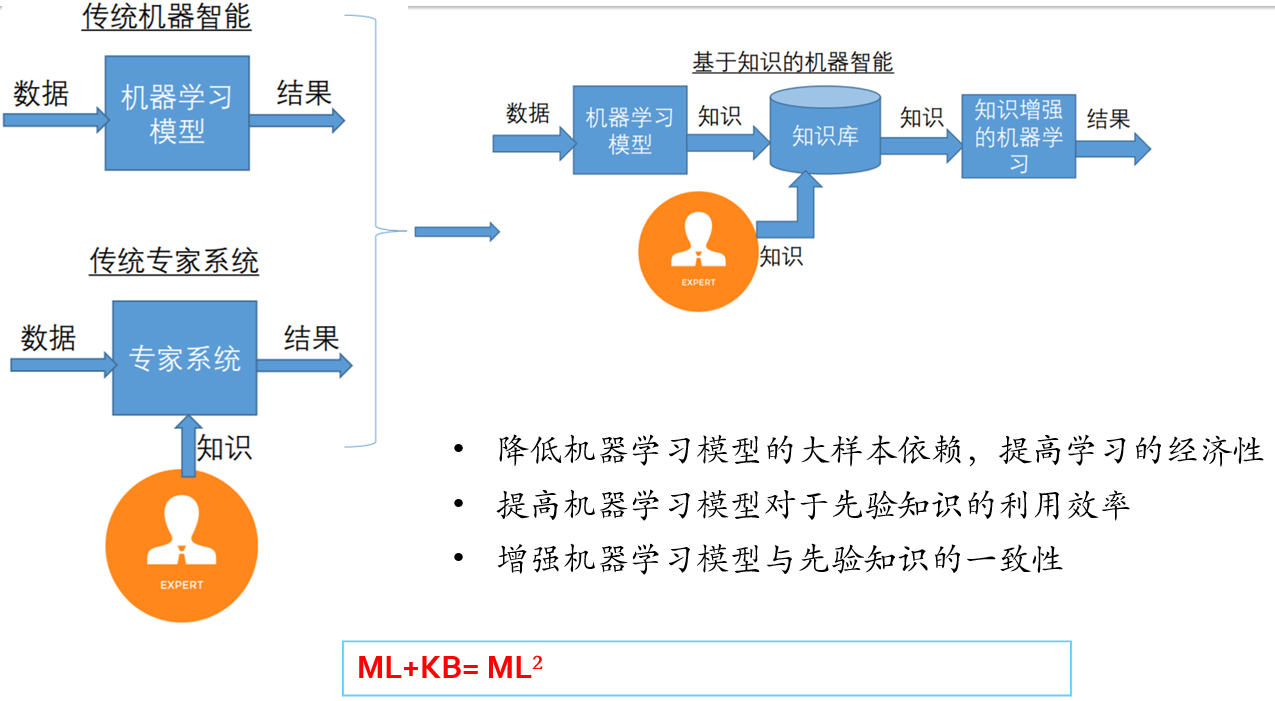
- 降低机器学习模型的大样本依赖,提高学习的经济性
- 提高机器学习模型对于先验知识的利用效率
- 增强机器学习模型与先验知识的一致性
7.9. 知识将成为比数据更为重要的资产
- 大数据时代是得数据者得天下
- 人工智能时代是得知识者得天下
- 数据是石油,知识就是石油的萃取物
- Knowledge is power in AI
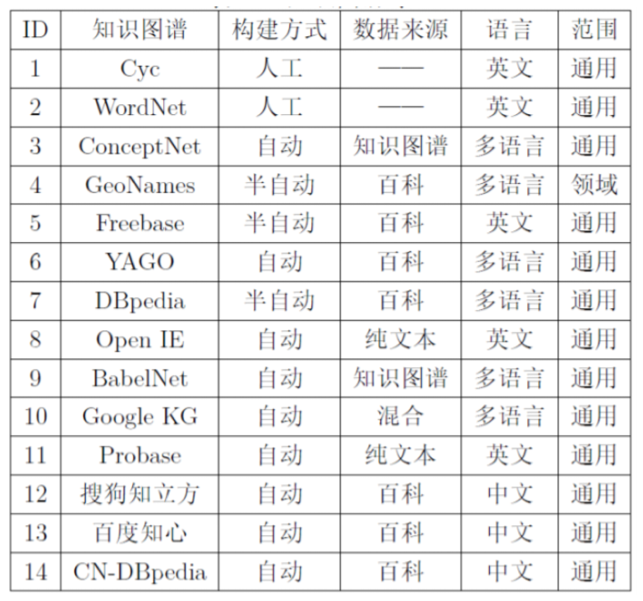
8. 典型知识图谱
8.1. 知识图谱分类
- 自动化程度
- 数据来源结构化程度
- 跨语言
- 通用/specific
8.2. Cyc
- 简介:常识知识图谱
- 特点:通过人工方法将上百万条人类常识编码成机器可用的形式,用以进行智能推断
- 规模:目前ResearchCyc知识图谱中包含了700万条断言(事实和规则),涉及63万个概念,38000种关系
- http://www.cyc.com/
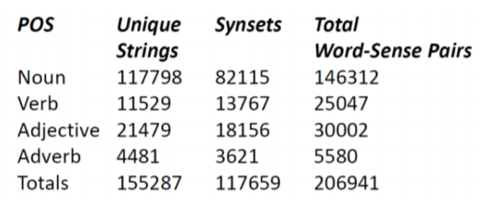
8.3. WordNet
- 简介:基于认知语言学的英语词典
- 样例:S(n) car, auto, automobile, machine, motorcar (a motor vehicle with four wheels; usually propelled by an internal combustion engine) “he needs a car to get to work”
- 特点:以同义词集合( synset )作为一个基本单元
- 规模:
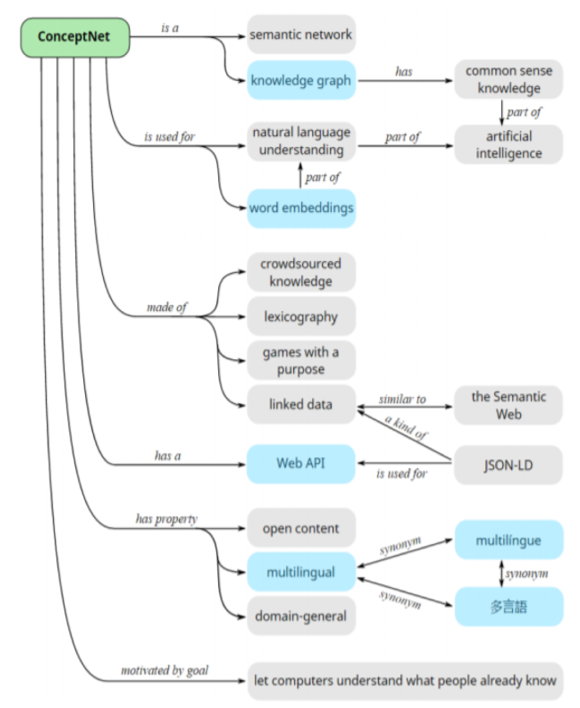
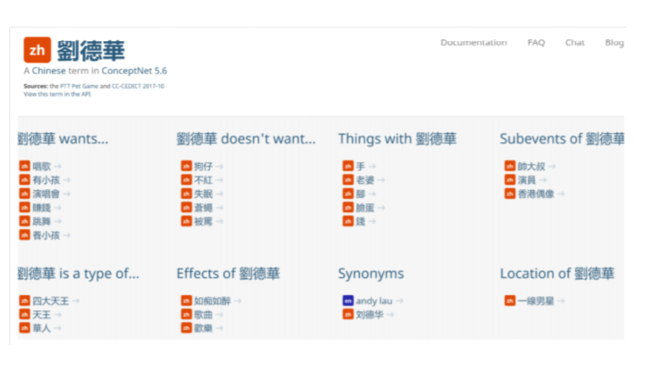
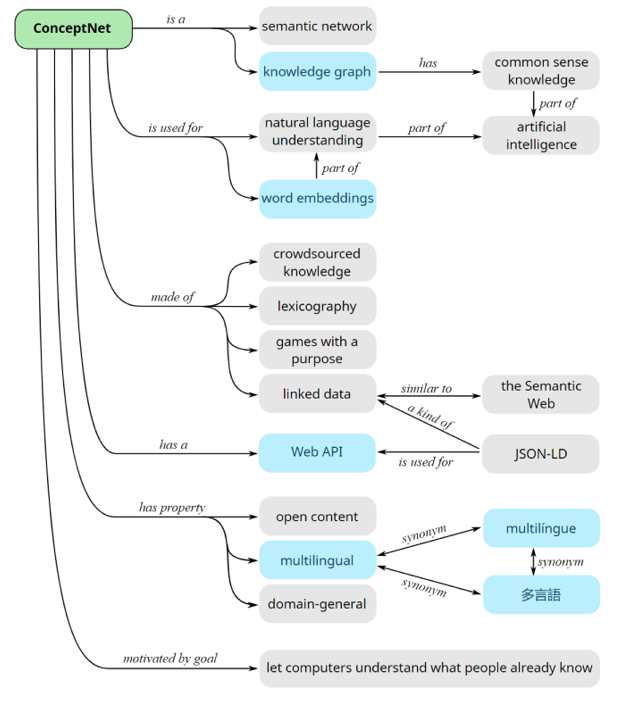
8.4. ConceptNet
- 简介:大型的多语言常识知识库
- 特点:知识来源丰富
- 众包(Crowd-Sourcing)
- 资源(例如Wiktionary 和Open Mind Common Sense)
- 带目的的游戏(如Verbosity 和 nadya.jp)
- 专家创建的资源(如WordNet 和JMDict)
8.5. Freebase/Wikidata
- 简介:
- Freebase 所有知识采用结构化的表示形式,可由机器和人编辑
- Wikidata是维基百科的姐妹工程,同样可由机器和人自由编辑
- 2016年8月31日,Freebase宣布关闭, 所有数据汇入Wikidata
- 样例:“Donald Trump”
- 特点
- 众包构建
- 结构化三元组
- 统计:Wikidata目前包含49,915,906个实体

8.6. DBpedia
- 从维基百科页面中自动抽取出结构化的知识,构建而成的大型通用百科图谱
- 样例:

- 特点
- 多语
- 自动构建
- 统计
- 共收录有 127 种不同语言共计2800万实体
- 其中英文实体数量最大,为 467 万
- http://wiki.dbpedia.org/
8.7. Google KG
- 简介:谷歌知识图谱于2012 年发布,被认为是搜索引擎的一次重大革新
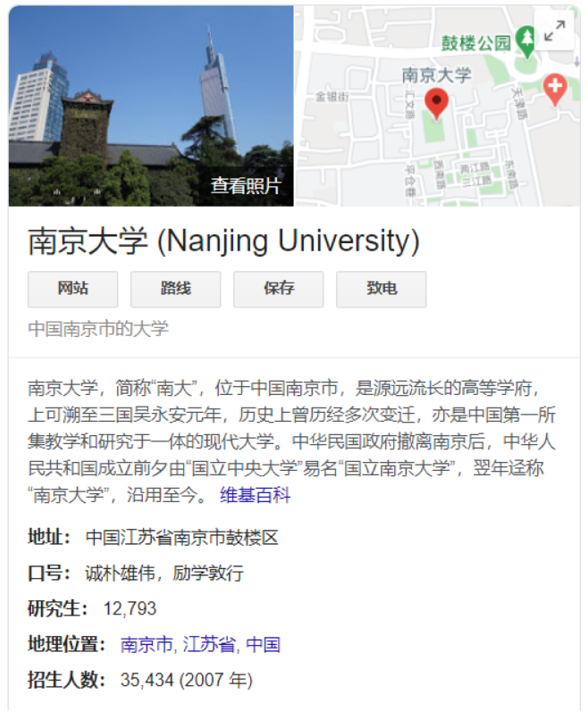
- 样例:“Nanjing University”
- 特点:
- 规模巨大
- 用于增强搜索引擎的搜索能力
- 统计:5700万实体,180亿关系
9. 领域知识图谱
9.1. 什么是领域知识图谱
- 知识图是一个大规模的语义网络,由实体/概念以及它们之间的语义关系组成
- 特定领域的知识图
9.2. NoKG(Not Only KG)
- 传统知识工程,专家构建,代价高昂, 规模有限;知识边界易于突破,难以适应大数据时代开放应用到规模化需求
- 大规模开放应用需要"大"知识(大规模知识库)
- Small Knowledge + Big Data = Big Knowledge,知识图谱引领知识工程
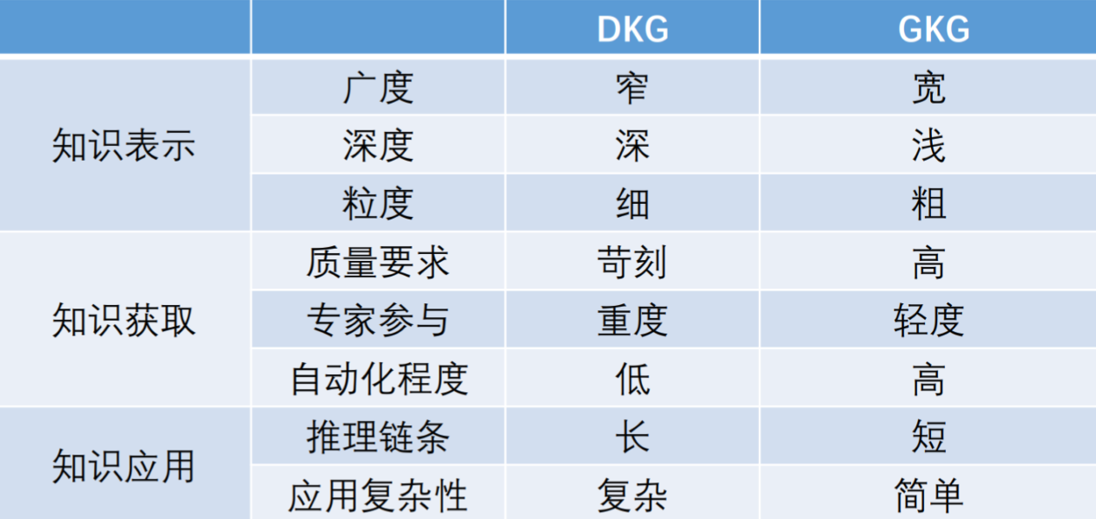
9.3. DKG与GKG的区别
- DKG,Domain-specific Knowledge Graph,领域知识图谱
- GKG,General-purpose Knowledge Graph,通用知识图谱
- DKG和GKG在知识表示、获取与应用等方面有着显著差异
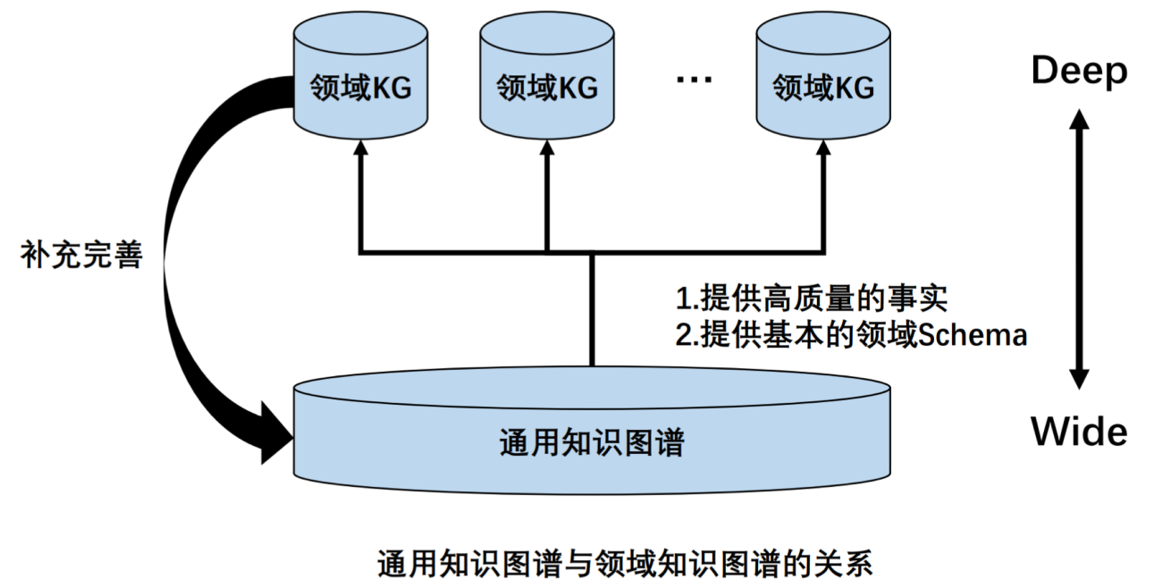
9.4. DKG和GKG的关系
- DKG是从GKD通过隐喻获得的
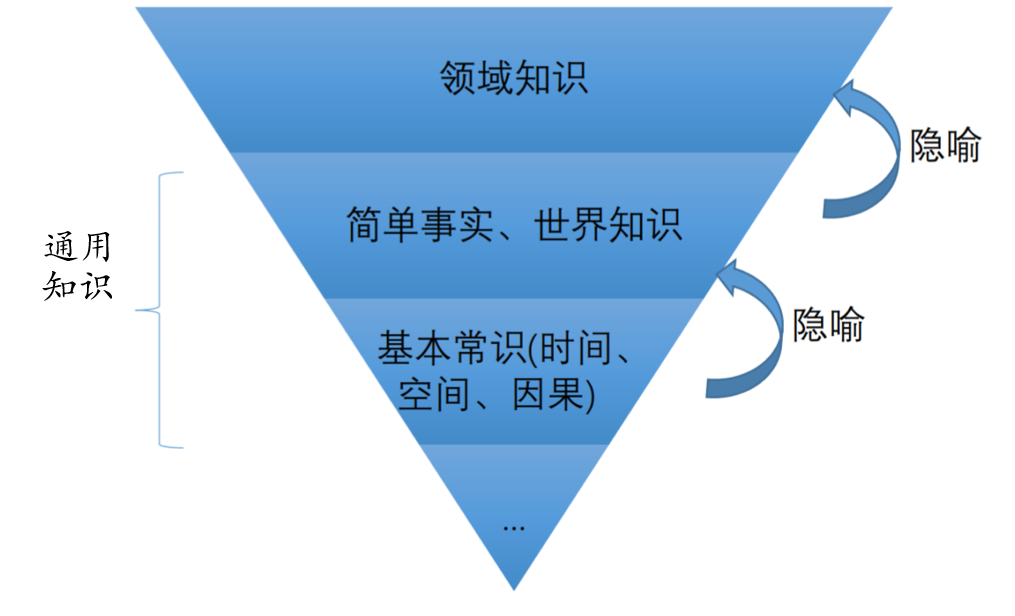
- GKG对于DKG有着显著支撑作用
9.5. 领域行业应用对于知识需求难以闭合
- 行业应用中的知识需求难以封闭于预设的领域知识边界内。
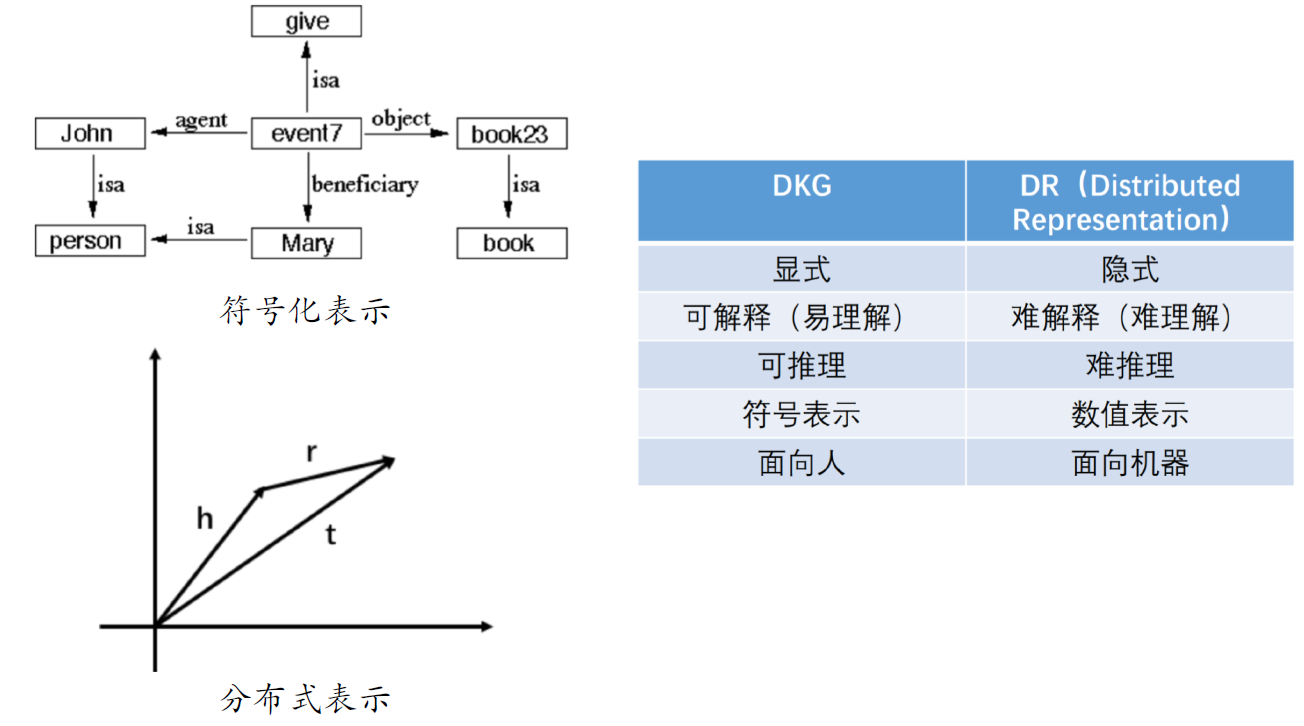
9.6. 为何需要符号化表示的知识图谱
- 符号表示与分布式表示是两种重要的知识表示形式
- 已经有两条边了,我们需要通过知识图谱推理补齐第三条边
9.7. 为什么需要领域知识图谱
- 大数据时代需要知识引擎释放大数据价值形成行业认知能力实现简单工作自动化
- 人工智能时代需要机器智脑实现自然人机交互
9.8. 将领域知识赋予机器,解放人类脑力
- 领域知识的积累与沉淀是智能化的必经路径
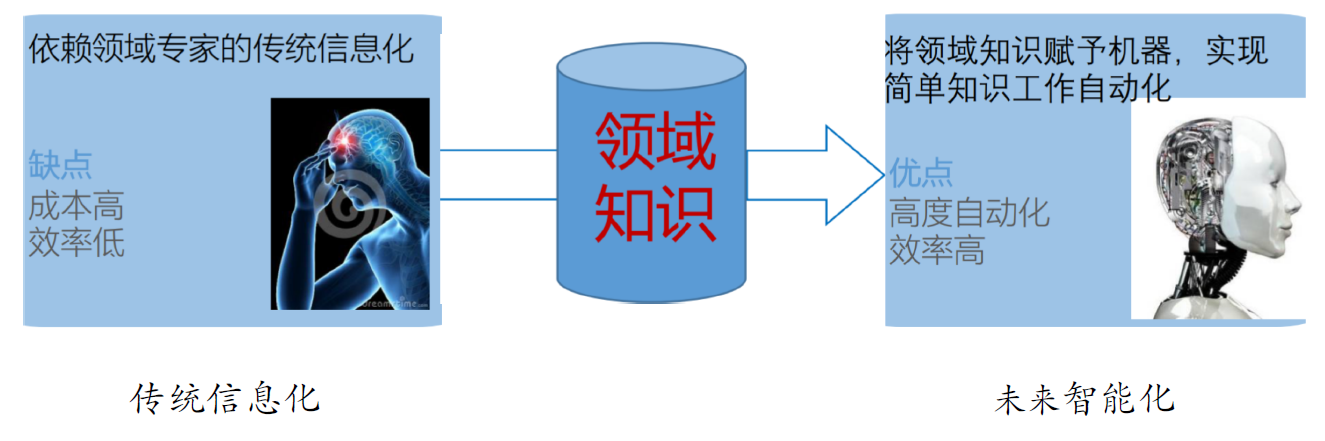
9.9. 领域知识图谱系统的生命周期
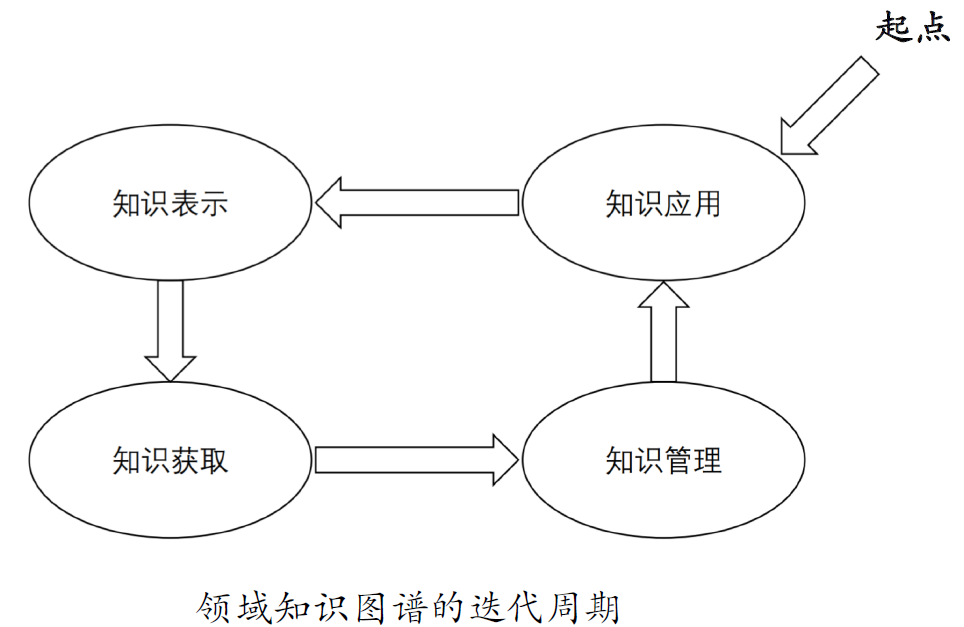
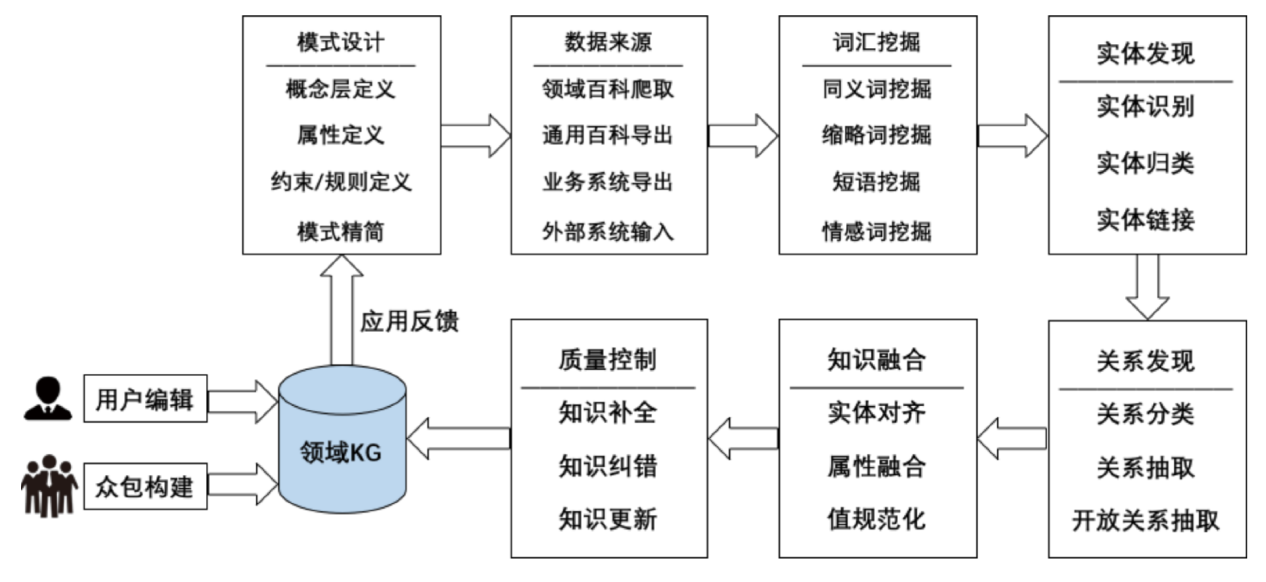
9.10. DKG如何构建
实体发现可能会用到分类聚类方法
9.11. DKG如何评价
- 质量准
- 规模全
- 实时新
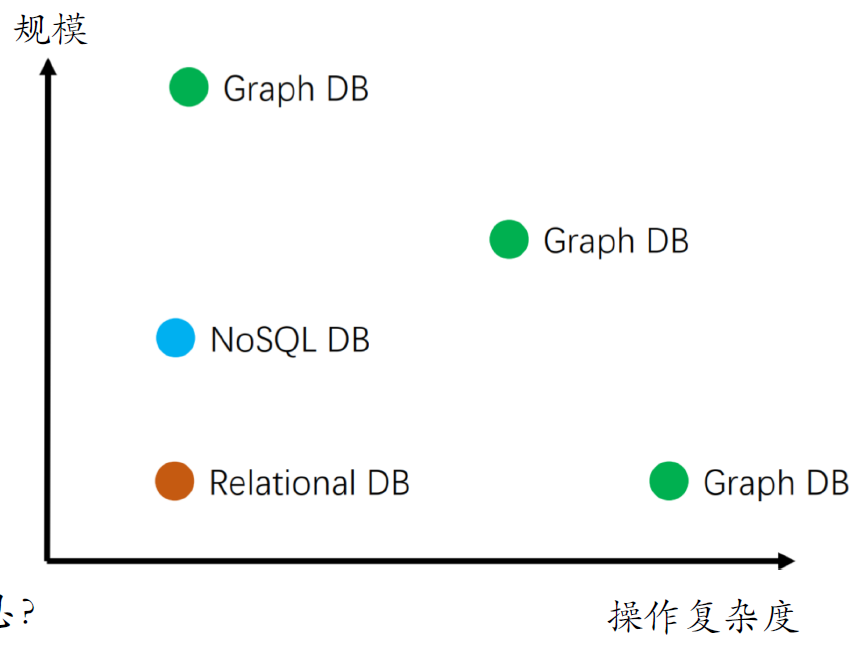
9.12. DKG如何存储
- 数据库选型依据
- 操作复杂度
- 全局计算
- 多步遍历
- 复杂子图
- 知识库规模
- 节点
- 关系
- 密度
- 操作复杂度
- 三元组中存储哪些信息?关联事实
9.13. DKG如何查询
- SPARQL
- 优点:表达能力强、可推理
- 缺点:较复杂、难书写、 复杂查询执行代价高昂
- SQL
- 优点:简单,普及
- 缺点:表达能力相对较弱
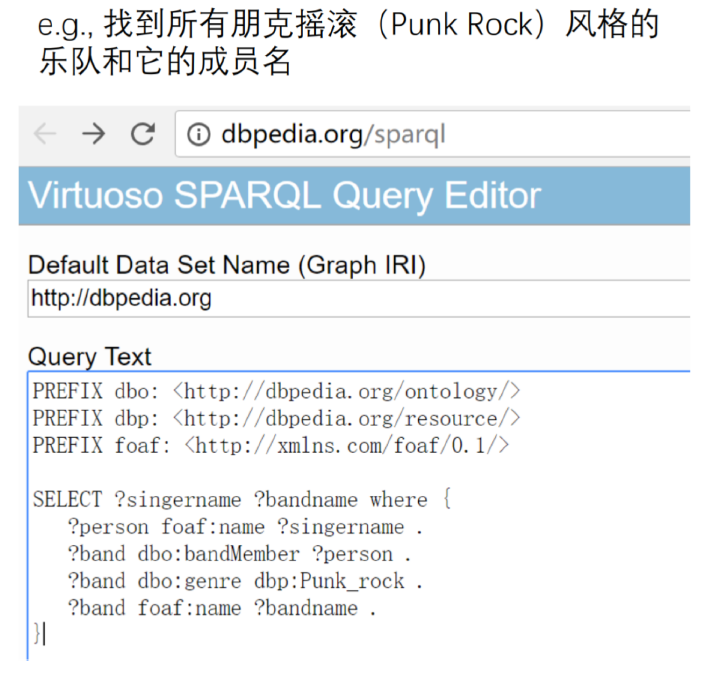
9.14. DKG应用
- 搜索
- 推荐
- 问答
- 解释
- 决策
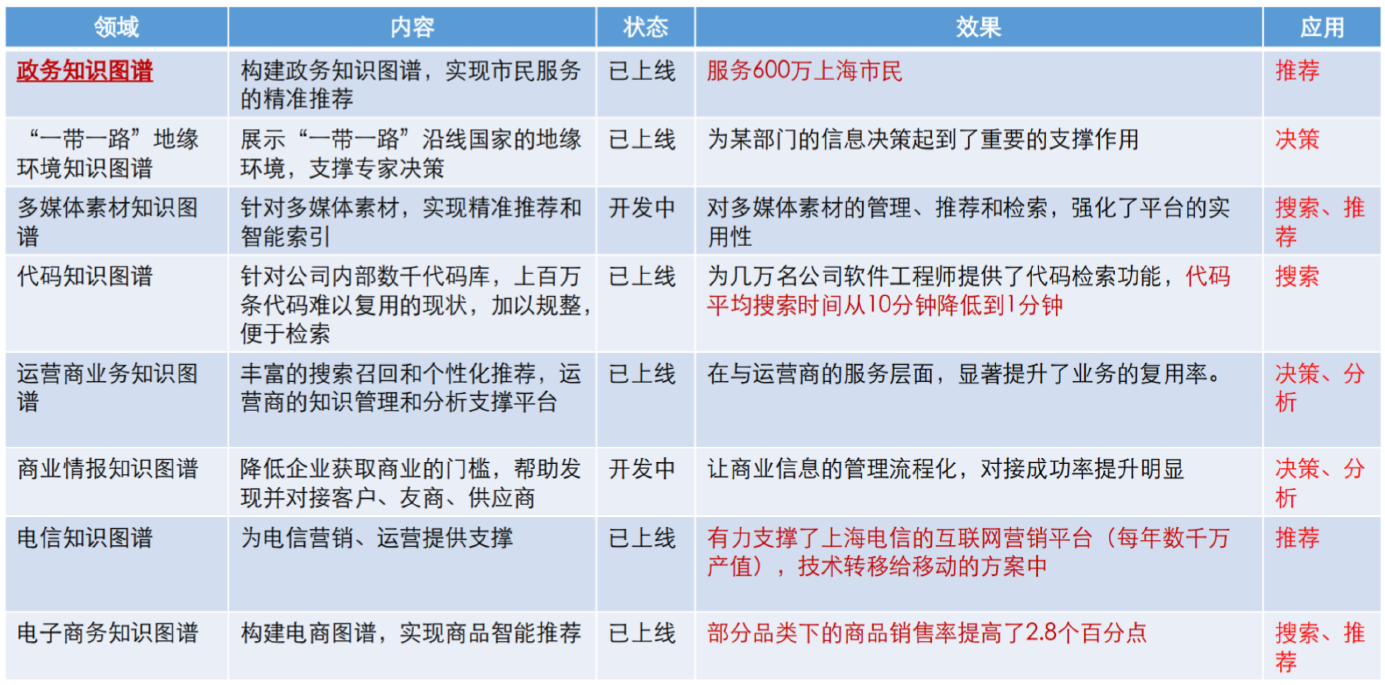
9.15. DKG落地案例
- 农业知识图谱开源项目
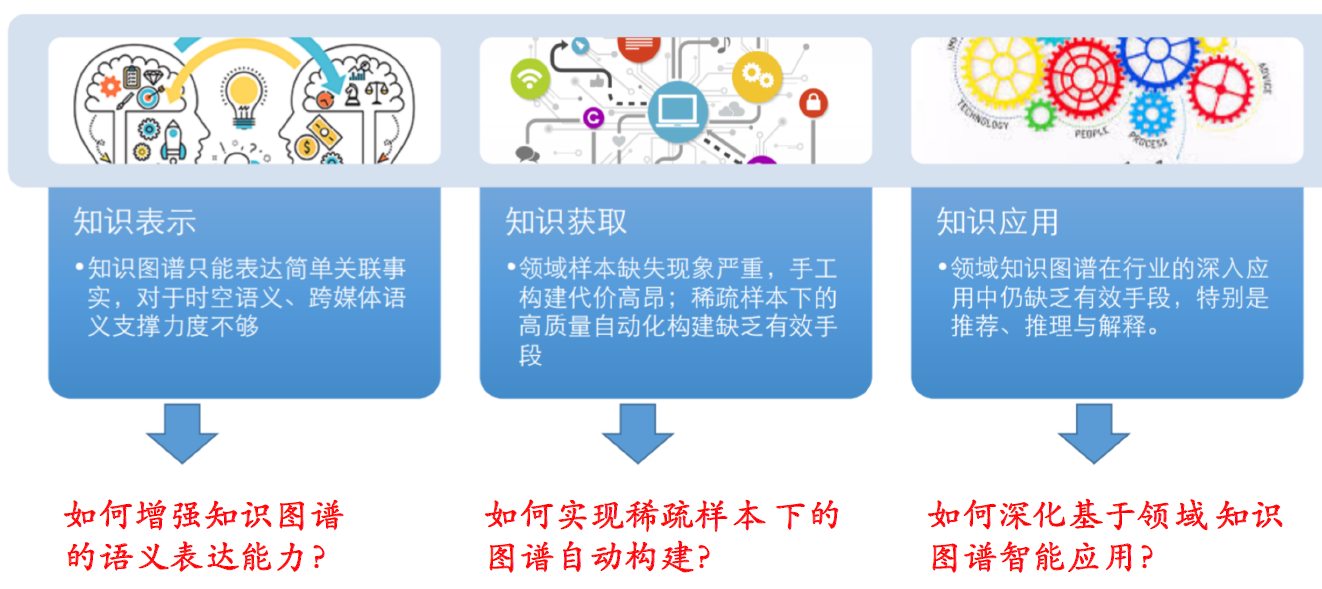
9.16. DKG还存在哪些挑战
- 知识表示
- 知识获取
- 知识应用
10. 知识图谱问答
10.1. IBM Watson
- 目前应用于医疗行业

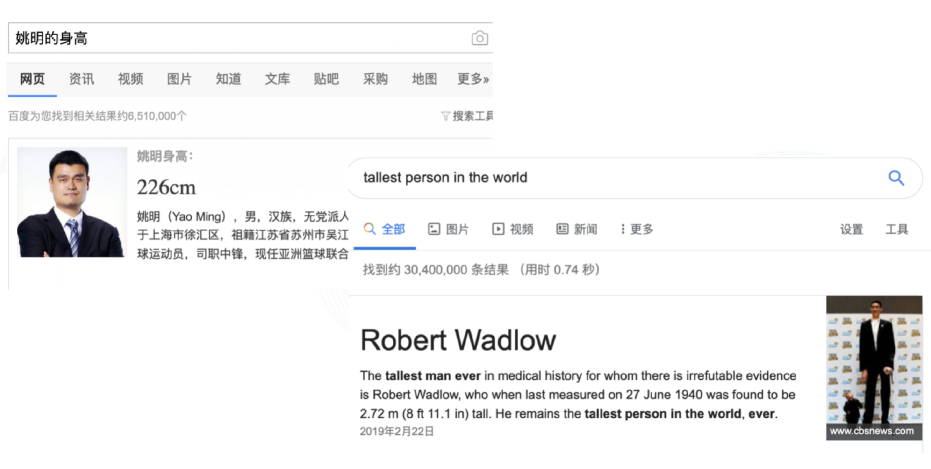
10.2. 智能搜索
- 知识卡片:根据查询实体,返回实体关联的知识信息
- 知识问答:直接明了地返回问答结果
10.3. 问答系统发展历程
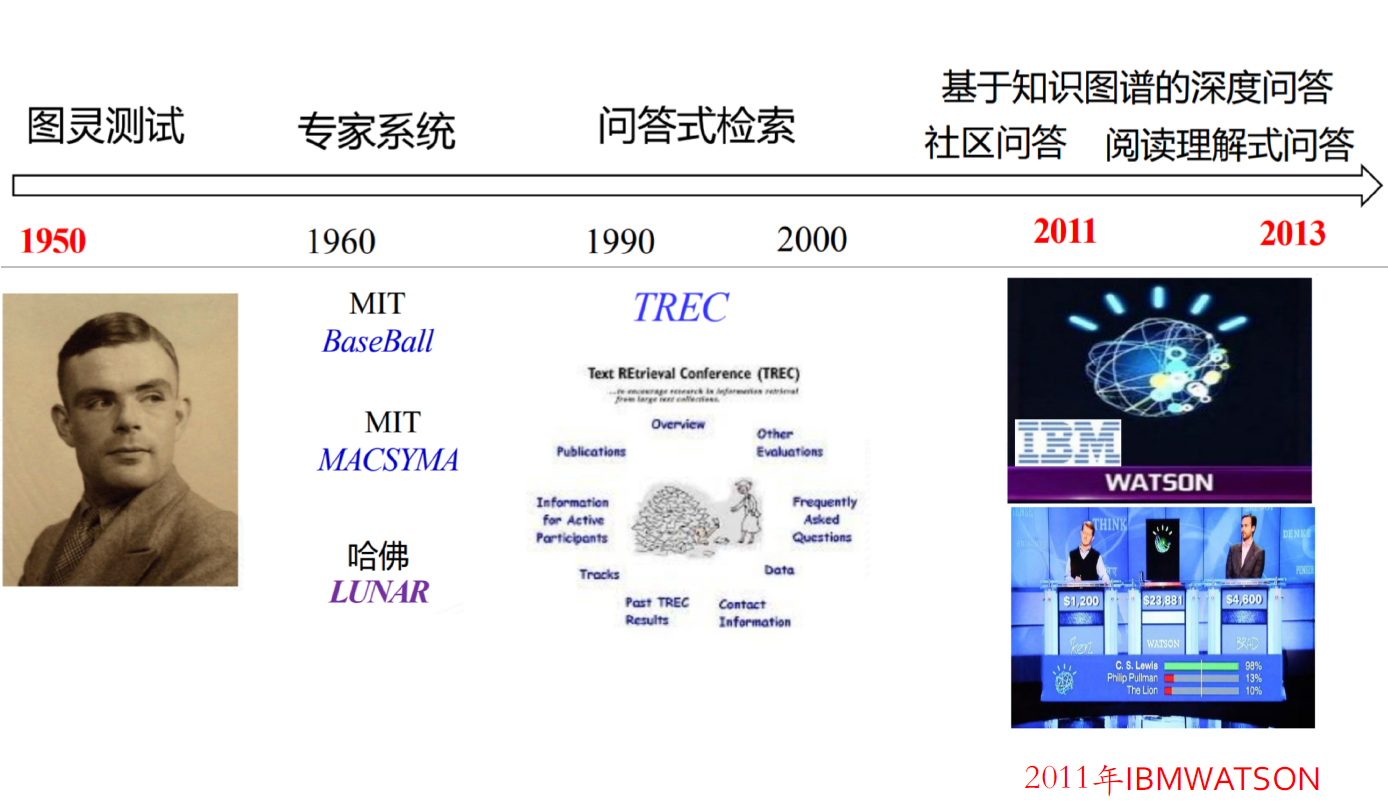
10.4. 问答系统概述
- 概述
- 问答系统(Question Answering system),指的是回答人提出的自然语言问题的系统
- 问答系统的价值
- 逐渐取代基于关键字搜索的交互方式
- 跨越人机语义鸿沟的重要尝试
- 检验机器智能的重要方式
- 问答系统的分类
- 结构化知识问答:知识图谱问答
- 非结构化知识问答
- 机器阅读理解(machine reading comprehension):基于单一文档
- 信息检索问答(IR-QA):跨文档
10.5. 问答系统问题分类
- 事实型问题:姚明的身高多少?
- 是非型问题:珠穆朗玛峰是不是世界第一高峰?
- 对比型问题:姚明和郭敬明谁更高?
- 原因/结果/方法型问题:人民币贬值之后会发生什么
- 观点型问题:你对人民币破7这个事情怎么看?
- 对话型问题:您好,我想办理A套餐
10.6. 问答系统三种范式
- 基于信息检索的问答
- 资源:QA对
- 策略:计算用户问句与问答数据库中问题之间的相似度
- 核心:相似度计算
- 基于知识库的问答
- 资源:结构化好的知识元组
- 策略:问句解析与查询转换
- 核心:问句知识抽取与知识库子图查询
- 基于阅读理解的问答
- 资源:单篇文档且答案包含在文档中
- 策略:识别答案的边界,包括起始位置和结束位置
- 核心:边界识别
10.7. 问答系统核心问题
- 信息检索问答
- 问句向量表示
- 基于传统TF-IDF的向量表示
- 基于主题的向量表示
- 基于预训练的向量表示(doc2vec, word2vec)
- 基于深度学习的向量表示
- 问句相似度计算
- Cosine向量表示
- 编辑距离
- Siamese network
- 问句向量表示
- 知识图谱问答
- 问句解析
- 意图识别
- 论元解析
- 多轮问答
- 会话状态管理
- 缺失值填充
- 问句解析
10.8. 知识图谱问答的常规做法
- 基于模板匹配的语义解析
- 思想
- 人工编写+模板学习与人工审核生成模板
- 实体识别与实体关系识别
- 查询模板匹配
- 优点
- 基于子图结构匹配,准确率高
- 缺点
- 以实体/属性/关系识别为前提
- 识别误差导致查询模板召回率低
- 思想
- 基于复述的语义解析
- 思想
- 人工根据具体查询需求,编写生成规则
- 基于规则生成标准问句集合
- 基于语义相似度进行模板匹配
- 基于模板匹配进行论元解析
- 优点:基于语义相似度,查询模板匹配召回率高
- 缺点:需要构造大量候选实例,匹配准确率不高
- 思想
10.9. 问答系统架构
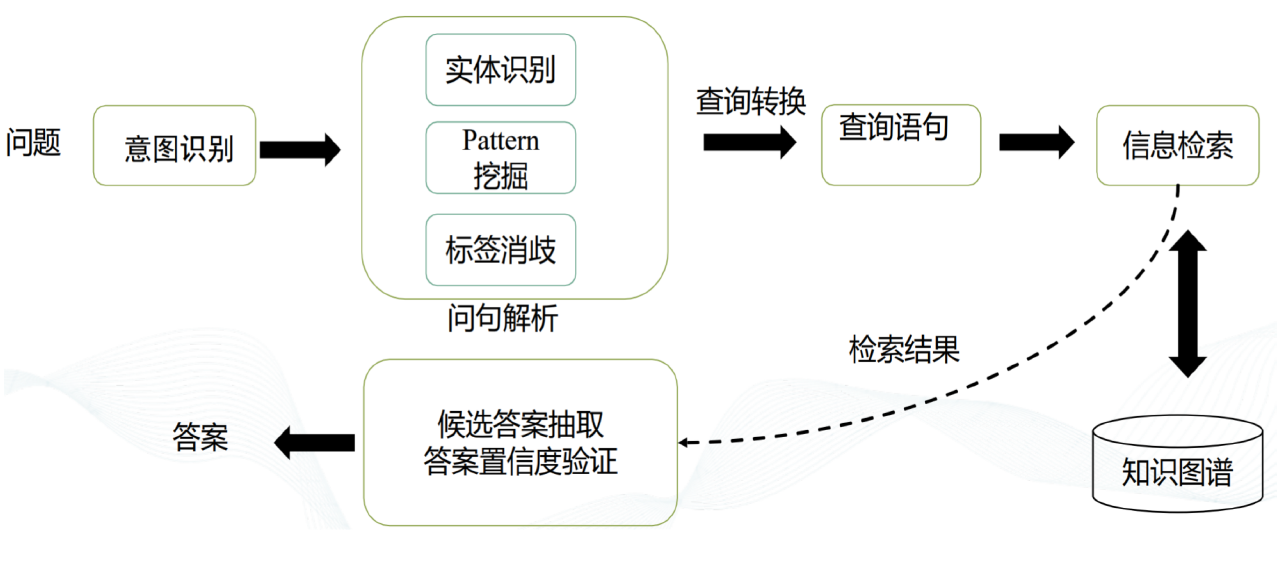
10.10. 问句解析
- 问句预处理:基于概念、实体、属性和操作符进行分词
- 问句实体项识别
- 概念、实体、属性
- 操作符(><=)
- 日期实体
- 数值实体
- 实体三元组生成
- 实体+属性、属性+对象值
- 属性值+概念
- 属性+数值
- 操作符+属性+值
- 概念+属性+值
10.11. 基于模板规则的问句解析
- 方法步骤
- "冷启动"阶段,不用训练,快速生效,适度泛化
- 内置实体抽取+ 用户自定义实体库+ 规则模板语籵:播放刘德华冰币
- 模板:[播放][singer][song]
- 模板质量判定:语籵是否自动生成模板
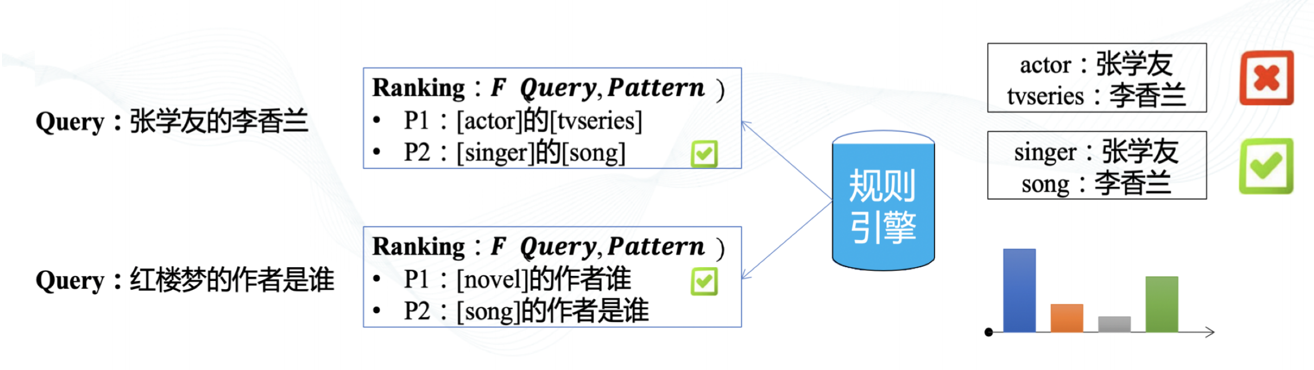
10.12. 基于统计的问句解析
- 思想:对于跨领域实体时,需要借助统计信息完成实体链接和意图分类
- Eg:我要去看花千骨的免费版
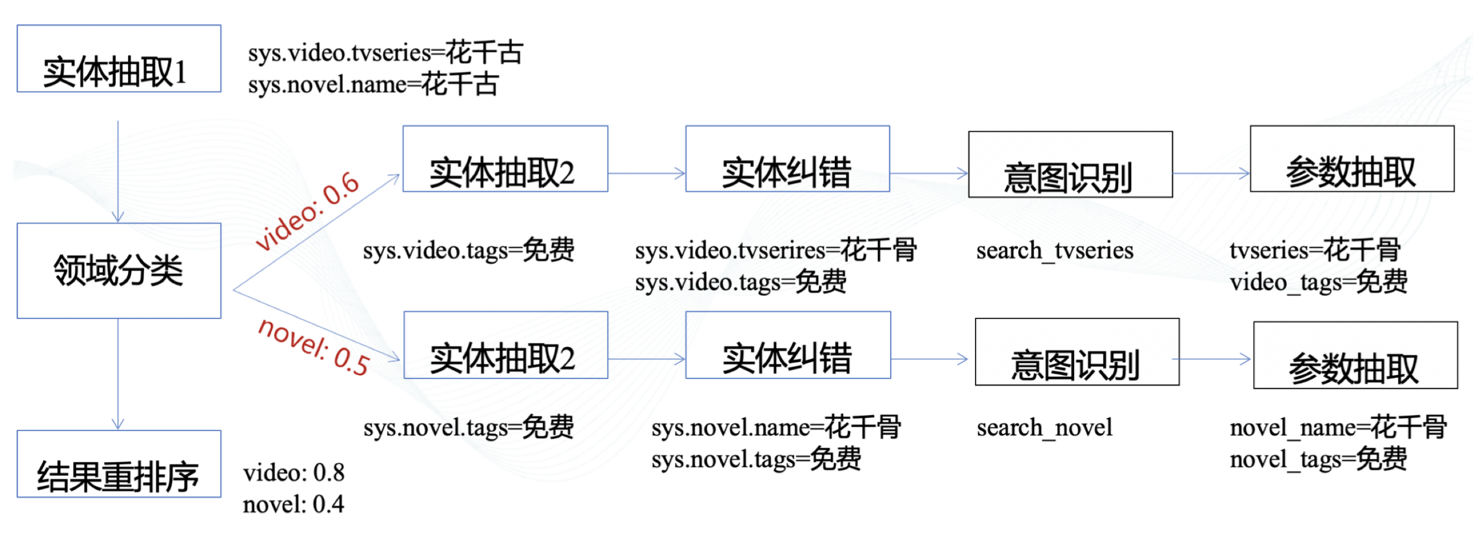
10.13. 基于深度学习的方法
- 概述:近几年卷积神经网络(CNN)和循环神经网络(RNN)在NLP领域任务中表现出来的语言表示能力, 越来越多的研究人员尝试深度学习的方法完成问答领域的关键任务,包括问题分
- 过程
- (question classification),语义匹配与答案选择
- (answer selection),答案自动生成
- (answer generation);即对用户输入解析、答案查询与检索等环节进行优化。
- 优点:实现"端到端"的问答:把问题与答案均使用复杂的特征向量表示,使用深度学习来计算问题与答案的相似度
- 不足:不支持复杂的查询;需要比较长的训练过程,不适用于现实应用场景中的知识更新后的实时查询
10.14. 智能问答面临的问题和挑战
- 复杂query的解析
- 多意图:“帮我播放音乐,打开窗户”
- xxx:“如果明天下币,提醒我关窗户”
- 其他:"帮我建一个明天C罗比赛的提醒
- 复杂多轮及上下文
- 任务型、问答、闲聊等多种技能的自由切换以及上下文传递
- U:明天西甲的比赛
- A:为你找到如下比赛:(屏幕显示"皇马对巴萨"等三场比赛)
- U:帮我建一个第二场比赛的提醒
11. KG embedding
11.1. 推荐论文
11.2. 简介
- KG Embedding主要是把实体(entities)和关系(relations)嵌入(Embed)到一个连续向量空间里面
- KG Embedding主要包含三个步骤:
- 对实体(entities)和关系(relations)进行表示
- 定义得分函数(scoring function)
- 实体和关系的表示进行学习
11.3. 模型
- KG Embedding方法被划分为两类
11.3.1. 距离变换模型(Translational distance models)


11.3.2. 语义匹配模型
- 模型有RESCAL、DistMult和HolE
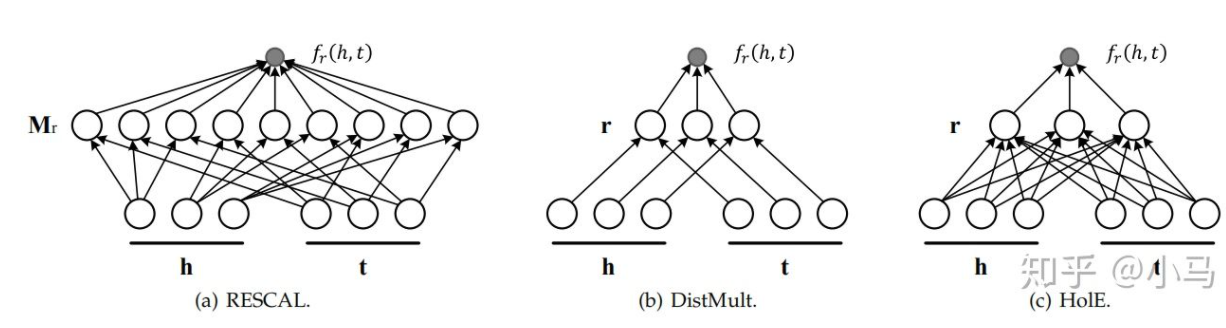
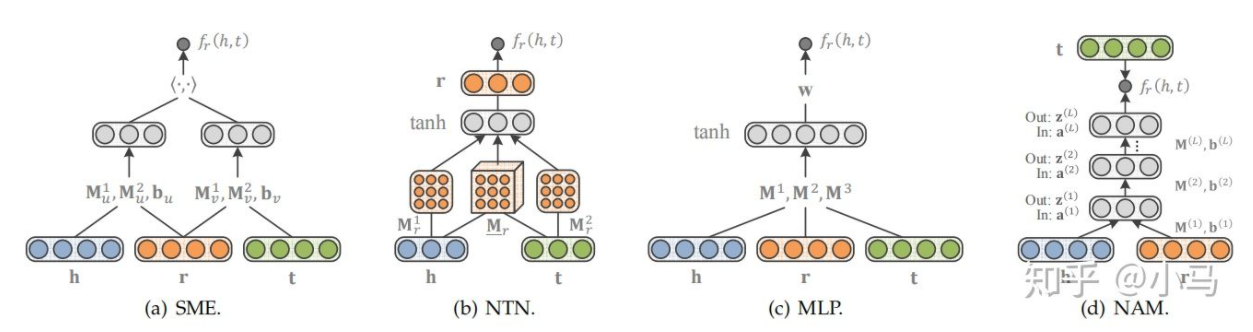
- 还有SME、NTN、MLP和NAM等方式

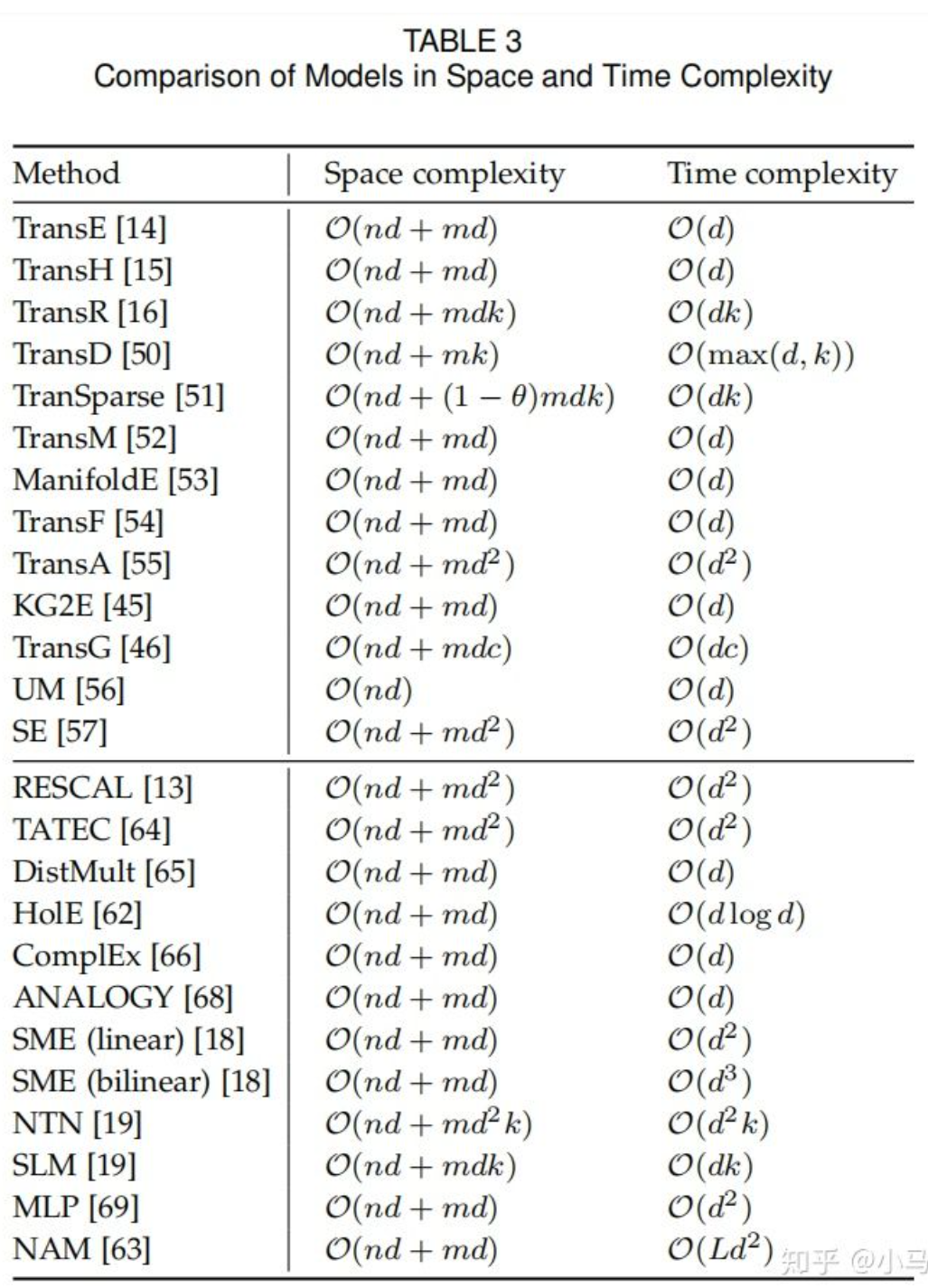
11.3.3. 不同模型的复杂度比较
11.4. 训练
- 模型训练有两种:基于开放世界假设和基于闭合世界假设
11.4.1. 开发世界假设,Training under Open World Assumption,OWA
- KGS只包含真实的事实,只存储正例
- logistic loss:
- pairwise ranking loss:
11.4.2. 闭合世界假设,Training under Cloesd World Assumption,CMA
- 没有包含在中的样例都是错误的
- squared loss:\min\limits_{\theta}\sum\limits_{h, t\in E, r\infty R(y_{hrt} - f_r(h, t))^2
11.5. 其他参考信息
- 实体类型,Entity Types
- 关系路径,Relation Paths
- 背景描述,Textual Descriptions
- 逻辑规则, Logical Rules
- 实体属性,Entity Attributes
- 临时信息,Temporal Information
- 图的结构,Graph Structures
11.6. 应用
- In-KG Applications:
- 链接预测,知识图谱补全,Link Prediction,[公式],[公式],[公式]
- 三元组分类,Triple Classifification,判断三元组事实[公式]是否为真
- 实体分类,Entity Classifification,将实体归类为不同的实体 语义类别
- 实体判别,Entity resolution,判断两个实体是否为同一个目标
- Out-of-KG Applications:
- 关系抽取, Relation Extraction
- 问答系统,Question Answering
- 推荐系统, Recommender Systems
11.7. TransE算法
- 三元组的表示:(h, r, t)含义为(头实体,关系,尾实体)
- 目标:我们找到正确的三元组,即: h + r = t
- 算法过程描述

- 注意:
- 我们需要关注的是之前的项和后面的项之间的关系,如果正确了则给予正反馈,否则基于负反馈。
- SGD的收敛效果没有GD,但是这个可以有效的避免过拟合情况的出现。
11.8. TransH算法
12. 实践项目参考
13. 知识图谱数据集介绍
14. 参考
2020-大数据分析-Lecture9-知识图谱
https://spricoder.github.io/2020/11/01/2020-Big-data-analysis/2020-Big-data-analysis-Lecture9-%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1/