2020-大数据分析-Lecture3-大数据存储和处理
Lecture3-大数据存储和处理
1. 常见存储方式
- 关系型数据库
- NoSQL:泛指非关系型数据库,比如MongoDB
- 全文检索框架:Elasticsearch
1.1. 存储的区别
- 行式存储:大数据量查询,如果没有索引,则会遍历
- 列式存储:可以大量的压缩空间
- 位图索引
位图索引的例子,如下图所示,我们可以存储为
- “男”:100101
- “女”:011010
| 行号 | 姓名 |
|---|---|
| 1 | 男 |
| 2 | 女 |
| 3 | 女 |
| 4 | 男 |
| 5 | 女 |
| 6 | 男 |
1.2. 不同形式存储的对比
| ID | name | age | sex | aihao |
|---|---|---|---|---|
| 1 | 小明 | 21 | 男 | 女 |
| 2 | 隔壁老王 | 25 | 隔壁孩子 |
- MySQL形式存储
1 | |
- HBase的形式存储:
- HBase是一个分布式列式存储系统,记录按列簇集中存放,通过主键(row, key)和主键的range来检索数据。
- HBase表中每个列都属于某一个列簇
- 列簇是表的Schame的一部分,但是列不是,列名都是以列簇作为前缀。
1 | |
- 传统表中使用Alter子句来修改表结构,而HBase直接插入就可以修改表结构
1.3. ES方式
| 文档id | 文档内容 |
|---|---|
| doc1 | how are you? fine, thank you, and you? I fine too, thank you! |
| doc2 | good morning, LiLei, good morning, Hanmeimei |
倒排索引示例:ES的存储(倒排索引)的结果如下
- 应该将查询频率高的单词放在前面(越高越前)
- ES默认将文档存储,也可以配置不存储文件信息
- TF-IDF算法:参见Tec1-TF-IDF算法
| dictionary | posting-list |
|---|---|
| fine | -> doc1 |
| Hanmei | -> doc2 |
| good | -> doc2 |
| LiLei | -> doc2 |
| … | … |
| you | -> doc1 -> doc2 |
1.4. 列存储和行存储
| 列存储 | 行存储 | |
|---|---|---|
| 关注点 | 经常关注一张表某几列而非整表数据的时候 | 关注整张表的内容,或者需要经常更新数据 |
| 计算需要 | 数据表列有非常多行数据并且需要聚集计算的时候 | 不需要聚集运算,或者快速查询需求 |
| 计算方式 | 基于一列或者比较少的列计算的时候 | 需要经常读取某行数据 |
| 数据形式 | 数据表拥有非常多的列的时候 | 数据表本身数据行并不多 |
| 数据特性 | 数据表列有非常多的重复数据,有利于高度压缩 | 数据表的列本身有太多唯一的数据 |
1.5. 读写的区别
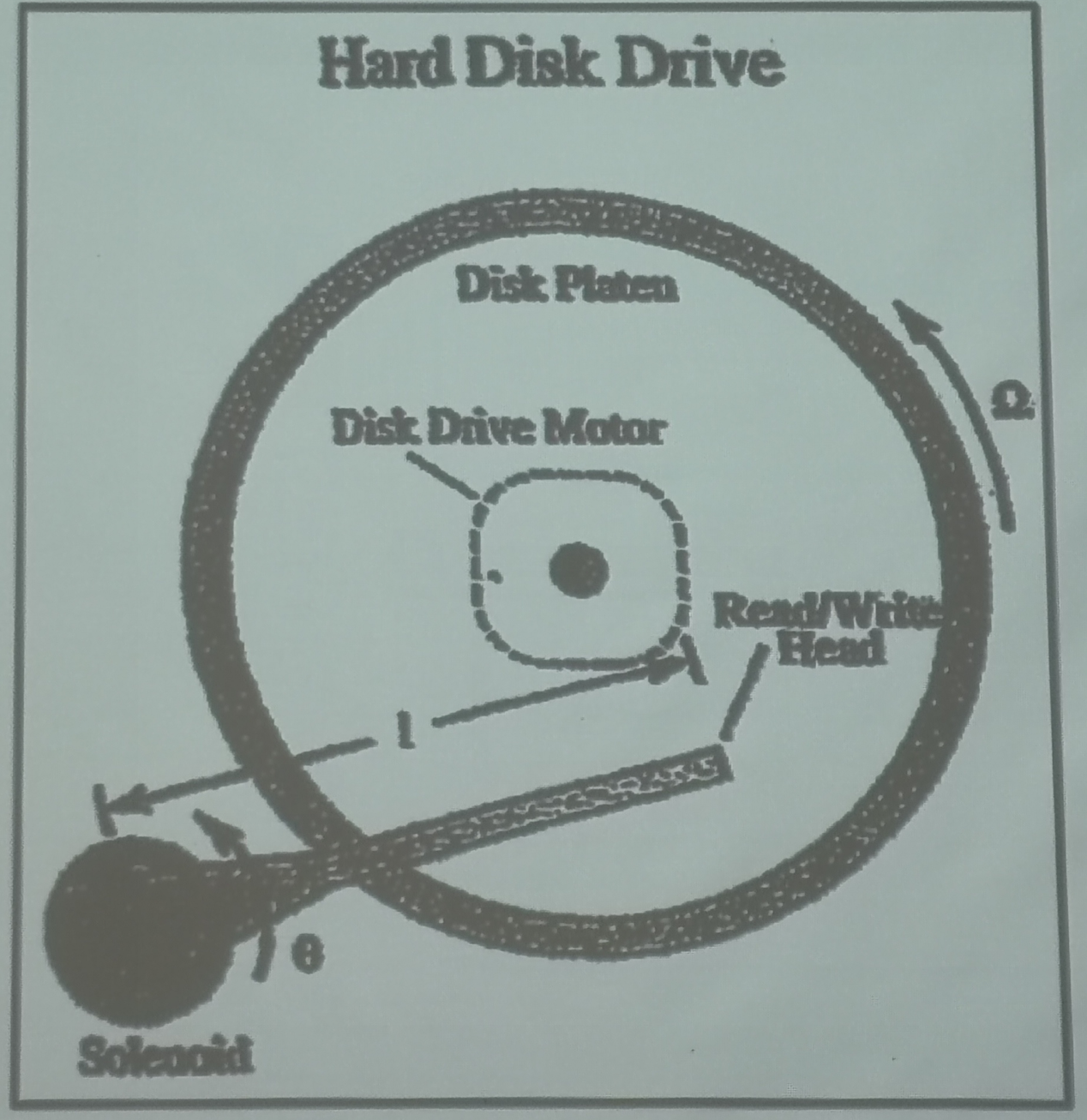
1.6. 聚簇索引和非聚簇索引
物理存储的最小的单位是块(Block)
| 聚集索引 | 非聚集索引 |
|---|---|
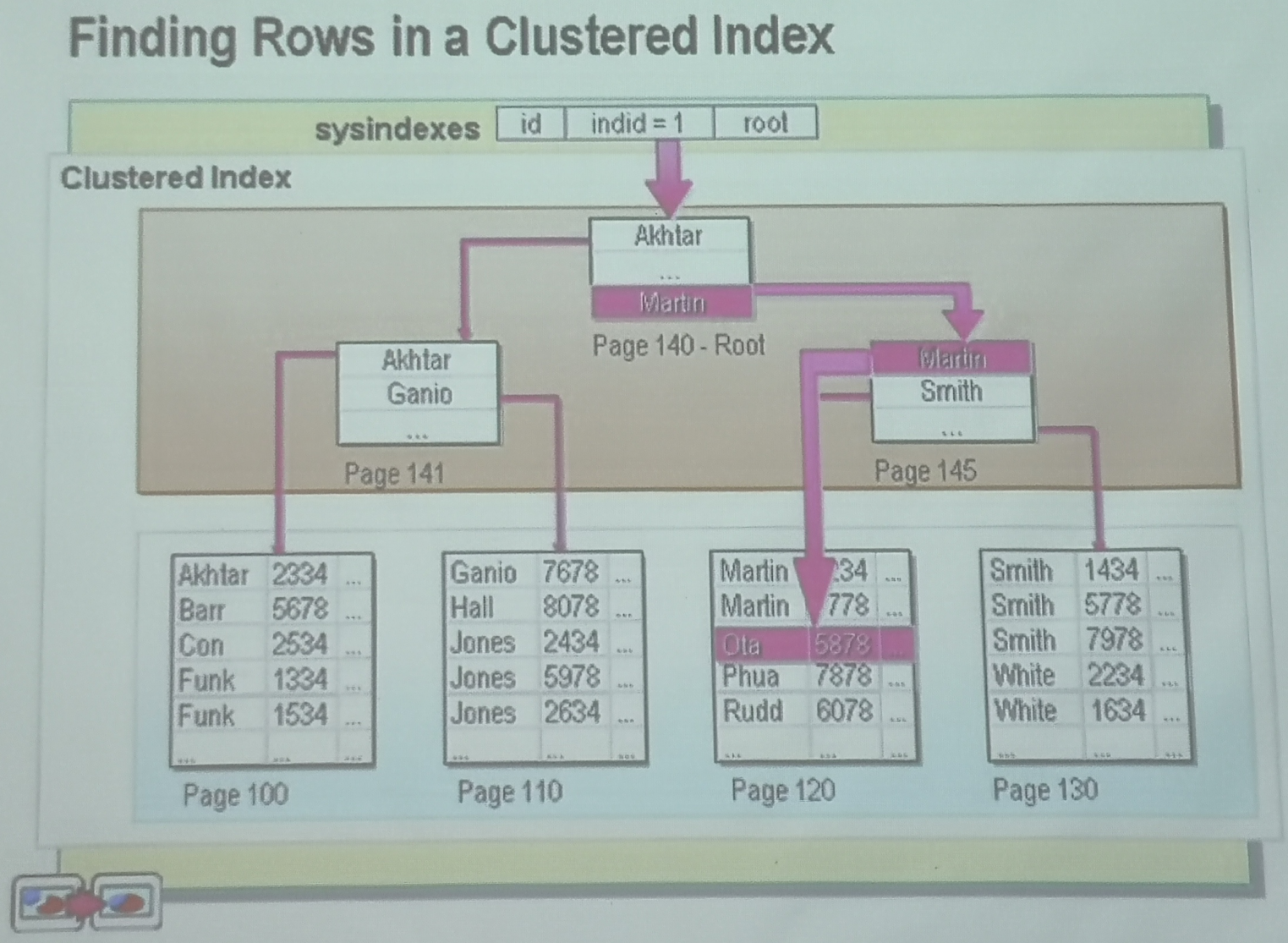 |
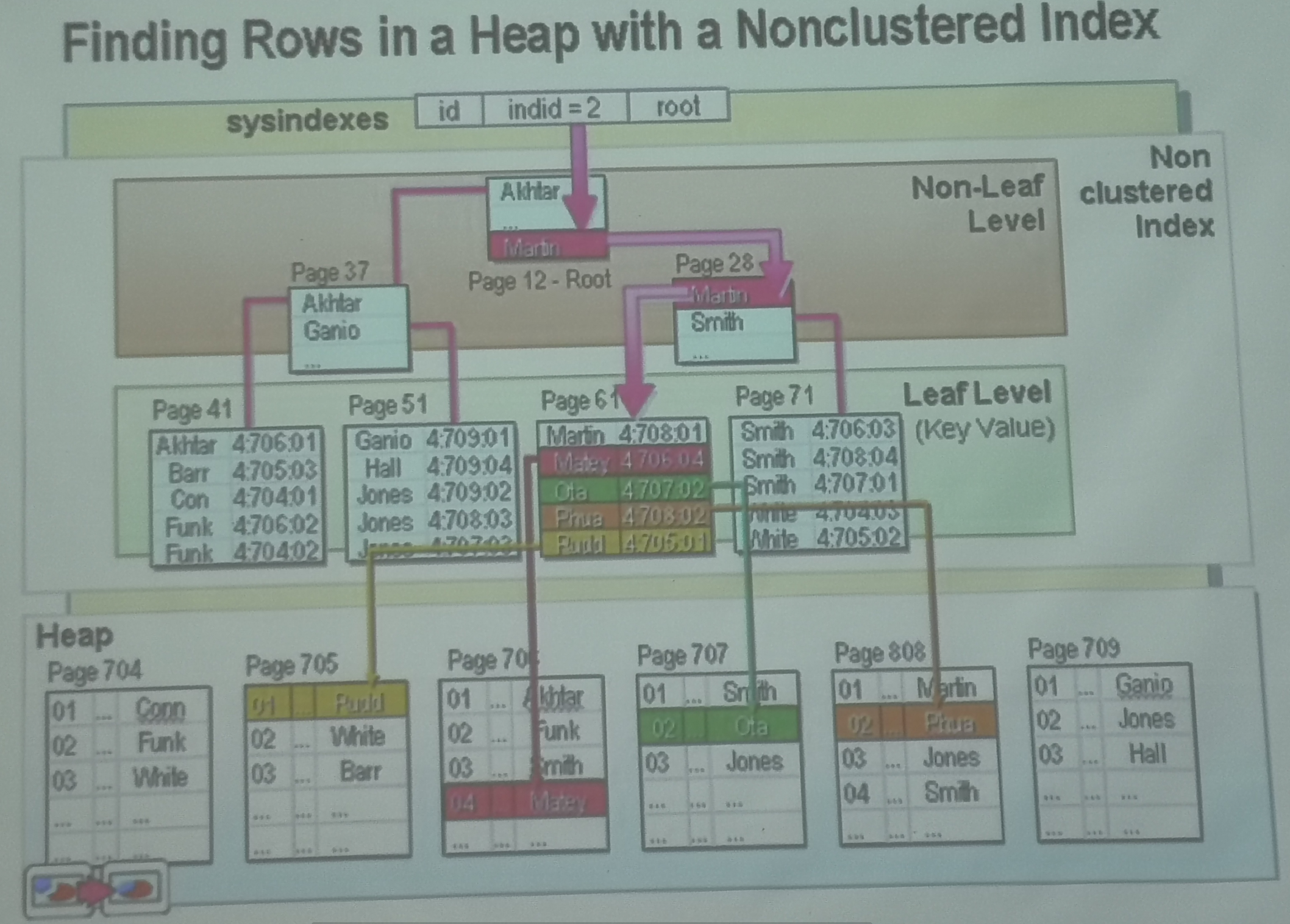 |
1.7. MySQL
- 查询:
Select (tuple) from database - 插入:
Insert into database value - 更新:
Update database set xxx = xxx where statement - 删除:
Delete from database where xxx
1.8. HBase
1.8.1. HBase对LSM的实现
LSM,Log-Structured Merge-Tree,日志结构合并树
- 假设内存非常大,有限的使用内存存储,结合日志结构实现。
- 有数据更新不是立马更新,而是先驻留数据,积累到一定条目后归并排序,然后追加到磁盘的队列中,这样子可以显著减少磁盘的开销,一次性大规模写入,减少随机的I/O,不能命中会导致较多的磁盘消耗。
1.8.2. HBase的实现
- 查询
- 插入
- 更新&删除:看做一个插入操作,使用时间戳和Delete标识来标识
memstore:插入时优先放置到memstore,驻存内存,到了一定程度后再刷新到storeFile、插入都是写入操作
1.9. ES
1.9.1. ES的部分实现方式
- 一个Node是一个进程
- 容灾的话就是多副本容灾
1.9.2. ES的操作
- 插入:和HBase相似,不是写入即可查询,建立index需要比较大的开销
- 读取
- 更新&删除
1.10. 不同存储的容灾方式
| 存储方式 | 结构 |
|---|---|
| MySQL | 单节点,包含数据、日志两个层面的操作 |
| HBase & HDFS | 分布式文件系统,每一个节点操作类似MySQL的单节点 |
| ES | 各节点备份 |
2. Hadoop介绍
Hadoop:一个Apache基金会开发的开源软件框架,支持在由普通计算机组成的集群中运行海量数据的分布式计算,他可以让应用程序轻松扩展到上千个节点和PB级别的数据。
2.1. Google 三大论文
- MapReduce
- GFS
- Big Table
2.2. Doug Cutting 山寨项目
- MapReduce
- HDFS
- HBase
2.3. 大数据处理层次架构
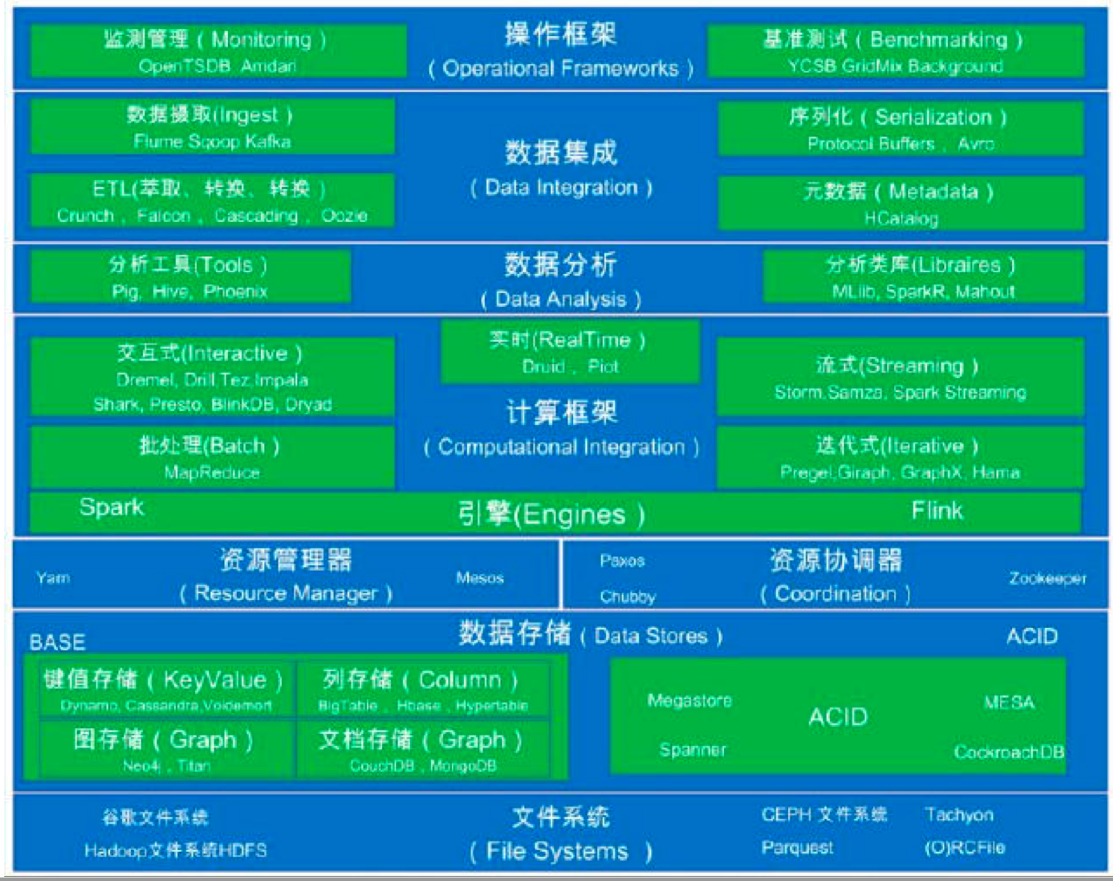
2.4. Hadoop核心
- MapReduce
- Map:任务的分解
- Reduce:结构的汇总
- HDFS
- NameNode
- DataNode
- Client
2.4.1. MapReduce
- MapReduce是一种并行编程模型,其实是分治算法的一种实现,适用于大规模数据集的并行计算
- map:
(k1,v1)->list(k2,v2) - reduce:
(k2,list(v2)) -> (k3, v3)
- map:
- 示例:曹冲称象
- 过程:
Input -> Map -> Sort -> Combine -> Partition -> Reduce -> Output

2.4.2. HDFS的基本概念
- Block
- NameNode & Secondary NameNode
- Datanode
2.4.3. HDFS架构

2.4.3.1. Block
- 块大小默认为64M(v1.0)
- 块大小默认为128M(v2.0)
- 数据和元数据

- 备份
- 一次写入多次读取
2.4.3.2. NameNode
- 可以看做是分布式文件系统中的管理者,存储文件系统的metadata,主要负责管理文件系统的命名空间,集群配置信息,存储块的赋值
- 两个文件:EditLog、FSImage
- 两个映射:
Filename -> BlockSequence(FsImage)、Block -> DatanodeList(BlockReport) - 单点(NameNode)风险
2.4.3.3. Secondary NameNode
- 不是备用NameNode,而是秘书
- 合并和保存EditLog、FSImage
- Checkpoint.period
- Checkpoint.size
2.4.3.4. Datanode
文件存储的基本单位。它存储文件块在本地文件系统中,保存了文件块的meta-data,同时周期性的发送所有存在的文件块的报错给Namenode
2.4.3.5. HDFS文件读写
读文件:读取完之后会校验(Check Sum),未通过则告知错误
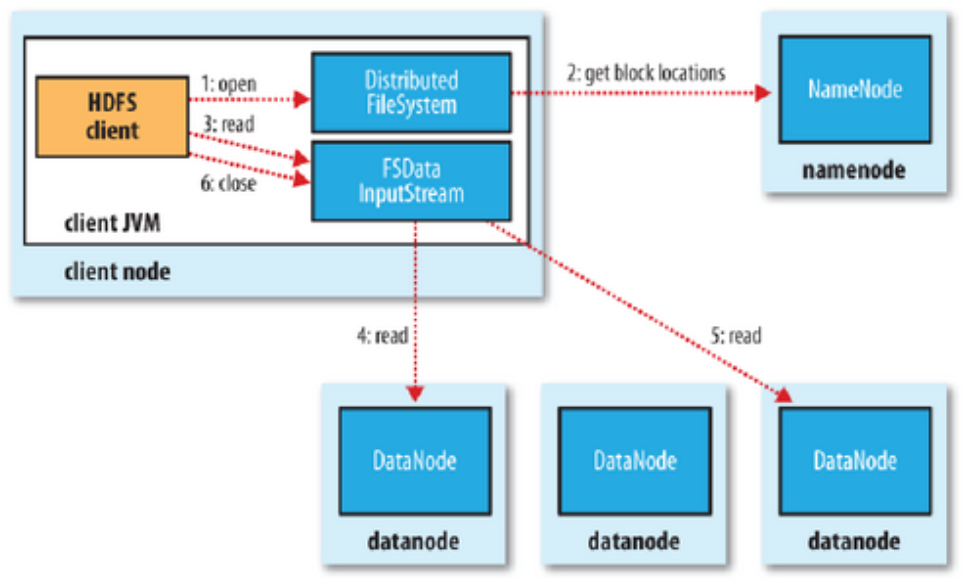
写文件:复制的策略,冗余数据放置在机柜中,跨机柜要经过交换机等设备
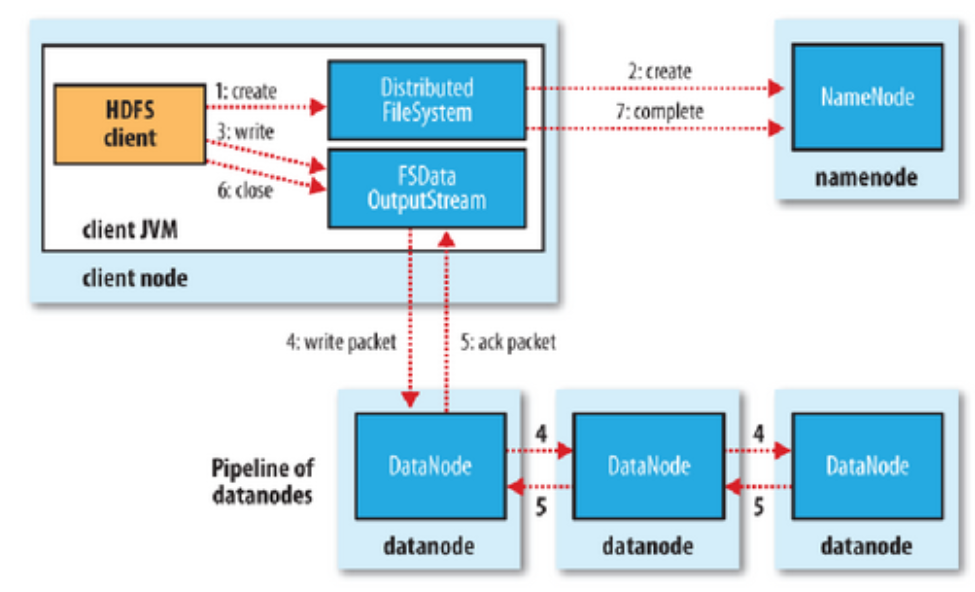
3. HBase
- HBase以谷歌的BigTable为模型,并用Java编写
- HBase是在HDFS上开发,提供了一种容错的方式存储大量的稀疏数据
- 一个HBase系统包括一组表,每个表包含行和列,就像传统的数据库一样。每个表都必须有一个定义为主键的元素,所有对HBase表的访问尝试都必须使用这个主键。一个HBase Column表示一个对象属性。
3.1. 什么是HBase
- HBase是一个分布式、非结构化、稀疏、面向列的数据库。
- HBase是基于HDFS,山寨版的BigTable,继承了可靠性、高性能、可伸缩性
3.2. HBase架构
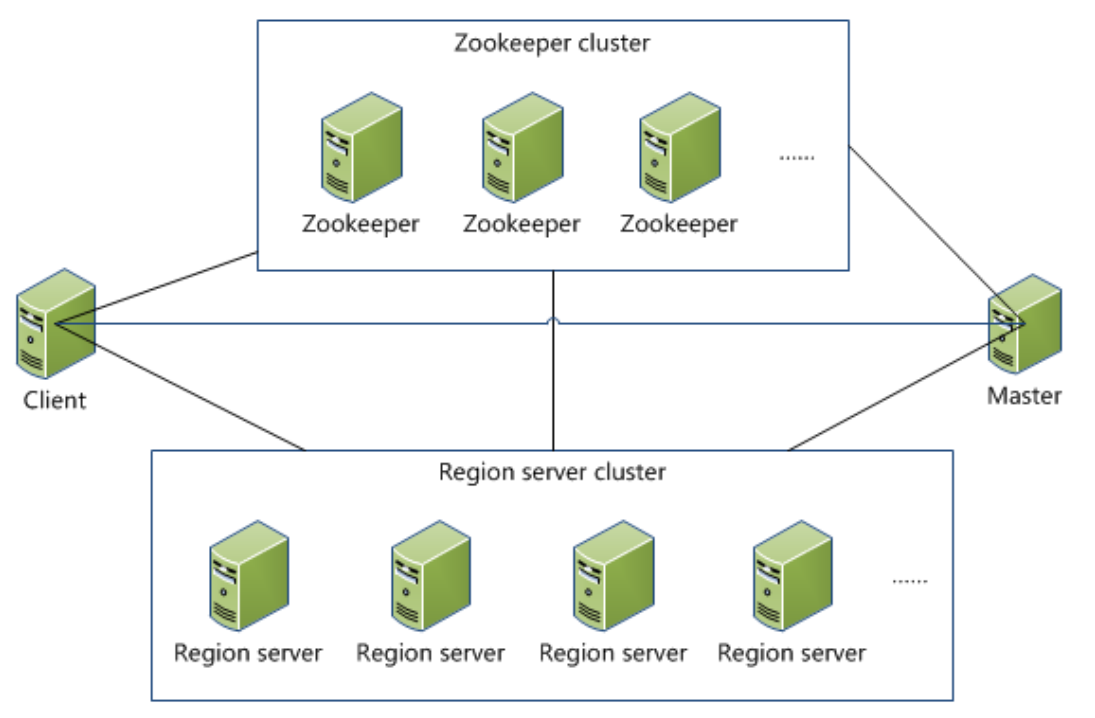
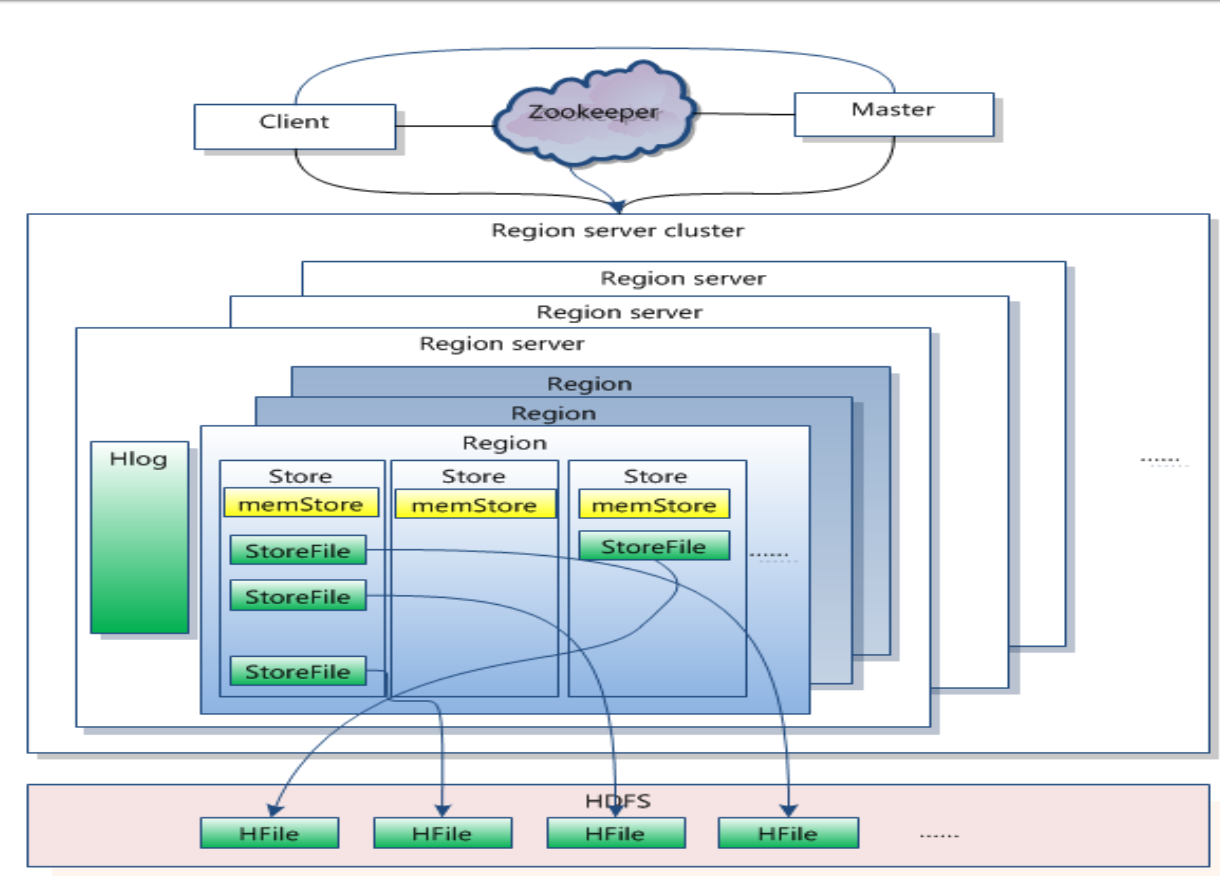
3.3. HBase角色
| 角色 | 内容描述 |
|---|---|
| ZooKeeper | 1. 一个高效的、可扩展的协调系统 2. Hadoop的子项目,不属于HBase |
| HMaster | 1. 管理网络对Table的增、删、改、查操作 2. 管理HRegionServer负载均衡 |
| HRegionServer | 1. 管理一系列HRegion 2. Region读写的场所 |

| 角色 | 内容描述 |
|---|---|
| HRegion | 1. 对应Table的Region 2. HStore和HLog |
| HStore | 1. 对应了Table中的一个Column Family的存储 2. MemStore 3. StoreFile(HFile) |
| StoreFile | 1. Compact 2. Split |
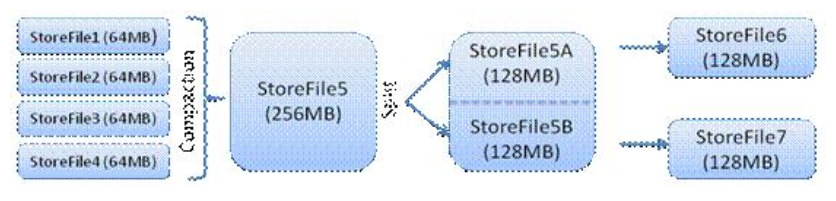
3.4. HBase数据模型
Table & Column Family
- RowKey:Table的主键, 记录按照RowKey排序
- Timestamp:每次数据操作对应的时间戳,可以看作是数据的version number(垃圾清理)
- Column Family:Table在水平方向由一个或者多个Column Family组成,一个Column Family中可以由任意多个Colum组成

Table & Region
- 记录数不断增多后,Table会逐渐分裂成多份splits,成为regions
- 一个region由[startkey,endkey)表示
- 不同的region会被Master分配给相应的RegionServer进行管理.
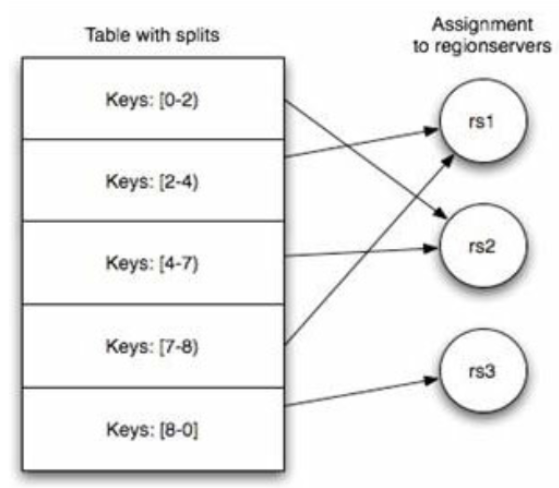
.META.:记录用户表的Region信息,可以有多个regoin-ROOT-:记录.META.表的Region信息,只有一个regionZookeeper:记录了-ROOT-表的location

3.5. 数据导入
- Sybase -> HBase
- bcp out
- importtsv
1 | |
3.6. 访问接口
- Hadoop & HBase提供JAVA接口
- Thrift支持多语言访问HBase,C++、C#、Cocoa、Erlang、Haskell、Java、Ocami、Perl、PHP、Python、Ruby、Smalltalk
4. Hive
- Hive是基于Hadoop的数据仓库工具,提供完整的SQL查询功能,可以将结构化的数据文件映射为一张数据库表。
- 可以将SQL语句转换为MapReduce任务进行运行。
- 可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用
- 学习成本低
4.1. Hive体系结构
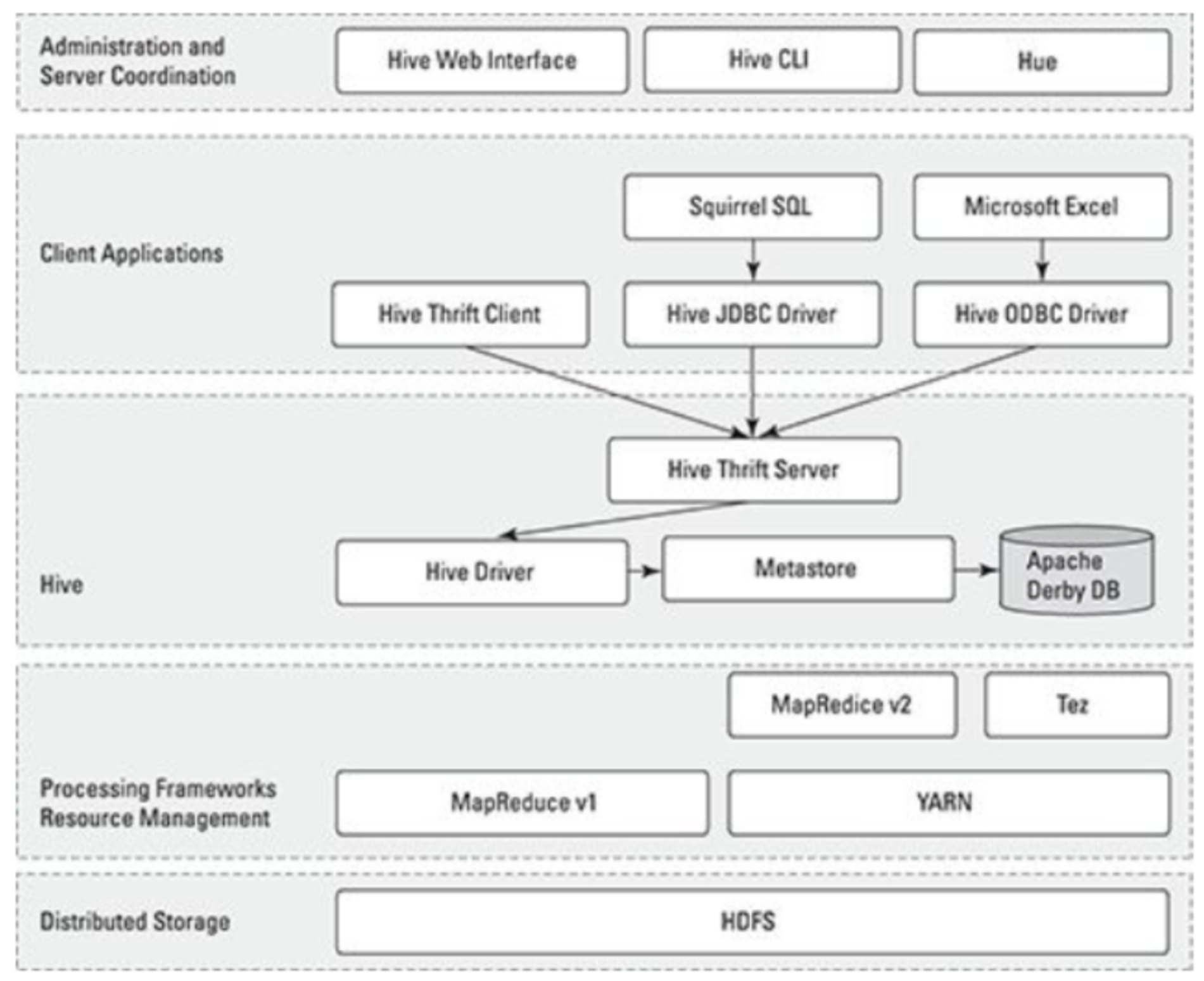
4.2. Hive运维要点
Hive相当于一套Hadoop的访问接口,运维如下几个问题需要注意
- 使用单独的数据库存储元数据
- 定义合理的表分区和键
- 设置合理的bucket数据量
- 进行表压缩
- 定义外部表使用规范
- 合理的控制Mapper,Reducer数量
5. Pig
Apache Pig架构
- 严格用于使用Pig分析Hadoop中的数据的语言称为Pig Latin是一种高级数据处理语言。它提供了一组丰富的数据类型和操作符来对数据执行各种操作。
- 要执行特定任务时,程序员使用Pig,需要用Pig Latin语言编写Pig脚本,并使用任何执行机制( Grunt Shell,UDFs,Embedded )执行它们。执行后,这些脚本将通过应用Pig框架的一系列转换来生成所需的输出。
- 在内部, Apache Pig将这些脚本转换为一系列MapReduce作业,因此,它使程序员的工作变得容易。
5.1. Pig组成组成
- Parser (解析器):最初, Pig脚本由解析器处理,它检查脚本的语法,类型检查和其他杂项检查。解析器的输出将是DAG(有向无环图),它表示Pig Latin语句和逻辑运算符。在DAG中,脚本的逻辑运算符表示为节点,数据流表示为边。
- Optimizer (优化器):逻辑计划(DAG)传递到逻辑优化器,逻辑优化器执行逻辑优化,例如投影和下推。
- Compiler (编译器):编译器将优化的逻辑计划编译为一系列MapReduce作业。
- Execution engine (执行引擎):最后,MapReduce作业以排序顺序提交到Hadoop。这些MapReduce作业在Hadoop上执行,产生所需的结果。
5.2. Pig与SQL区别
- 使用延迟评价、使用ETL、能够在管道中任何时刻存储数据、支持管道分裂
- Pig Latin是程序性的,它在管道范例中非常自然,而SQL则是声明性的。在SQL用户中,可以指定要连接两个表的数据,但不能指定要使用的连接实现。
- Pig Latin允许用户指定一个实现或实现的各个方面 ,以在多个方面执行脚本。Pig Latin编程类似于 指定查询执行计划。
6. 参考
2020-大数据分析-Lecture3-大数据存储和处理
https://spricoder.github.io/2020/11/01/2020-Big-data-analysis/2020-Big-data-analysis-Lecture3-%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%AD%98%E5%82%A8%E5%92%8C%E5%A4%84%E7%90%86/