1 2 3 4 5 6 7 8 9 10 class Empty {}; class Empty {Empty ();Empty (const Empty&);Empty ();operator =(const Empty&);operator &();const Empty* operator &() const ;
通过将一些需要的信息进行封装的方法,来保证不管出现什么异常,在退出相应操作部分时,自动调用对象的析构函数来保证不会出现内存泄漏的问题。
同样的还有句柄类(C++ 异常中有)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 template <class T >class auto_ptr {public :auto_ptr (T *p=0 ):ptr (p) {}auto_ptr () { delete ptr; }operator ->() const { return ptr;}operator *() const { return *ptr; }private :void processAdoptions (istream& dataSource) while (dataSource){auto_ptr<ALA> pa (readALA(dataSource)) ;processAdoption ();
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void memset (void *pointer, unsigned size) char *p = (char *)pointer;for (int k=0 ;k<size;k++){0 ;void memcpy (void *des, void *src, unsigned size) char *sp = (char *)src;char *dp = (char *)des;for (int i = 0 ; i < size; i++) {void showBytes (void *q, int n) unsigned char *p = (unsigned char *)q;for (int i=0 ; i<n; i++){void *)(p+i) << " : " << setw (2 ) << hex << (int )*(p+i) << " " ;if ( (i+1 ) %4 ==0 ) cout << endl;
函数指针可以使得我们类似传递参数一样传递函数指针。
函数指针允许我们抽象一些操作,同时支持我们实现多态操作。
1 2 3 4 5 6 7 8 9 10 typedef double (*FP) (int ) double *fp (int ) double f (int x) void main () 10 );
语法:[capture](parameters) mutable ->return-type{statement}
capture:捕获列表
parameters:参数列表
->mutable:修饰符,可以取消lambda函数使其不是const函数,使用时参数列表不可省略(就算为空)
return type:返回类型
statement:函数体,可以使用参数和捕获变量
例子:auto func = [=, &b](int c)->int {return b += a + c;};
int *p = a,a代表数组的首地址。*(p+i):p的位置不移动。*(p++):p向前移动一个位置。sizeof(a):数组的大小。sizeof(a[0]):数组的元素的占地大小。几个等价操作:
a[i] == *(a+i)&a[i] == a+i
1 2 3 4 5 6 7 8 9 10 11 12 13 int a[10 ] = { 1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ,10 };int *p = &a[0 ];for (int i = 0 ; i < 10 ; i++) {" " ;" " ;for (int j = 0 ; j < 10 ; j++) {" " ;
上面代码的结果如下,上图中为什么等价,是因为的优先级高于*,C 的优先级和结合性
有一些操作相对于其组成部分(一维数组越界了,但是对于其本身没有越界),也就是C++对于这一类越界是默许的,因为这块系统空间在我们的控制中。
int *p = &a[0][0]:访问二维数组中的T类型的变量
1 2 3 4 5 6 int b[20 ][10 ];int *q;0 ][0 ];0 ];
使用线性方式来访问二维数组
对于一维数组,建立逻辑视图,按照多维数组的方式进行访问,可以在传递参数的时候直接进行划分。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 void show (int a[], int n) for (int i=0 ;i<n;i++) {" " ;void show (int a[][2 ], int n) for (int i=0 ;i<n;i++) for (int j=0 ;j<2 ;j++) {" " ;" :" << a[i][j] << " " ;if ((i*2 +j+1 )%4 == 0 )void show (int a[][2 ][3 ], int n) for (int i=0 ;i<n;i++) for (int j=0 ;j<2 ;j++)for (int k=0 ;k<3 ;k++){" " ;" :" << a[i][j][k] << " " ;if ((i*6 +j*3 +k+1 )%4 == 0 )void main () int b[12 ];for (int i=0 ;i<12 ;i++) b[i] = i+1 ;show (b,12 );typedef int T[2 ];show ((T*)b,6 );typedef int T1[3 ];typedef T1 T2[2 ];show ((T2*)b,2 );
结果如下图
main函数:int main(int argc,char * argv[],char * env[])
argc:参数个数(包含命令)
argv:命令行参数
env:环境参数(为什么这个不必指出长度?因为\0结束,一个结束符)
可变参数(详见C++指针与引用):主要是利用内存机制,实现print函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void MyPrint (char *s, ...) va_start (marker,s);int i=0 ;char c;while ((c=s[i]) != '\0' ){if (c != '%' )else {switch (c=s[i]){case 'f' : cout << va_arg (marker,double ); break ;case 'd' : cout << va_arg (marker,int );break ;case 'c' : cout << va_arg (marker,char );break ;va_end (marker);void main () MyPrint ("double: %f integer: %d string: %c " ,1.1 , 100 , 'A' );
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 void myswap (int *p1, int *p2) int * tmp = p1;void myswap2 (int &p1, int & p2) int tmp = p1;void myswap (char **p1, char **p2) char *tmp = *p1;void main () char *p1 =(char *) "abcd" ;char *p2 =(char *) "1234" ;int a = 100 ;int b = 200 ;myswap (&a, &b);" " << b << endl;myswap2 (a, b);" " << b << endl;myswap (&p1, &p2);" " << p2 << endl;
程序员在Heap上主动申请空间进行存储。
申请动态变量:申请的过程可能会失败
new:new <类型名> [<整型表达式>]。首先分配对应大小的内存,然后调用构造函数进行初始化,最后再赋值给对应的值。
malloc:int *p = (int *)malloc(sizeof(int));,不推荐,只是分配了空间,但是并不会调用构造函数。
为什么引入new和delete?因为新的操作符可以解决初始化函数的析构函数的调用的问题
分配连续空间:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int *p = new int [10 ];int *p = (int *)malloc (sizeof (int )*10 )int (*p2)[5 ] = (int (*)[5 ])p;new int [2 ][5 ];const int ROWS = 3 ;const int COLUMNS = 4 ;char **chArray2;new char * [ROWS];for (int row = 0 ; row < ROWS; row++ )new char [ COLUMNS ];
int *p1 = new int[5]; 默认不进行初始化int *p2 = new int[5]();进行默认初始化int *p2 = new int[5]{0,1,2,3,4}:进行显式对应函数初始化
释放动态变量:
new - delete | delete[]:使用new的方式创建的动态变量,通过delete的方式释放
delete a:释放数组的第一个元素delete[] a:释放数组中的所有的元素,注意此时归还是从a开始向下归还size大小的空间,所以a必须是数组的首地址才行。delete会调用变量的析构函数,注意删除原对象之后要将对应的指针置为NULL,避免悬挂指针
malloc free:只是释放对应的申请的空间,但不会调用析构函数归还操作前,注意要拷贝一个指针值,不然无法找到归还开始的头部地址。
单链表和双链表要求掌握
注意指针的移动情况
定义:为一块已有的内存空间取一个别名,定义引用变量的时候必须同时声明
可以通过函数副作用,来使得返回值也可以是引用和函数指针。
1 2 3 4 int &a = *p;void f (int &a)
可以使用const修饰引用,避免造成不必要的修改
C++是强类型语言、动/静结合、类型安全不能代替测试。
弱类型允许隐式转换
动:编译时决定类型,静:编译前决定类型。
注解:对于char、int、float、double(四种基本数据类型)和修饰符(long、short、signed、unsigned):
char只可以被signed和unsigned修饰
float不能被修饰
double只能用long修饰
int可以被四种修饰符组合修饰
sizeof:返回字节为单位的对应单位的大小。
typedef:可以有效地提高系统的可移植性。
枚举常量:直接输出枚举常量,会在屏幕上显示对应的值,而不是枚举的名称,不能直接给枚举类赋一个int值,可以today = weekday(4),其中weekday是预定义好的枚举类。
this关键字:可以用来访问自己的地址。
static:
全局有效:函数释放后也不会释放自身空间。
static的成员函数,需要在声明的时候进行修饰,但是没有this指针
const对象在对应声明周期中是常量
自增量运算符
1 2 3 4 5 6 7 8 9 10 11 12 13 int main () int a = 1 ;int b, c, d, e;
条件运算符:<exp1>?<exp2>:<exp3>
唯一的三目运算符,不允许进行重载
如果<exp2>和<exp3>的值类型相同且均为左值,则该条件运算符表达式为左值表达式。
可以嵌套(满足就近原则)
逗号表达式:按照顺序,连续进行运算,格式形如:<exp1>,<exp2>,...,<expn>,<expn>的值是逗号表达式的值,如<exp n>为左值,则该逗号表达式为左值
1 2 3 4 5 int a,b,c;1 ,b = a + 2 ,c = b + 3 )
异或操作
与全0的二进制串进行运算:不变
与全1的二进制串进行运算:取反
与本身的运算:清零
与同一个对象进行异或运算两次:还原,应用:进行加密
交换x和y
1 2 3 4 5 6 7 8 9 10 11 12 int t = x;
左值表达式和右值表达式
左值表达式:++i
右值表达式:i++
目的:更告诉地进行编码
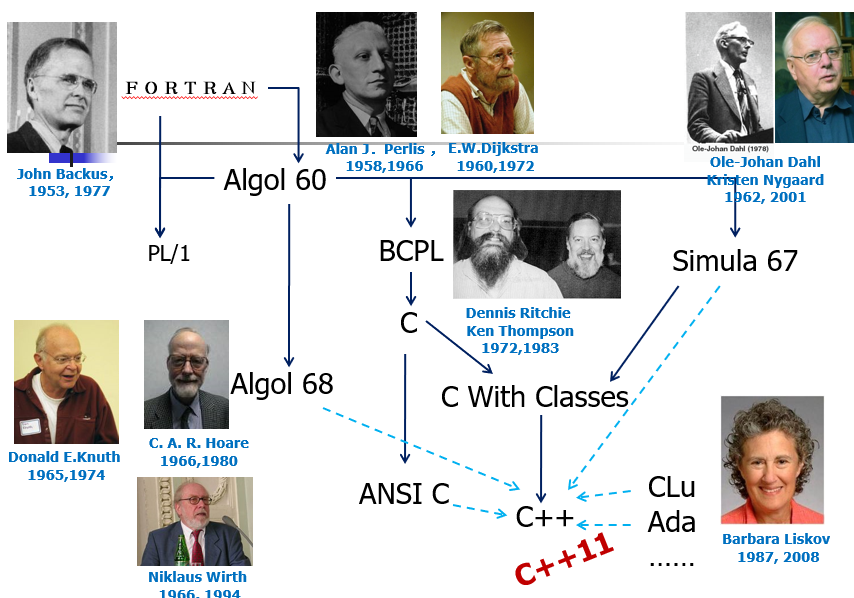
John Backus:发明了FORTRAN,使得编程更贴近于问题本身
Dijkstra:发明了编译器,著名观点:goto是有害的,不能随意跳转
Algol 60:其中阐述了很多的一些观点
脉络一:Algol 68:结构化编程的部分的继承
Niklaus Wirth:发明了PASCAL,很实用于教学
C. A. R. Hoare
Donald E.Knuth:和 Dijkstra一同提出goto有害性
继承下来:关于结构化编程的特性
脉络二:系统化编程的继承
BCPL:贴近计算机,写出高效的程序,很好的想法:将IO作为类成分而不是语言成分,以提高语言可移植性
在BCPL和C之间还有B语言,B语言是将BCPL里面的比较繁杂的部分取出。
C:Dennis Ritchie、Ken Thompson,compiler决定程序语义和性质
继承下来:关于系统编程的特性
脉络三:Simula 67 第一个OO的研究(OO部分的继承)
OO的第一个提出人:Ole-Johan Dahl、Kristen Nygaard
继承下来:关于面向对象编程的特性
Barbara Liskov:关于高层复用做出很大的贡献
C++为什么不叫D:因为并没有完全抛弃C中的很多东西,粗略说法
C++的编译过程:
C++源代码想通过cpp预处理后再通过Cfront翻译成C语言,最后通过C编译器来使程序运行。
用Cfront不用Cpre的原因:Cpre不懂C语法,Cfront懂,发现语法错误会传回source code,但Cpre将方言部分翻译成c后交给cc,此时若发现错误才传回source code
名词
全称
功能
备注
cpre
-
将C++扩展内容翻译成为c
是C With Class中的含有的
cfront
-
将c++翻译成为c,可以直接检查语法错误,而不必经过cc
编译简单分成前端后端,前端负责语法检查,后端负责代码生成和优化,cc负责后端
cc
c compiler
c编译器,负责进行语法检查,有问题返回Source code
-
cpp
c pre process
-
-
对象类型的判断:
运行时判断
编译时判断
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int i;if (typeid (i) == typeid (int ) )"i is int" << endl;template <class T>void func (T t ) "i is not int" << endl ;template <> void func <int >(int i){"i is int" << endl ;int i;func (i)
栈空间:局部变量、值传递参数
堆空间:动态内存分配的位置
友元是数据保护和访问效率的折衷方案,可以访问private和protected的成员
一个全局函数是一个友元函数
1 2 3 4 5 6 7 8 9 class A {int j;friend void func (A a) void func (A a)
友元类:一个类是另一个类的友元
1 2 3 4 5 6 friend class B ;friend B;class A {friend class B ;
在完整的类的声明完成之前是不能够被声明的。
1 2 3 class A {friend void C::f ()
友元函数在之前可以没有声明
友元函数如果之前还没有声明过,则当做已经声明了
但是友元类函数在完整的类声明出现前不能声明友元函数。
为什么友元函数和友元类成员函数的声明要求是不一样的?
数据的一致性:避免对应类里面没有这个函数(也就是C的完整定义必须有)
成员函数依赖于类
友元函数不具有传递性
友元必须显示声明
互为友元的两个类声明时是否需要前置声明
如果A和B不在一个命名空间不能通过编译
如果A和B在一个命名空间的话可以没有前置声明
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 class vector ;class Matrix {friend void multiply (Matrix &m, Vector &v, Vector &r) class Vector {friend void multiply (Matrix &m, Vector &v, Vector &r) class A {int a;public :friend class B ;void show (B &b) class B {int b;public :friend class A ;void show (A &a) void A::show (B &b) class Base {protected :int prot_mem;class Sneaky : public Base {friend void clobber (Sneaky&) friend void clobber (Base&) int j;void clobber (Sneaky &s) 0 ;void clobber (Base &b) 0 ;
函数重载:(静态多态),和虚函数的动态多态不同(一名多用):函数重载包含操作符重载
类属多态:模板:template
函数重载要求名同、参数不同,而返回值的类型不能进行区分。
歧义转换
按照顺序匹配
找到最佳匹配
原则一:这个匹配每一个参数不必其他的匹配更差
原则二:这个匹配有一个参数更精确匹配
重载是为了让事情有效率,而不是过分有效率
自增自减运算符的重载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Counter {int value;public :Counter () { value = 0 ; }operator ++()return *this ;operator ++(int )this ;return temp;
<<的重载:ostream& operator << (ostream& o, Day& d),返回引用保证可以链式调用,如果没有&,那么在第一个return出现了对象拷贝,容易出现临时变量不能返回拷贝的问题
1 2 3 4 5 6 7 8 9 10 11 12 ostream& operator << (ostream& o, Day& d)switch (d)case SUN: o << "SUN" << endl;break ;case MON: o << "MON" << endl;break ;case TUE: o << "TUE" << endl;break ;case WED: o << "WED" << endl;break ;case THU: o << "THU" << endl;break ;case FRI: o << "FRI" << endl;break ;case SAT: o << "SAT" << endl;break ;return o;
=的重载:A& operator = (A& a)不可以被继承,返回引用对象。在=复制的过程中,尽可能地避免出现自我复制的情况(可以在程序入口检查)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class A {int x,y ;char *p ;public :operator = (A& a) {delete []p;new char [strlen (a.p)+1 ];strcpy (p,a.p);return *this ;char *pOrig = p;new char ...strcpy ();delete pOrig;return *this ;if (this == &a)return *this ;
[]操作符的重载:char& operator[](int i)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class string {char *p;public :string (char *p1){new char [strlen (p1)+ 1 ];strcpy (p,p1);char & operator [](int i){return p[i];const char operator [](int i) const {return p[i];virtual ~string () { delete [] p ; }string s ("aacd" ) ;2 ] = 'b' ;const string cs ('const' ) 0 ];const cs[0 ] = 'D' ;
()操作符的重载:
类型转换:operator double()
函数调用:double operator()(double,int,int)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Rational {public : Rational (int n1, int n2) {operator double () return (double )n/d;private :int n, d;class Func {double para;int lowerBound , upperBound ;public :double operator () (double ,int ,int ) f (2.4 , 0 , 8 );
不可以重载的操作符:.(成员访问操作符)、.*(成员指针访问运算符,如下)、::(域操作符)、?:(条件操作符)、sizeof:也不重载
原因:前两个为了防止类访问出现混乱
::后面是名称不是变量
?:条件运算符涉及到跳转,如果重载就影响了理解
不建议重载的操作符号:永远不要重载&&和||会造成极大的问题
友元:friend <ret type> operator #(<arg1>,<arg2>)
格式:<ret type> operator #(<arg1>,<arg2>)
注意:=、()、[]、->不可以作为全局函数重载
单目运算符最好重载为类的成员函数
双目运算符最好重载为类的友元函数
问题:为什么禁止在类外禁止重载赋值操作符?
如果没有类内提供一个赋值操作符,则编译器会默认提供一个类内的复制操作符
查找操作符优先查找类内,之后查找全局,所以全局重载赋值操作符不可能被用到
格式:<ret type>operator #(<arg>)
1 2 3 <class name > a,b;# b; operator #(b)
加法重载:friend Complex operator+(Complex& c1 , Complex& c2);
1 2 3 4 5 6 Complex operator + (Complex& c1 , Complex& c2 ) {return temp;
加减乘除:返回拷贝,不是引用,效率不太高?为了解决这个问题:可以返回值优化,第一个return没有拷贝,直接返回的是一个对象(无拷贝),先计算,最后生成一个对象返回。
->为二元运算符,重载的时候按照一元操作符重载描述。A*operator->()
1 2 3 4 5 6 7 8 9 class AWrapper {public :AWrapper (A *p) { this ->p = p;}AWrapper () { delete p;}operator ->() { return p;}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Array2D {private :int *p;int num1, num2;public :class Array1D {public :Array1D (int *p) { this ->p = p; }int & operator [ ] (int index) { return p[index]; }const int operator [ ] (int index) const { return p[index]; }private :int *p;Array2D (int n1, int n2) {new int [n1 * n2];virtual ~Array2D () {delete [] p;operator [](int index) {return p + index * num2;const Array1D operator [] (int index) const {return p+index*num2;
new的部分
方法:
调用系统存储分配,申请一块较大的内存
针对该内存,自己管理存储分配、去配
通过重载new与delete来实现
重载的new与delete是静态成员(隐式的,不需要额外声明,不允许操作任何类的数据成员)
重载的new与delete遵循类的访问控制,可继承(注意派生类和继承类的大小问题,开始5min左右)
有些我们重复新建销毁的,比如Restful的可以单独管理
可以重载成全局函数,也可以重载成类成员函数,支持定向处理(如下面例子)
1 2 3 4 5 6 7 8 9 10 11 12 13 if (size != sizeof (base))return ::operator new (size);operator new ;new A[10 ];operator new [];void * operator new (size_t size, void *) void * operator new (size_t size, ostream & log) void * operator new (size_t size, void * pointer) class A {};char buf[sizeof (A)];new (buf) A;
delete的部分
void operator delete(void *,size_t size)名:operator delete
返回类型:void
第一个参数:void *(必须):被撤销对象的地址
第二个参数:可有可无;如果有,则必须为size_t类型:被撤销对象的大小
delete 的重载只能有一个
如果重载了delete,那么通过 delete 撤消对象时将不再调用内置的(预定义的)delete
动态删除其父类的所有的。
如果子类中有一个虚继承函数,则size_t大小会根据继承情况进行确定大小
模板是一种代码复用机制,模板定义多个类的时候需要显式实例化,如果用不到的化,则不会实例化模板。
模板是不同于重复耦合和函数重载的一种更高效的解决方案
函数模板的实例化:
隐式实现 根据具体模板函数调用
函数模板的参数
可有多个类型参数,用逗号分隔:template <class T1, class T2>
可带普通参数:
必须列在类型参数之后 :template <class T, int size>调用时需显式实例化,使用默认参数值可以不显式实例化
类型参数和普通参数都可以给出默认参数,但是必须从右侧向左侧给出
1 2 3 4 5 template <class T1 , class T2 >void f (T1 a, T2 b) template <class T , int size>void f (T a) f <int ,10 >(1 );
使用宏解决:#define max(a,b) ((a)>(b)?(a):(b)),只有简单功能,没有类型检查
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 template <typename T>void sort (T A[], unsigned int num) for (int i=1 ; i<num; i++)for (int j=0 ; j< num - i; j++) {if (A[j] > A[j+1 ]) {1 ];1 ] = t;class C {...}300 ];sort (a, 300 );
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 template <class T >class Stack {100 ];public :void push ( T x) T pop () ;template <class T >void Stack <T> ::push (T x) {...}template <class T >pop () {...}int > st1;double > st2;
函数模板一般是在头文件中给出完整的定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 template <class T >class S {public :void f () #include "file1.h" template <class T >void S<T>::f (){...}template <class T >T max (T x, T y) {return x>y?x:y;}void main () int a,b;max (a,b);int > x;f ();#include "file1.h" extern double max (double ,double ) void sub () max (1.1 ,2.2 );float > x;f ();
在头文件中放置类和类属函数的定义,而不放置实现。如果放置实现,则会建议编译器将其作为内联函数及逆行处理。
getter 和 setter 一般会作为内联函数。
内联函数一般会比较短
在Cpp文件中放置类和类属函数的实现
声明全局对象的时候如果没有显式初始化,那么他已经完成了默认初始化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class TDate {public :void SetData (int y,int m ,int d) int IsLeapYear () private :int year,month,day;void TDate::SetDate (int y ,int m ,int d) int TDate::IsLeapYear () return (year%4 == 0 && year % 100 !=0 )||(year % 400 == 0 );
默认构造函数:无参构造函数
构造函数可以设置为Private或者Public(默认)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class A {public :A ();A (int i);A (char *p);A (1 );A a1 (1 ) ;1 ;A ();A ("abcd" );A a3 ("abcd" ) ;"abcd" ;4 ];5 ]={ A (), A (1 ), A ("abcd" ), 2 , "xyz" };
成员初始化表:开辟空间的时候就赋值,而构造函数时在开辟空间结束之后再赋值,先于构造函数执行(按照成员变量声明顺序进行初始化)
成员初始化表可以降低编译器的压力
1 2 3 4 5 6 class CString {char *p; int size;public :CString (int x):size (x),p (new char [size]){}
在构造函数中尽量使用成员初始化表取代赋值动作(如果成员变量没有那么多,不然难以维护)
常量往往是通过成员初始化表的方式来完成初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class A {int m;public :A () {0 ; cout << "A()" << endl;A (int m1) {"A(int m1)" << endl;class B {int x;public :B (){0 ; cout << "B()" << endl;B (int x1){"B(int x1)" << endl;B (int x1, int m1):a (m1){"B(int x1, int m1)" << endl;int main () "_______________" << endl;B b2 (1 ) ; "_______________" << endl;B b3 (1 , 2 ) ;
格式:~<类名>()
功能:RAII:Resource Acquisition Is Initialization(资源获取即初始化)
调用情况
对象消亡时,系统自动调用
C++离开作用域的时候回收
使用delete关键字的时候进行调用
Private的析构函数:(强制自主控制对象存储分配)
回收对象的过程被接管,保证对象在堆上进行创建,但是不能使用delete,那么我们可以在内容提供一个destroy()方法来进行回收
写在栈或者全局区是不能通过编译的(自动调用,发现调不到)
强制在堆上进行创建,对很大的对象而言有好处强制管理存储分配
适用于内存栈比较小的嵌入式系统
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class A {public :A ();void destroy () delete this ;}private :A ();int main () new A;delete p;destroy ();static void free (A *p) delete p; }free (p);
相同类型的类对象是通过拷贝构造函数来完成整个复制过程:自动调用:创建对象时,用一同类的对象对其初始化的时候进行调用。
默认拷贝构造函数
逐个成员初始化(member-wise initialization)
对于对象成员,该定义是递归的
什么时候需要拷贝构造函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 f (A a){}f (b);A f () {return a;f ();public :A (const A& a);
拷贝构造函数私有:目的是让编译器不能调用拷贝构造函数,防止对象按值传递,只能引用传递(对象比较大)
为什么对象是一个引用类型:不然会出现循环拷贝 问题:如果没有引用的话,传参则会拷贝,那么就会出现循环拷贝,记住:A(const A& a)
没有深拷贝的需求的化,使用编译器提供的默认拷贝即可
拷贝函数的初始化
包含成员对象的类
默认拷贝构造函数:调用成员对象 的拷贝构造函数
自定义拷贝构造函数:调用成员对象的默认构造函数 :程序员如果接管这件事情,则编译器不再负责任何默认参数。
拷贝函数的拷贝过程没有处理静态数据成员
默认拷贝构造函数:
逐个成员初始化
对于对象成员,该定义是递归的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class A { int x, y;public :A () { x = y = 0 ; }void inc () class B {int z;public :B (){ z = 0 ; }B (const B& b):{ z = b.z; }void inc () inc (); }int main () inc ();B b2 (b1) ;
常量指针:const <类型> * <指针变量>,不可以修改该指针指向的单元中的值,但是可以修改指向的单元。
在函数式编程中,可以通过对参数中的传递量添加const来保证不会修改原值。
指针常量:<类型>* const<指针变量>,指针在定义的时候初始化,可以修改该指针指向的单元中的值,但是不可以修改指向的单元。
注意变量指针位置上不能传入常量值,但是常量指针上可以传入常量
1 2 3 4 5 6 7 8 9 10 11 void print (int *p) const int c = 8 ;print (c) ;print (&c);void print (const int *p)
声明为const的对象只能调用常成员对象函数
如果是非const的对象,则都可以进行调用
是否const方法真的就不能修改对象里面的值了呢?不是,const只是语法上避免了,但是不是完全不可修改
关键词mutable:表示成员可以再const中进行修改,而不是用间接的方式来做。
去掉const转换:(const_cast)<A*>(this)->x转换后可以修改原来的成员
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class A {int x,y;public :A (int x1, int y1);void f () void show () const void A::f () 1 ; y = 1 ;}void f (A * const this ) void A::show () const void show (const A* const this ) const A a (0 ,0 ) f (); show ();
一个类只有一个,初始化放在类外部,只能初始化一次
为什么声明为静态,而不是全局?
避免名污染问题
避免数据泄漏
1 2 3 4 5 class A {int x,y;static int shared;int A::shared=0 ;
只能存取静态成员变量,调用静态成员函数 遵循类访问控制:在类上直接访问只能是静态成员变量
类也是一种对象,可以通过类直接调用静态方法
通过对象使用:A a;a.f();
通过类使用:A::f();
例子:查看已经创建的实例数量
1 2 3 4 5 6 7 8 9 class A {static int obj_count;public :A (){obj_count++;}A (){obj_count--;}static int get_num_of_obj () int A::obj_count=0 ;int A::get_num_of_obj () return obj_count; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class singleton {protected :singleton (){}singleton (const singleton &);public :static singleton *instance () return m_instance == NULL ? new singleton: m_instance;static void destroy () delete m_instance; m_instance = NULL ; }private :static singleton *m_instance;NULL ;
声明的时候不需要声明继承
1 2 3 4 class Undergraduated_Student : public Student;class Undergraduated_Student ;
派生类中对父类的重名方法是重写,期望被重写的部分的前面添加Virtual来保证子类重写。
父类中的所有部分都会被子类的名空间覆盖,但是通过命名空间也可以访问,如果父类中的public方法没有被子类复写,则可以调用
构造函数、析构函数和运算符重载函数是不会被继承的。
1 2 3 4 5 class B : public A{public :using A::A;
protected:
如果没有继承的话,protected和private的访问权限是相同的
派生类可以访问基类中protected的属性的成员。
派生类不可以访问基类中的对象 的protected的属性。
派生类含有基类的所有成员变量
子类修改访问权限
1 2 3 4 5 6 7 8 class Student {public :char nickname[16 ];class Undergraduated_Student : public Student {}private :
public继承:class A: public B
原来的public是public,原来的private是private
如果没有特殊需要建议使用public
IS A关系
private继承:class A: private B
private:原来所有的都是private,但是这个private是对于Undergraduate_Student大对象而言,所以他自己还是可以访问的。
默认的继承方式
Has A关系
派生类对象的初始化:由基类和派生类共同完成
构造函数的执行次序
基类的构造函数
派生类对象成员类的构造函数(注意!)
派生类的构造函数
析构函数的执行次序(与构造函数执行顺序相反)
派生类的析构函数
派生类对象成员类的析构函数
基类的析构函数
基类构造函数的调用
缺省执行基类默认构造函数
如果要执行基类的非默认构造函数 ,则必须在派生类构造函数的成员初始化表中指出
多继承语法
1 2 3 class <派生类名> :[<继承方式> ] <基类名1> ,<继承方式> ] <基类名2> ,…
名冲突则使用命名空间来解决
基类的声明次序决定:
对基类构造函数/析构函数的调用次序(顶部基类,同层基类按照声明顺序) 上图中就是 ABCD的顺序
对基类数据成员的存储安排
析构函数正好相反
如果直接基类有公共的基类,则该公共基类中的成员变量在多继承的派生类中有多 个副本
如果有一个公共的虚基类,则成员变量只有一 个副本
类D有两个x成员,B::x,C::x
虚继承:保留一个虚指针
虚指针指向A
可以认为是一个组合关系
合并
1 2 3 4 5 class A ;class B : virtual public A;class C : public virtual A;class D : B, C;
一个类只有一个虚函数表
虚函数是指一个类中你希望重载的成员函数,但你使用一个基类指针或引用指向一个继承类对象的时候,调用一个虚函数时,实际调用的就是继承类的版本。
如基类中被定义为虚成员函数,则派生类中对其重定义的成员函数均为虚函数
类型相容:
类型相容是指完全相同的(别名)
一个类型是另一个类型的子类型(int -> long int)
赋值相容(不会丢失信息):对于类型相同的变量才有(a = b)
如果类型相同可以直接赋值
子类型可以赋值给父类型
A a; B b; class B: public A
对象的身份发生变化(a和b都代表栈上对应大小的内存),B类型对象变为了A类型的对象
属于派生类的属性已不存在
将派生类对象赋值给基类对象->对象切片
A a = b:调用拷贝构造函数const A &a:函数必然包含的拷贝构造函数中的参数B* pb; A* pa = pb; class B: public A
因为是赋值相容的,所以可以指针赋值
这种情况类似Java
B b; A & a=b; class B: public A:对象身份没有发生变化(还是B)
传参的时候尽量不要拷贝传参(存在对象切片问题),而是使用引用传参。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class A {int x,y;public :void f () class B : public A{int z;public :void f () void g () f (); func1 (A& a){a.f ();}func1 (b);
编译时刻确定调用哪一个方法
依据对象的静态类型
效率高、灵活性差
静态绑定根据形参决定
晚绑定是指编译器或者解释器在运行前不知道对象的类型,使用晚绑定,无需检查对象的类型,只需要检查对象是否支持特性和方法即可。
c++中晚绑定常常发生在使用virtual声明成员函数
运行时刻确定,依据对象的实际类型(动态)
灵活性高、效率低
动态绑定函数也就是虚函数。
直到构造函数返回之后,对象方可正常使用
C++默认的都是静态绑定,Java默认的都是动态绑定
虚函数表
p->f():需要寻找a和b中的f()函数地址
如果不能明确虚函数个数,没有办法索引
虚函数表(索引表,vtable):大小可变
首先构造基类的虚函数表
然后对派生类中的函数,如果查找了,则会覆盖对应函数来生成虚函数表
对象内存空间中含有指针指向虚函数表
(**((char *)p - 4))(p):f的函数调用(从虚函数表拿数据),p是参数this空间上和时间上都付出了代价
空间:存储虚函数表指针和虚函数表
时间:需要通过虚函数表查找对应函数地址,多调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class A {public :A () { f ();}virtual void f () void g () void h () f ();g ();class B : public Apublic :void f () void g () f (); g (); h ();
尽量不要在构造函数中调用虚函数
此时的虚函数就是和构造函数名空间相同
h()函数是非虚接口
有不同的实现:调用了虚函数和非虚函数
可以替换部分的实现
可以使得非虚函数具有虚函数的特性(让全局函数具有多态:将全局函数做成非虚接口)
类的成员函数才可以是虚函数:全局函数不可以是虚函数
静态成员函数不能是虚函数:静态的成员函数属于类,并不属于一个对象,所以不能虚函数
内联成员函数不能是虚函数:内联成员函数在编译的时候就已经确定了
构造函数不能是虚函数:
因为创建类的时候是自动调用的,父类的指针无法直接调用,虚函数没有意义
虚函数表是在构造函数中完成的
析构函数可以(往往)是虚函数:如果不是虚函数,不好调用到派生类中的析构函数(delete一个父类指针,如果非虚,不能调用到派生类的析构函数)
如果有继承的话,最好使用虚析构函数,在调用析构的函数,会先 调用基类的析构函数,所以:
在析构函数中,只需要析构派生类自己的资源就可以了
override:希望以虚函数的形式写:编译器报错,防止漏写virtual问题
final:不可以再次重写
1 2 3 4 5 6 7 8 9 10 11 12 13 class B {public :void mf () class D : public B { public :void mf () mf ();mf ();
这样子的话,同一个对象使用不同指针会有不同的行为。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class A {public :virtual void f (int x = 0 ) 0 ;class B : public A{public :virtual void f (int x = 1 ) { cout << x;}f ();class C : public A{public :virtual void f (int x) f ();
声明时在函数原型后面加上 = 0 :virtual int f() = 0;
往往 只给出函数声明,不给出实现:可以给出实现,通过函数外进行定义(但是不好访问,因为查到是0)子类必须继承接口,并给出实现
1 2 3 4 int f () 0 ;int f ()
至少包含一个纯虚函数
不能用于创建对象:抽象类类似一个接口,提供一个框架
为派生类提供框架,派生类提供抽象基类的所有成员函数的实现
Step1:提供Windows GUI类库:WinButton
1 2 3 4 WinButton *pb= new WinButton ();SetStyle ();new WinLabel ();SetText ();
step2:增加对Mac的支持:MacButton,MacLabel
1 2 3 4 MacButton *pb= new MacButton ();SetStyle ();new MacLabel ();SetText ();
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 Button *pb= new MacButton ();SetStyle ();new MacLabel ();SetText ();class AbstractFactory {public :virtual Button* CreateButton () 0 ;virtual Label* CreateLabel () 0 ;class MacFactory : public AbstractFactory {public :MacButton* CreateButton () { return new MacButton; }MacLabel* CreateLabel () { return new MacLabel; }class WinFactory : public AbstractFactory {public :WinButton* CreateButton () { return new WinButton; }WinLabel* CreateLabel () { return new WinLabel; }class Button ; class MacButton : public Button {}; class WinButton : public Button {}; class Label ; class MacLabel : public Label {}; class WinLabel : public Label {};switch (style) {case MAC:new MacFactory;break ;case WIN:new WinFactory;break ;CreateButton ();CreateLabel ();
抽象工厂模式的类图