2020-大数据分析-Exam-整理
Exam-整理
1. 选择题
- 设计分布式数据仓库Hive的数据表时,为取样更高效,一般可以对表中的连续字段进行分桶操作。
- 客户端首次查询HBase数据库时,首先需要从
-ROOT-表开始查找。 - HBase的Region组成中,必须要有MemStore项。
- HBase是分布式列式存储系统,记录按列族集中存放。
- HBase数据库的BlockCache缓存的数据块中,普通的数据块不一定能提高效率。
- 视频监控数据属于非结构化数据
- MapReduce编程模型,键值对
<key, value>的key必须实现WritableComparable - 若不针对MapReduce编程模型中的key和value值进行特别设置,Average是MapReduce不适宜的运算。
- 在实验集群的master节点使用jps命令查看进程时,终端出现
Namenode,JobTracker, Secondary NameNode能说明Hadoop主节点启动成功 - Client 端上传文件的时候下列哪项正确?B
- A. 数据经过 NameNode 传递给 DataNode
- B. Client 端将文件切分为 Block,依次上传
- C. Client 只上传数据到一台 DataNode,然后由 NameNode 负责 Block 复制工作
- D. 以上都不正确
- Hadoop1.0默认的调度器策略是先进先出调度器
- JobTracker负责 MapReduce 任务调度
- HDFS1.0 默认 Block Size大小是 64MB
- HDFS 中的 block 默认保存3个备份
- Datanode负责 HDFS 数据存储。
2. 判断题
- Hadoop 支持数据的随机读写。(错,Hbase支持,Hadoop不支持)
- NameNode 负责管理元数据信息metadata,client 端每次读写请求,它都会从磁盘中读取或会写入 metadata 信息并反馈给 client 端。(错,内存中读取)
- MapReduce 的 input split 一定是一个 block。(错,默认是)
- MapReduce适于PB级别以上的海量数据在线处理。(错,离线)
- 链式MapReduce计算中,对任意一个MapReduce作业,Map和Reduce阶段可以有无限个Mapper,但Reducer只能有一个。( 对)
- MapReduce计算过程中,相同的key默认会被发送到同一个reduce task处理。(对)
- HBase对于NULL的列,不需要占用存储空间。(没有则空不存储,对)
- HBase可以有列,可以没有列族(column family)。 (错,有列族)
3. 简答题
3.1. 简述大数据技术的特点
- Volume(大体量):即可从数百TB到数十数百PB、甚至EB规模。
- Variety(多样性):即大数据包括各种格式和形态的数据。
- Velocity(时效性):即很多大数据需要在一定的时间限度下得到及时处理。
- Veracity(准确性):即处理的结果要保证一定的准确性。
- Value(大价值):即大数据包含很多深度的价值,大数据分析挖掘和利用带来巨大的商业价值。
3.2. 启动Hadoop系统,当使用bin/start-all.sh命令启动时,请给出集群各进程启动顺序
- 启动顺序:namenode –> datanode -> secondarynamenode -> resourcemanager -> nodemanager
3.3. 简述HBase的主要技术特点
- 列式存储
- 表数据是稀疏的多维映射表
- 读写的严格一致性
- 提供很高的数据读写速度
- 良好的线性可扩展性
- 提供海量数据
- 数据会自动分片
- 对于数据故障,hbase是有自动的失效检测和恢复能力。
- 提供了方便的与HDFS和MAPREDUCE集成的能力。
4. 年:2019
4.1. 选择题
- HDFS 2.x 的默认块大小:128MB
- 社交网络的商业模式是长尾模式(疑问,还是二八模式)
- 不是hadoop的默认集群运行模式:微服务式
- standalone(独立式)
- 伪分布
- 分布式
- 微服务式
- 以下哪种不是Spark的库:Storm
- SparkSQL
- GraphX
- MLlib
- Storm
- tasktracker运行在hdfs的哪个程序上:datanode
- namenode
- datanode
- secondarynodee
- jobtracker
4.2. 判断题
- namenode是HDFS集群的主节点,负责维护整个HDFS系统的文件目录树,和各个路径/文件的块信息。对
- jaccard距离用于度量集合距离,定义是两集合的交集中的元素个数除以并集中的元素个数。对
- 决策边界指N维空间中用于区分不同类别样本的平面或者曲面。对
- HBase是基于行的NoSQL。错(列)
4.3. 计算题
- pagerank:初始每张网页的权重相等,写出转移矩阵和一次迭代后的page rank值
1 | |
- 奇异值分解,奇异值分解如下矩阵
4.4. 简答题
- 聚类中,计算类簇间的距离时,有哪些可能的计算方向和方法(提示,距离,link,类簇的表示)
- 举例并描述在社区计算中常见的计算任务(20分) (列举即可,至少四类)
- 简述推荐系统的三大问题,并说说推荐系统评分中的Explict和Implict各有什么样的例子?
5. 数据挖掘是什么?
- 给定大量数据的情况,三维那张图片,有哪些挑战
5.1. 大数据挑战
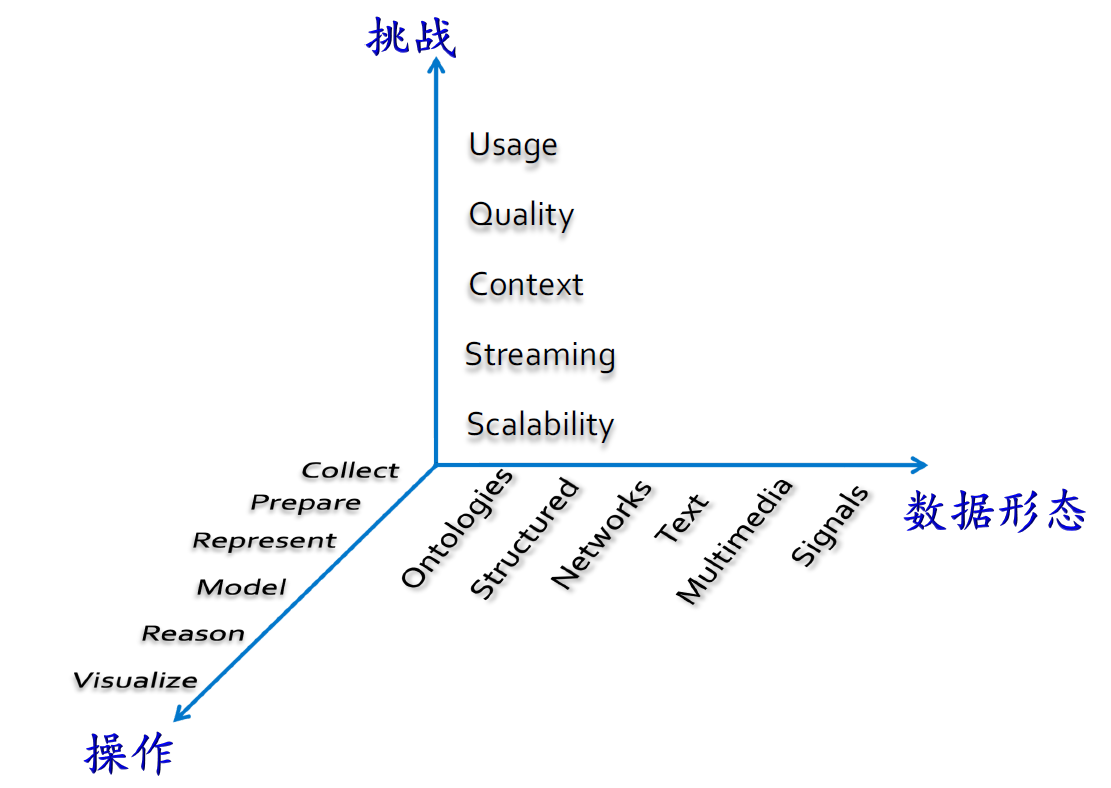
5.1.1. 挑战
- Usage:使用
- Quality:质量
- Context:内容
- Streaming:数据流动,大量的算法
- Scalability:可扩展性
5.1.2. 数据形态
- Ontologies:源数据
- Structed:结构化
- Networks:网络
- Text:文本
- Multimedia:流媒体
- Signals:信号
5.1.3. 操作
- Collect:收集
- Prepare:准备,数据的值是不是为空
- Represent:表示
- Model:模型
- Reason:原因(验证)
- Visualize:可视化
5.2. 发现具有以下特征的模型(模型)
- 有效性
- 可用性
- 出乎意料
- 可理解性
6. Hadoop
6.1. Hadoop生态圈
都是干什么的,特征是什么

6.1.1. MapReduce并行计算框架
- MapReduce并行计算框架是一个并行化程序执行系统。它提供了一个包含Map和Reduce两阶段的并行处理模型和过程,提供一个并行化编程模型和接口,让程序员可以方便快速地编写出大数据并行处理程序。
- MapReduce以键值对数据输入方式来处理数据,并能自动完成数据的划分和调度管理。
- 在程序执行时,MapReduce并行计算框架将负责调度和分配计算资源,划分和输入输出数据,调度程序的执行,监控程序的执行状态,并负责程序执行时各计算节点的同步以及中间结果的收集整理。
- MapReduce框架提供了一组完整的供程序员开发的MapReduce应用程序的编程接口。
6.1.2. 分布式文件系统HDFS
- HDFS(Hadoop Distributed File System)是一个类似于GoogleGFS的开源的分布式文件系统。
- 它提供了一个可扩展、高可靠、高可用的大规模数据分布式存储管理系统,基于物理上分布在各个数据存储节点的本地Linux系统的文件系统,为上层应用程序提供了一个逻辑上成为整体的大规模数据存储文件系统。
- 与GFS类似,HDFS采用多副本(默认为3个副本)数据冗余存储机制,并提供了有效的数据出错检测和数据恢复机制,大大提高了数据存储的可靠性。
6.1.3. 分布式数据库管理系统HBase(重点)
- 为了克服HDFS难以管理结构化/半结构化海量数据的缺点,Hadoop提供了一个大规模分布式数据库管理和查询系统HBase。
- HBase是一个建立在HDFS之上的分布式数据库,它是一个分布式可扩展的NoSQL数据库,提供了对结构化、半结构化甚至非结构化大数据的实时读写和随机访问能力。
- HBase提供了一个基于行、列和时间戳的三维数据管理模型,HBase中每张表的记录数(行数)可以多达几十亿条甚至更多,每条记录可以拥有多达上百万的字段。
- 一个数据库
- 分布式的、非结构化的,稀疏的,面向列的
- 基于HDFS,山寨版的BigTable,继承了可靠性、高性能、可伸缩性
6.1.4. 公共服务模块Common
- Common是一套为整个Hadoop系统提供底层支撑服务和常用工具的类库和API编程接口,这些底层服务包括Hadoop抽象文件系统FileSystem、远程过程调用RPC、系统配置工具Configuration以及序列化机制。
- 在0.20及以前的版本中,Common包含HDFS、MapReduce和其他公共的项目内容;从0.21版本开始,HDFS和MapReduce被分离为独立的子项目,其余部分内容构成Hadoop Common。
6.1.5. 数据序列化系统Avro
- Avro是一个数据序列化系统,用于将数据结构或数据对象转换成便于数据存储和网络传输的格式。
- Avro提供了丰富的数据结构类型,快速可压缩的二进制数据格式,存储持久性数据的文件集,远程调用RPC和简单动态语言集成等功能。
6.1.6. 分布式协调服务框架Zookeeper
- Zookeeper是一个分布式协调服务框架,主要用于解决分布式环境中的一致性问题。
- Zookeeper主要用于提供分布式应用中经常需要的系统可靠性维护、数据状态同步、统一命名服务、分布式应用配置项管理等功能。
- Zookeeper可用来在分布式环境下维护系统运行管理中的一些数据量不大的重要状态数据,并提供监测数据状态变化的机制,以此配合其他Hadoop子系统(如HBase、Hama等)或者用户开发的应用系统,解决分布式环境下系统可靠性管理和数据状态维护等问题。
6.1.7. 分布式数据仓库处理工具Hive(重点)
- Hive是一个建立在Hadoop之上的数据仓库,用于管理存储于HDFS或HBase中的结构化/半结构化数据。
- 它最早由Facebook开发并用于处理并分析大量的用户及日志数据,2008年Facebook将其贡献给Apache成为Hadoop开源项目。
- 为了便于熟悉SQL的传统数据库使用者使用Hadoop系统进行数据查询分析,Hive允许直接用类似SQL的HiveQL查询语言作为编程接口编写数据查询分析程序,并提供数据仓库所需要的数据抽取转换、存储管理和查询分析功能,而HiveQL语句在底层实现时被转换为相应的MapReduce程序加以执行。
- 面向列存储,延迟比较高
- Hive是基于Hadoop的数据仓库工具
- 学习成本低
- 提供完整的sql查询功能
- 可以将结构化的数据文件映射为一张数据库表
- 可以将sql语句转换为MapReduce任务进行运行。
- 可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用
6.1.8. 数据流处理工具Pig
- Pig是一个用来处理大规模数据集的平台,由Yahoo!贡献给Apache成为开源项目。
- 它简化了使用Hadoop进行数据分析处理的难度,提供一个面向领域的高层抽象语言Pig Latin,通过该语言,程序员可以将复杂的数据分析任务实现为Pig操作上的数据流脚本,这些脚本最终执行时将被系统自动转换为MapReduce任务链,在Hadoop上加以执行。Yahoo!有大量的MapReduce作业是通过Pig实现的。
6.1.9. 键值对数据库系统Cassandra
- Cassandra是一套分布式的K-V型的数据库系统,最初由Facebook开发,用于存储邮箱等比较简单的格式化数据,后Facebook将Cassandra贡献出来成为Hadoop开源项目。
- Cassandra以Amazon专有的完全分布式Dynamo为基础,结合了Google BigTable基于列族(Column Family)的数据模型,提供了一套高度可扩展、最终一致、分布式的结构化键值存储系统。
- 它结合了Dynamo的分布技术和Google的Bigtable数据模型,更好地满足了海量数据存储的需求
- 。同时,Cassandra变更垂直扩展为水平扩展,相比其他典型的键值数据存储模型,Cassandra提供了更为丰富的功能。
6.1.10. 日志数据处理系统Chukwa
- Chukwa是一个由Yahoo!贡献的开源的数据收集系统,主要用于日志的收集和数据的监控,并与MapReduce协同处理数据。
- Chukwa是一个基于Hadoop的大规模集群监控系统,继承了Hadoop系统的可靠性,具有良好的适应性和扩展性。
- 它使用HDFS来存储数据,使用MapReduce来处理数据,同时还提供灵活强大的辅助工具用以分析、显示、监视数据结果。
6.1.11. 科学计算基础工具库Hama
- Hama是一个基于BSP并行计算模型(Bulk Synchronous Parallel,大同步并行模型)的计算框架,主要提供一套支撑框架和工具,支持大规模科学计算或者具有复杂数据关联性的图计算。
- Hama类似Google公司开发的Pregel,Google利用Pregel来实现图遍历(BFS)、最短路径(SSSP)、PageRank等计算。
- Hama可以与Hadoop的HDSF进行完美的整合,利用HDFS对需要运行的任务和数据进行持久化存储。
- 由于BSP在并行化计算模型上的灵活性,Hama框架可在大规模科学计算和图计算方面得到较多应用,完成矩阵计算、排序计算、PageRank、BFS等不同的大数据计算和处理任务。
6.1.12. 数据分析挖掘工具库Mahout
- Mahout来源于Apache Lucene子项目,其主要目标是创建并提供经典的机器学习和数据挖掘并行化算法类库,以便减轻需要使用这些算法进行数据分析挖掘的程序员的编程负担,不需要自己再去实现这些算法。
- Mahout现在已经包含了聚类、分类、推荐引擎、频繁项集挖掘等广泛使用的机器学习和数据挖掘算法。
- 此外,它还提供了包含数据输入输出工具,以及与其他数据存储管理系统进行数据集成的工具和构架。
6.1.13. 关系数据交换工具Sqoop
- Sqoop是SQL-to-Hadoop的缩写,是一个在关系数据库与Hadoop平台间进行快速批量数据交换的工具。
- 它可以将一个关系数据库中的数据批量导入Hadoop的HDFS、HBase、Hive中,也可以反过来将Hadoop平台中的数据导入关系数据库中。
- Sqoop充分利用了Hadoop MapReduce的并行化优点,整个数据交换过程基于MapReduce实现并行化的快速处理。
6.1.14. 日志数据收集工具Flume
- Flume是由Cloudera开发维护的一个分布式、高可靠、高可用、适合复杂环境下大规模日志数据采集的系统。
- 它将数据从产生、传输、处理、输出的过程抽象为数据流,并允许在数据源中定义数据发送方,从而支持收集基于各种不同传输协议的数据,并提供对日志数据进行简单的数据过滤、格式转换等处理能力。输出时,Flume可支持将日志数据写往用户定制的输出目标。
6.2. 三种模式的Hadoop
- 独立式
- 伪分布式
- 全分布式
6.3. HDFS架构
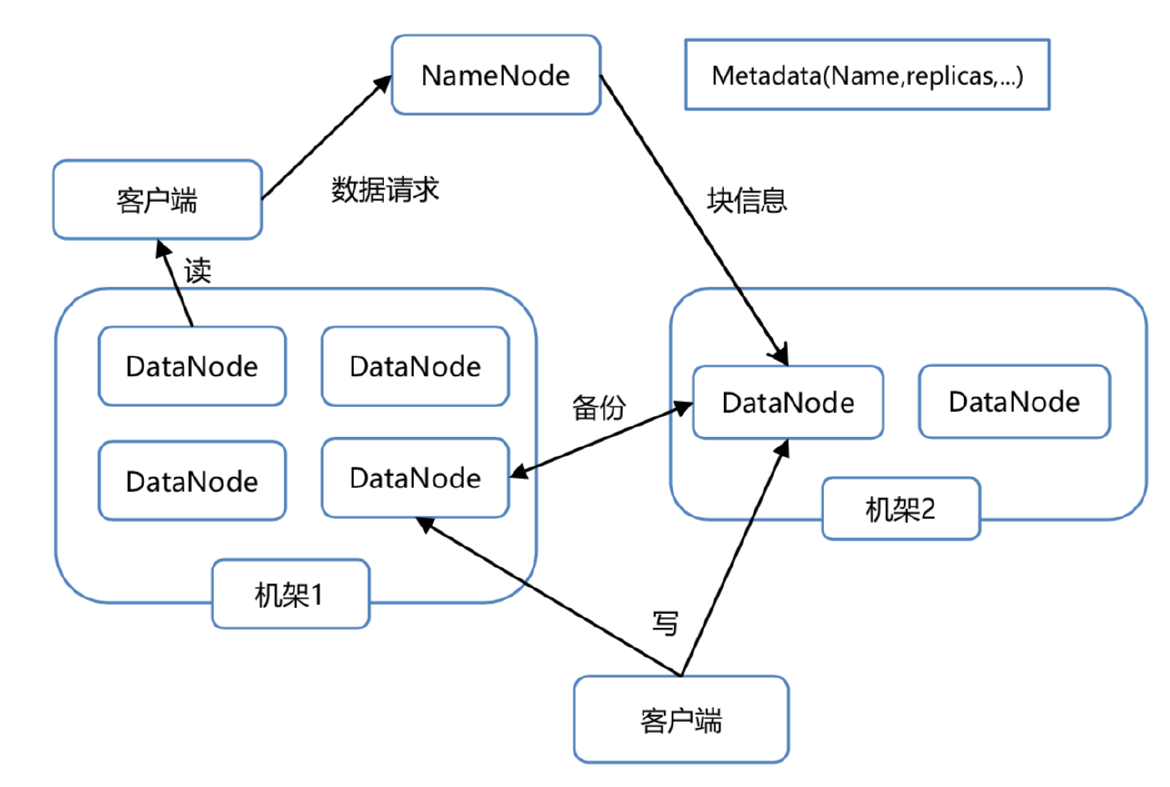
6.3.1. NameNode
- 可以看做是分布式文件系统中的管理者,存储文件系统的metadata,主要负责管理文件系统的命名空间,集群配置信息,存储块的赋值
- 两个文件:EditLog、FSImage
- 两个映射:
Filename -> BlockSequence(FsImage)、Block -> DatanodeList(BlockReport) - 单点(NameNode)风险
6.3.2. Secondary NameNode
- 不是备用NameNode,而是秘书
- 合并和保存EditLog、FSImage
- Checkpoint.period
- Checkpoint.size
6.3.3. Datanode
- 文件存储的基本单位。它存储文件块在本地文件系统中,保存了文件块的meta-data,同时周期性的发送所有存在的文件块的报错给namenode
6.3.4. Client(客户端)
- 客户端:对外接口,从namenode获取文件信息,然后访问datanode
7. PageRank:问题
- dead ends
- Spider traps
8. SVD:定义
计算一两步骤,问中间结果

9. 贝叶斯
- 假设某种疾病的发病率为0.001(1000个⼈中会有⼀个⼈得病),现有⼀种试剂在患者确实得病的情况下,有99%的⼏率呈现为阳性,⽽在患者没有得病的情况下,它有5%的⼏率呈现为阳性(也就是假阳性),如有⼀位病⼈的检验成果为阳性,那么他的得病概率是多少呢?
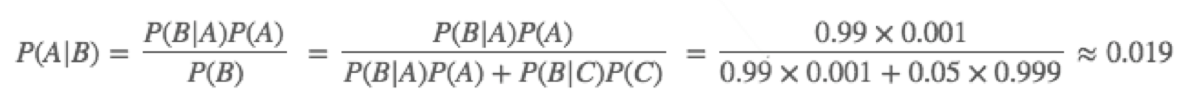
10. 决策树算法(TODO)
10.1. ID3
- 使用所有没有使用的属性并计算与之相关的样本熵值
- 选取其中熵值最小的属性
- 生成包含该属性的节点
- Information Gain
- 序号是最方便的最大连接
10.2. C4.5
- C4.5算法是对ID3算法的改进,C4.5克服了ID3的2个缺点:
- 用信息增益选择属性时偏向于选择分枝比较多的属性值,即取值多的属性
- 不能处理连续属性
- Information resheld
11. KNN算法(分类)
- 计算已知类别数据集中点与当前点之间的距离
- 按照距离增次序排序
- 选取与当前点距离最小的k个点
- 统计前k个点所在的类别出现的频率
- 返回前k个点出现频率最高的类别作为当前点的预测分类
- 投票法:可以选择K个点出现频率最高的类别作为预测结果
- 平均法:可以计算K个点的实值输出标记的平均值作为预测结果
- 加权平均法:根据距离远近完成加权平均等方法
11.1. 优点
- 简单有效
- 重新训练代价低
- 算法复杂度低
- 适合类域交叉样本
- 适用大样本自动分类
11.2. 缺点
- 惰性学习
- 类别分类不标准化
- 输出可解释性不强
- 不均衡性
- 计算量较大
12. 聚类问题
12.1. 硬聚类和软聚类
- 硬聚类:每个文档完全属于一个聚类:更常见,更容易做到
- 软集群:一个文档可以属于多个集群。
- 对于创建可浏览层次结构的应用程序更有意义
- 您可能希望将一双运动鞋分为两类:(i)运动服装和(ii)鞋子
- 您只能使用软集群方法来做到这一点。
12.2. K-Means
- 假设是欧几里得空间/距离,K-mean算法过程
- 首先确定k(簇数)
- 随机选择k个点作为k个聚类的中心来初始化聚类,保证每一点都与其他的点尽可能的远
- 填充每个聚类
- 对于每个点,将其放置在当前centroid最近的聚类中
- 分配所有点后,更新k个聚类的centroid的位置
- 将所有点重新分配到它们最近的centroid:有时在群集之间移动点
- 重复2和3直到收敛,收敛被定义为点在簇之间不移动,centroid稳定
- 终止条件:(有很多的候选条件)
- 一个固定数量的循环次数
- 文档向量分簇不变
- centroid的位置不变
12.2.1. 优点
- 相对有效:O(tkn),其中n是对象,k是聚类,t是迭代。 通常,k,t<<n。
- 通常以局部最优值终止。 可以使用诸如模拟退火和遗传算法之类的技术找到全局最优值
12.2.2. 弱点
- 仅在定义均值时适用
- 需要预先指定k,即簇数
- 嘈杂的数据和异常值的问题
- 不适合发现具有非凸形状的聚类
12.3. 层次方法聚类
- 使用距离矩阵作为聚类标准。此方法不需要输入簇数k,但是需要终止条件
- 两个方向:
- 聚合的
- 划分的

- 计算两个类簇的距离

- 关键操作:重复合并最近的两个簇
- 三个重要问题:
- 您如何表示一个多点的集群?
- 您如何确定群集的"附近"?
- 什么时候停止组合集群?
- 簇的最近对
- 定义最接近的集群对的许多变体
- 单链接:最相似的余弦相似度(单链接)
- 完整链接:"最远"点的相似度,最小余弦相似度
- 质心(centorid):质心最接近余弦的聚类,真实存在?中心可能不是实际点
- 平均链接:元素对之间的平均余弦
- 欧式空间与非欧式空间
- 划分聚类复杂度:,使用优先级队列:
- 聚合聚类复杂度至少为
- 还有BIRCH、CURE
12.4. 聚类方法
- 基于参数:比如两个簇之间的最大距离
- 基于平均距离:欧式空间内
- 基于密度:密度可达、密度连接
13. 启发式算法
- 仿动物类的算法:
- 粒子群优化
- 蚂蚁优化
- 鱼群算法
- 蜂群算法等
- 仿植物类的算法:
- 向光性算法
- 杂草优化算法
- 仿人类的算法:和声搜索算法
14. 推荐
14.1. 基于内容的推荐
- 主要思想:向客户推荐商品x与x之前评价较高的商品相似
- 例子:电影、网站、新闻
14.1.1. 优点
- 不需要其他用户的数据:没有冷启动或稀疏性问题
- 可以向口味独特的用户推荐
- 可以推荐不受欢迎的新商品:没有评分少的问题
- 能够提供解释:可以通过以下方式提供推荐项目的说明
14.1.2. 缺点
- 很难找到合适的功能,例如图像,电影,音乐
- 对新用户的建议如何建立用户档案?
- 过度专业化
- 绝不推荐用户内容档案之外的项目
- 人们可能有多种兴趣
- 无法利用其他用户的质量判断
14.2. 协同过滤
- 找到你的朋友圈,然后推荐给你
- 基于物品-物品、用户-用户
14.2.1. 优点
- 适用于所有类型的项,不需要选择特性。
14.2.2. 缺点
- 冷启动:系统中需要足够的用户才能找到匹配项
- 稀疏度:
- 用户/评分矩阵稀疏
- 很难找到评分相同的用户
- 第一个评分问题:
- 无法推荐以前未评级的项目
- 新项目,神秘项目
- 人气偏见:
- 无法向有独特品味的人推荐产品
- 倾向于推荐热门商品
14.3. 推荐系统评估

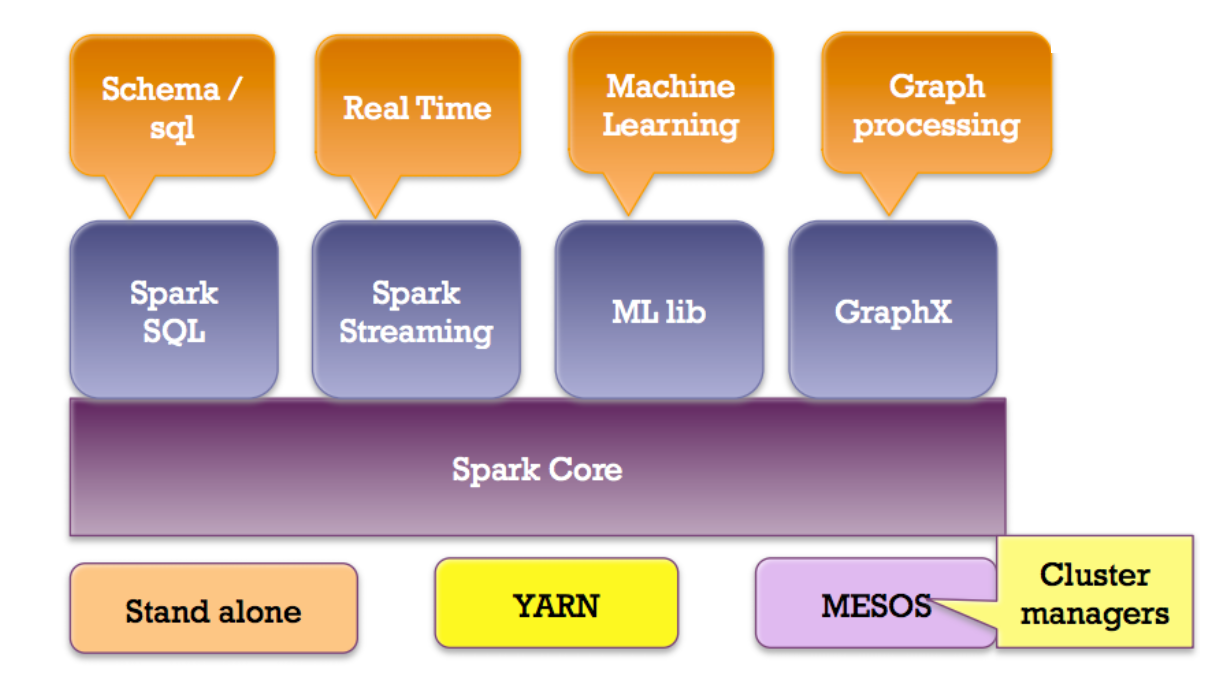
15. 为什么选择Spark?
- 快:基于内存的MapReduce计算比Hadoop快100x倍,基于硬盘的则快10x倍
- 易用:支持Scala、Java、Python和R语言开发
- 功能强:Spark SQL、Spark Streaming、Spark GraphX、Spark MLlib
15.1. Spark生态系统
- Spark Streaming处理一些实时数据
15.2. 功能

15.3. 集群管理框架

15.4. Spark Streaming

16. NoSQL的几种类型
- 图形存储用于存储有关数据网络的信息,例如社交关系。Graph商店包括Neo4J和Fuseki等三重商店。
- 文档数据库将每个密钥与称为文档的复杂数据结构配对。
- 键值存储是最简单的NoSQL数据库。 数据库中的每一项都存储为属性名称(或"键")及其值。 键值存储的示例有Riak和Berkeley DB。
- 宽列存储(Cassandra和HBase)针对在大型数据集上进行查询进行了优化,并将数据列而不是行存储在一起。
16.1. neo4j
- Neo4j是由Neo Technologies开发的最受欢迎的图形数据库,其是用Java实现的开源,面向图的数据库
- 以Java实施,可通过交换HTTP端点使用Cypher查询语言从其他语言编写的软件中访问。
- 符合ACID的事务数据库,具有本机图存储和处理功能。
- 一切都存储为边,节点或属性。
- 每个节点和边缘可以具有任意数量的属性。
- 节点和边均可标记。
- 标签可用于缩小搜索范围
16.2. cypher
- Neo4j的查询语言
- 易于根据关系制定查询
- 许多功能源于使用SQL改善痛点,例如连接表
17. 社会计算
17.1. 社会媒体的特点
- 每个人都可以成为媒体
- 通讯障碍消失
- 丰富的用户互动
- 用户生成的内容
- 用户丰富的内容
- 用户开发的小部件
- 协作环境
- 集体智慧
- 长尾模式
- 广播媒体(过滤,然后发布) -> 社交媒体(发布,然后过滤)
17.2. 社交网络
- 由节点(个人或组织)组成的社会结构,这些节点通过各种相互依存关系(如友谊,亲属关系等)相互关联。
- 图示
- 节点:成员
- 优势:关系
- 各种实现
- 社交书签(Del.icio.us)
- 友谊网络(facebook,myspace)
- Blogosphere
- 媒体共享(Flickr,Youtube)
- 民间传说
17.3. 社交计算和数据挖掘
- 社会计算涉及基于计算系统的社会行为和社会环境的研究。
- 数据挖掘相关任务
- 集中度分析(中心和重点发现)
- 社团检测
- 分类
- 关联预测
- 病毒式营销
- 网络建模
- 注意每一个任务的关注点
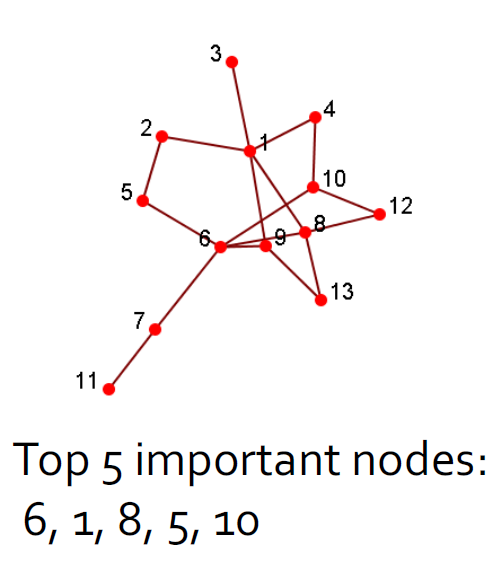
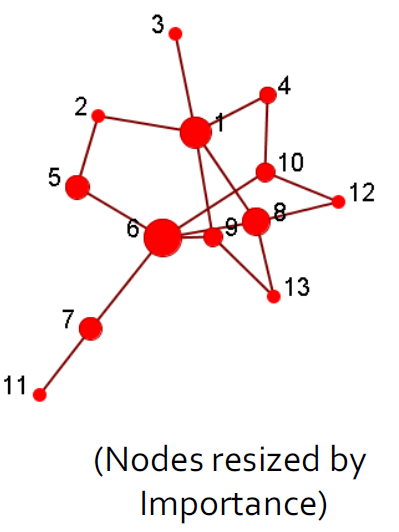
17.3.1. 集中性分析/影响力研究
- 识别社交网络中最重要的参与者
- 给出:一个社交网络
- 输出:顶级节点列表
- 计算出来任意两个节点之间的最近路径,然后计算出每一个节点相对于其他节点的是不是最近节点,得到中心度。
- 或者还可以使用1跳或者xxx来作为判断标准
 |
 |
|---|
17.3.2. 社团检测(聚类)
- 社团是一组节点,它们之间的交互(相对)频繁(也称为组,子组,模块,集群)
- 社团检测又称分组,聚类,寻找有凝聚力的亚组(社团),有点类似于聚类任务。
- 给出:一个社交网络
- 产出:(一些)演员的社团成员
- 应用
- 了解人与人之间的互动
- 可视化和导航大型网络
- 为其他任务(例如数据挖掘)奠定基础
- 分组后可视化结果
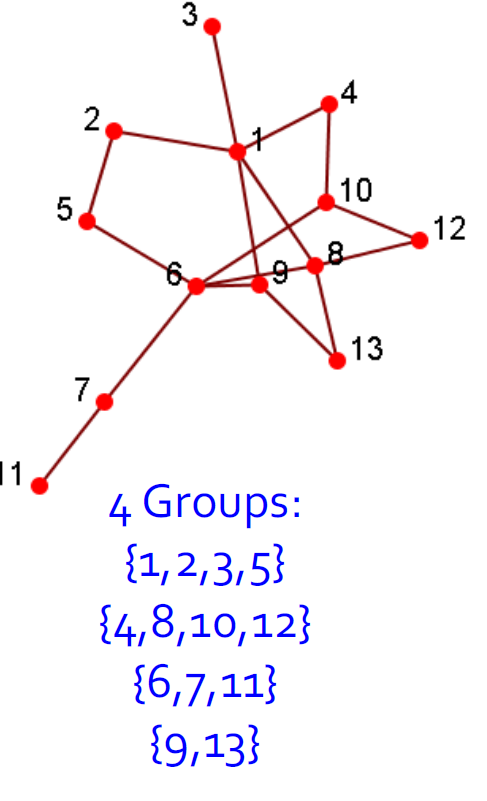 |
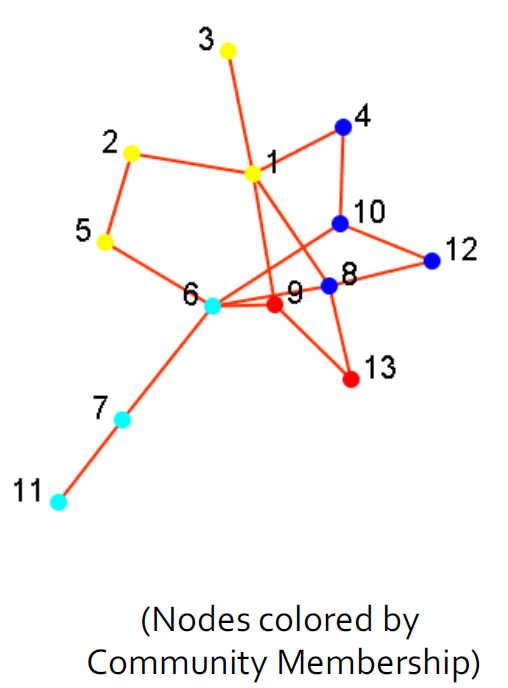 |
|---|
17.3.3. 分类
- 用户首选项或行为可以表示为类标签
- 是否点击广告
- 是否对某些主题感兴趣
- 订阅了某些政治观点
- 喜欢/不喜欢产品
- 输入
- 社交网络
- 网络中一些参与者的标签
- 输出:网络中剩余参与者的标签
- 总结:分类预测后可视化
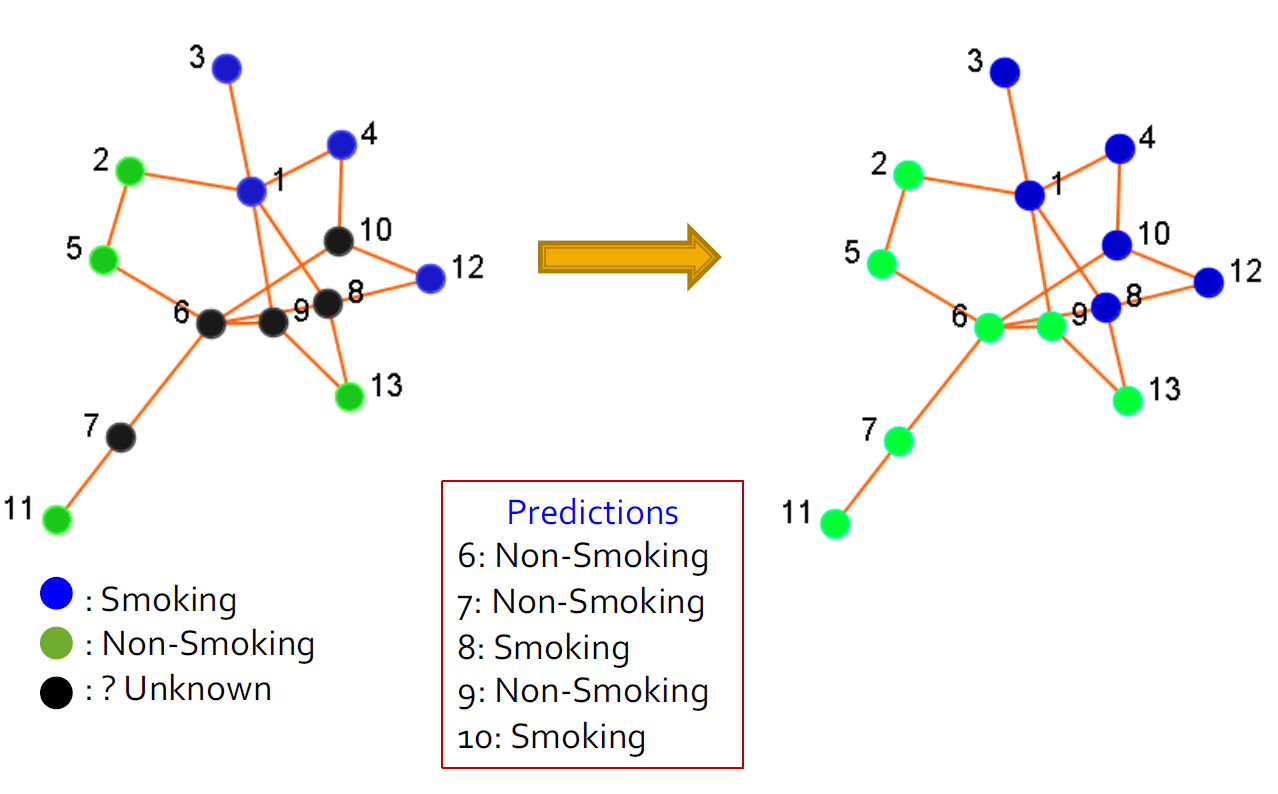
17.3.4. 关联预测
- 给定一个社交网络,预测哪些节点可能会连接
- 输出(排名)节点对的列表
- 示例:Facebook中的朋友推荐
17.3.5. 病毒式营销/爆发检测
17.3.5.1. 什么是病毒式营销/爆发检测
- 用户在社交网络中具有不同的社交资本(或网络价值),因此,人们如何才能最好地利用这一信息?
- 病毒式营销:找出一组用户来提供优惠券和促销以影响网络中的其他人,从而使我的利益最大化
- 爆发检测:监控一组节点,这些节点可帮助检测爆发或中断感染传播(例如H1N1流感)
- 目标:在预算有限的情况下,如何最大程度地提高整体收益?
17.3.5.2. 病毒式营销的例子
- 查找节点数量最少的整个节点网络的覆盖范围
- 如何实现它,一个例子:基本贪婪选择:选择使实用程序最大化的节点,删除该节点,然后重复
- 首先选择节点1
- 然后选择节点8
- 最后选择节点7,节点7不是一个有高中心度的结点。
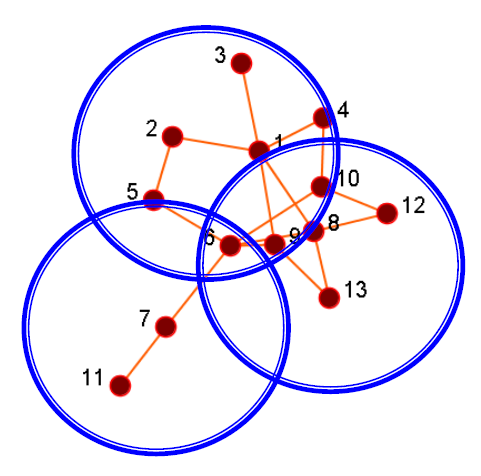
17.3.6. 网络建模
- 大型网络展示了统计模式:
- 小世界效果(例如6度的分离度)
- 幂律分布(又称无标度分布)
- 社团结构(高聚集系数)
- 模拟网络动力学
- 找到一种机制,以便可以复制在大型网络中观察到的统计模式。
- 示例:随机图,优先附着过程
- 用于仿真以了解网络属性
- Thomas Shelling的著名模拟:是什么导致白人和黑人隔离
- 受攻击的网络稳健性
- 二八现象:20%的节点上有着80%的重要性
- 网络模型应用
17.4. 社交计算的应用
- 通过社交网络做广告
- 行为建模和预测
- 流行病学研究
- 协同过滤
- 人群情绪阅读器
- 文化趋势监测
- 可视化
- 健康2.0
17.5. 社团探测原则
17.5.1. 社团
- 社团:具有相对牢固,直接,强烈,频繁或积极联系的演员的子集。
- 社团是一组经常相互交流的参与者,例如:参加会议的人
- 一群没有互动的人不是一个社团,例如:人们在车站等公共汽车,却不互相交谈
- 人们在社交媒体中形成社团
17.5.2. 为什么在社交媒体上有社团
- 人是社会的
- 社交媒体中的部分互动是对现实世界的一瞥
- 人们在现实世界以及在线中都与朋友,亲戚和同事保持联系
- 易于使用的社交媒体使人们能够以前所未有的方式扩展社交生活,很难认识现实世界中的朋友,但更容易在网上找到志趣相投的朋友
17.5.3. 社团探测
- 社团检测:根据社交网络属性正式确定强大的社交群体
- 一些社交媒体网站允许人们加入群组,是否有必要根据网络拓扑提取群组?
- 并非所有站点都提供社团平台
- 并非所有人都参加
- 网络交互可提供有关用户之间关系的丰富信息
- 组是隐式形成的
- 可以补充其他类型的信息
- 帮助网络可视化和导航
- 提供其他任务的基本信息
- 社团定义的主观性
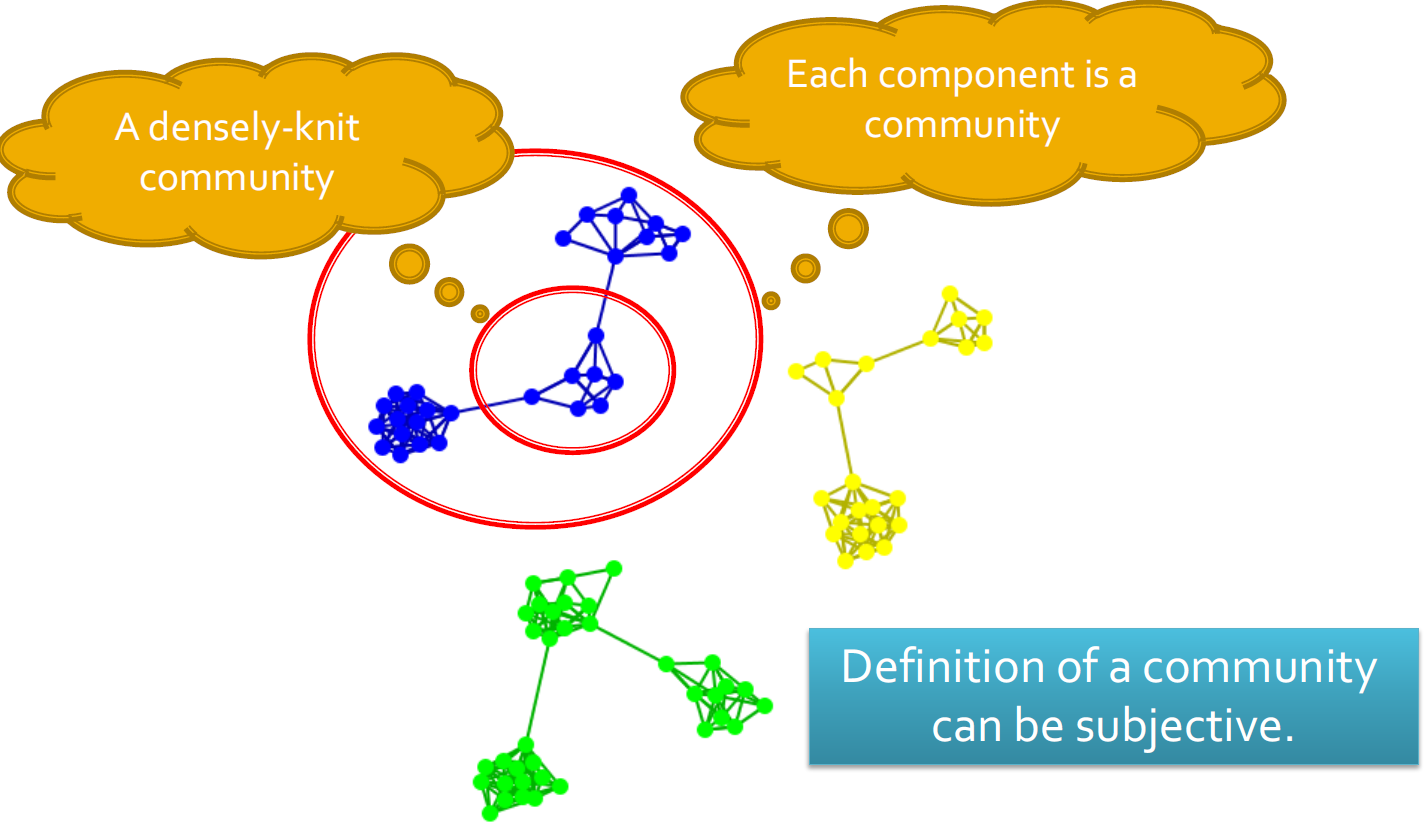
17.5.4. 社团标准分类
- 条件因任务而异
- 大致上,社团检测方法可分为4类(非排他性):
- 以节点为中心的社团:组中的每个节点都满足某些属性
- 以团体为中心的社团:考虑整个组内的连接。 该组必须满足某些属性,而无需放大节点级别
- 以网络为中心的社团:将整个网络分成几个不相交的集合
- 以等级为中心的社团:构建社团的层次结构
18. 参考与更多
2020-大数据分析-Exam-整理
https://spricoder.github.io/2020/11/01/2020-Big-data-analysis/2020-Big-data-analysis-Exam-%E6%95%B4%E7%90%86/