2019-数据结构-数据结构4.1-specific Tree
4.1 搜索树
1. 二叉搜索树
- Definition: A binary search tree is a binary tree that may be empty. A nonempty binary search tree satisfies the following properties:(二叉搜索树是一个可以为空的二叉树。一个非空的二叉树都满足如下性质)
- Every element has a key and no two elements have the same key; therefore,all keys are distinct. (每一个元素都含有一个关键字,并且每一个元素都有独一无二的关键字)
- The keys(if any)in the left subtree of the root are smaller than the key in the root.(一个树的左子树的关键字小于根中的关键字)
- The keys(if any)in the right subtree of the root are larger than the key in the root.(一个树的右子树的关键字大于根中的关键字)
- The left and right subtrees of the root are also binary search trees.(根的左右子树还是二叉搜索树)
- 二叉搜索树需要满足的事情:在很大的数据量下,要能够很快的进行增删查改。这也就是二叉搜索树的优越性。
1.1. 二叉搜索树的结构

1.1.1. 二叉搜索树的实现(java)
1 | |
1.1.2. 二叉搜索树需要实现的方法
1 | |
删除算法
- 如果结点本身不在树内,那么不需要删除
- 如果结点本身在树里面,删除需要分类
- 无子树:删除叶节点
- 一颗子树:直接连接
- 两颗子树:可以选择左子树的最大结点作为新结点
1 | |
高度
- The height of a binary search tree has influence directly on the time complexity of operations like searching, insertion and deletion. 二叉搜索树的高度会影响搜索,插入和删除算法的搜索度
- Worst case: add an ordered elements{1,2,3…n} into an empty binary search tree. 最坏的情况就是把一个有序的数列添加进入到空的二叉搜索树中去。
二叉搜索树的算法复杂度
- 二叉搜索树以上的所有操作都和二叉搜索树的深度有关,所以在生成二叉树的时候我们需要保证二叉搜索树的平衡性,(如果一开始输入最小的,树严重失衡,如果一开始输入中等,树基本平衡)
- Best Case:O(log2n)
1.2. 索引二叉树
- An indexed binary search tree is derived from an ordinary binary search tree by adding the field leftSize to each tree node. 索引二叉搜索树是通过将字段leftSize添加到每个树节点,从普通二叉搜索树派生而来的。
- Value in Leftsize field=number of the elements in the node’s left subtree +1(leftsize = 左子树大小 + 1)

- Eg.

2. AVL Tree(自平衡的二叉搜索树)
- 目的:the AVL tree was introduced to increase the efficiency of searching a binary search tree, and to decrease the average search length. AVL树是一个用来增加二叉搜索树的平衡性并且减小平均搜索高度
- AVL的高度是O(log2n)的,所以对应的算法复杂度也是这样的。
2.1. 什么是AVL树
- AVL树是一个二叉搜索树
- AVL树的每一个节点满足|hL-hR|<=1 where hL and hR are the heights of TL(left subtree) and TR(right subtree),respectively.对于每一个结点,其左子树和右子树的高度之差不超过1
- 注:树叶之间之差未必小于一,但是一个节点的左右子树的高度不能大于一
2.2. AVL树的基本概念
- AVL树高:the longest path from the root to each leaf node(从根节点到每一个叶节点之间的所有路径的最长的一条)
- Balance factor bf(x) of a node x : height of right subtree of x – height of left subtree of x 节点x的平衡因子 = x的右树的高度-x的左树的高度
2.3. AVL树的结点的实现

2.4. AVL树的实现
- 这个例子里每个结点中存储着树高
- 树高之差就是平衡因子
1 | |
2.5. AVL树的基本操作
2.5.1. AVL树的查询
查询过程和正常的二叉搜索树是相同的,其算法复杂度和正常二叉搜索树的搜索算法的复杂度是相同的。
2.5.2. AVL树的插入
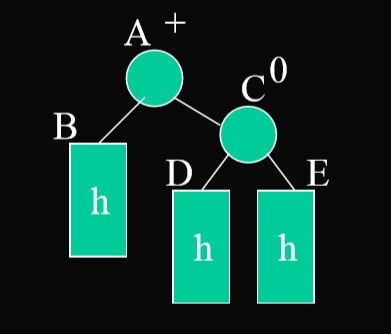
- 简单来看,每一个子树都可以被看为如上的图
- 算法流程:是递归从下向上进行旋转处理,先看子树。
插入C的右子树E(外侧结点)

- 只需要进行一次左单旋转即可
- 左单旋转过程如上
插入C的左子树D(内侧结点)
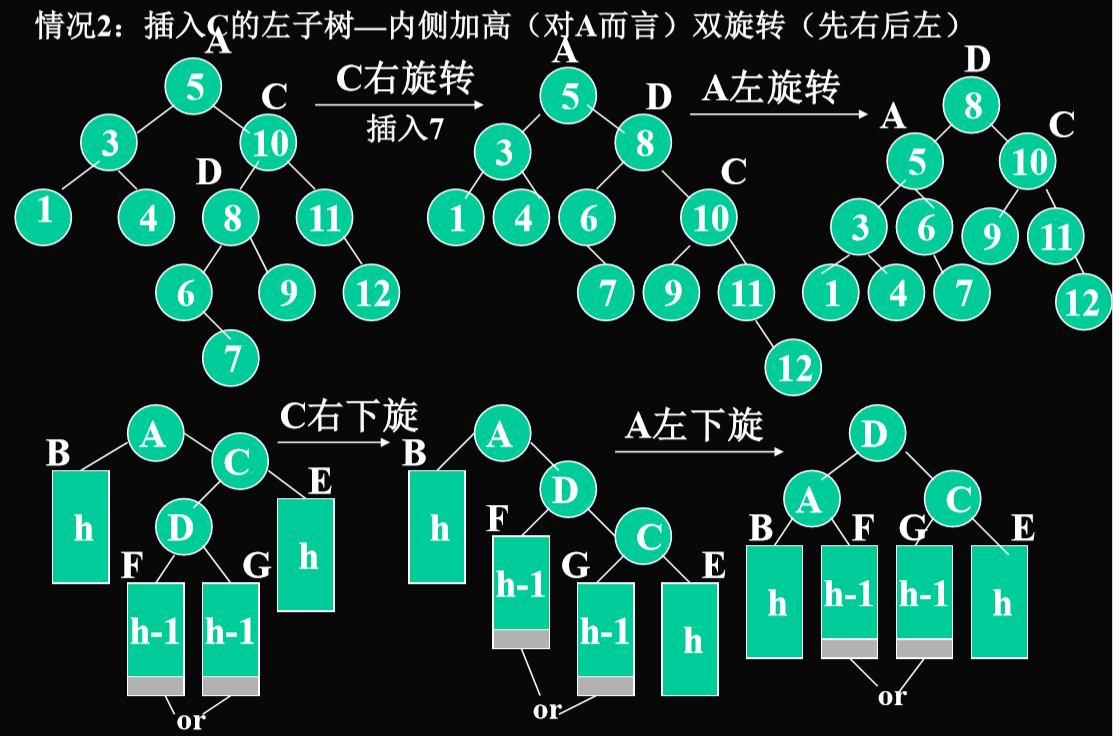
- 需要进行一次双旋转(先右后左)
插入其他地方,树不需要转

- 一直到5的时候,树的平衡性才受到影响
- 插入后,树的平衡性没有被破坏显然不用旋转
- 调整只要在包含插入结点的最小不平衡子树中进行,即从到达插入结点的路径上,离插入结点最近的,并且平衡系数!=0的结点为根的子树.
算法思想与总结
-
算法思想:插入一个新结点后,需要从插入位置沿通向根的路径回溯,检查各结点左右子树的高度差,如果发现某点高度不平衡则停止回溯。
- 先确定节点是在外侧还是内侧,决定是单旋还是双旋
-
单旋转:外侧—从不平衡结点沿刚才回溯的路径取直接下两层如果三个结点处于一直线A,C,E
-
双旋转:内侧—从不平衡结点沿刚才回溯的路径取直接下两层如果三个结点处于一折线A,C,D
-
以上以右外侧,右内侧为例,左外侧,左内侧是对称的。与前面对称的情况:左外侧,左内侧 左外侧
- 右下旋

- 左下旋

- 右内侧
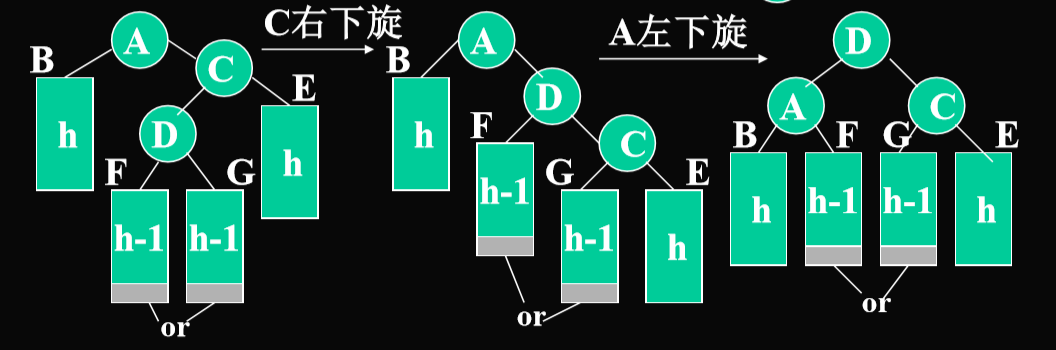
- 左内侧

- 右下旋
-
插入:
- 首先要找到正确的位置进行插入
- 找到有可能发生不平衡的最小不平衡子树
- 判别插入在不平衡子树的外侧还是内侧
- 根据3的判别结果,再进行单旋还是双旋
例子(从空的AVL树建树的算法)

- 右双旋转:先变成ACZ,再把AC旋转下去。
- 左子树的左子树是左外侧,左子树的右子树是左外侧,右子树的左子树是右内侧,右子树的右子树是右外侧
- 判断内侧外侧只从被破坏根节点向下2层。
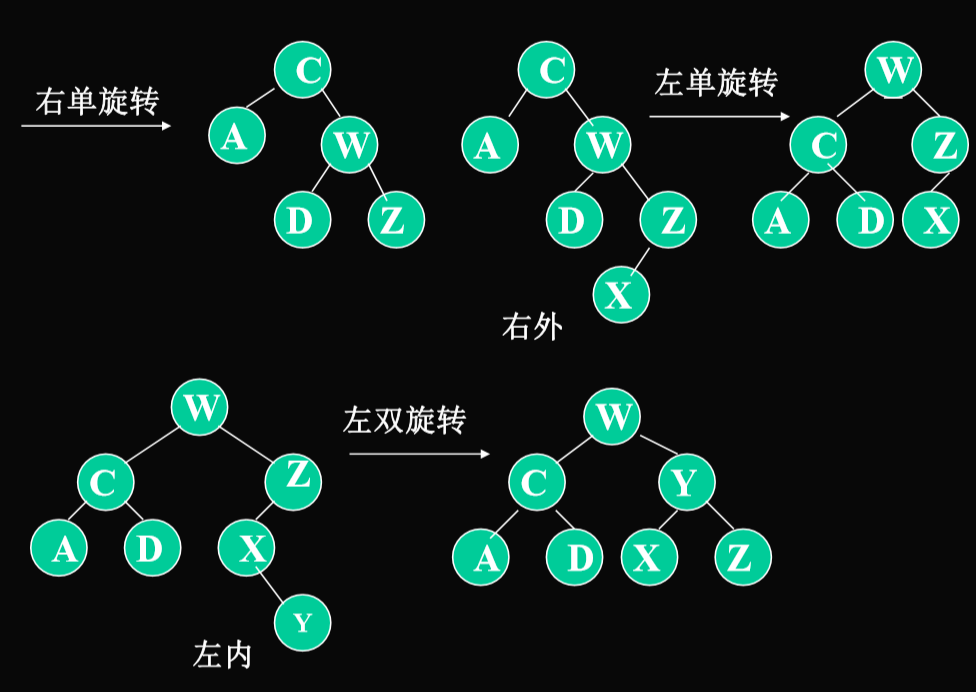
- 判断内侧外侧只从被破坏根节点向下2层。
插入算法代码
1 | |
右下旋
1 | |
左下旋
1 | |
右内侧
1 | |
左内侧
1 | |
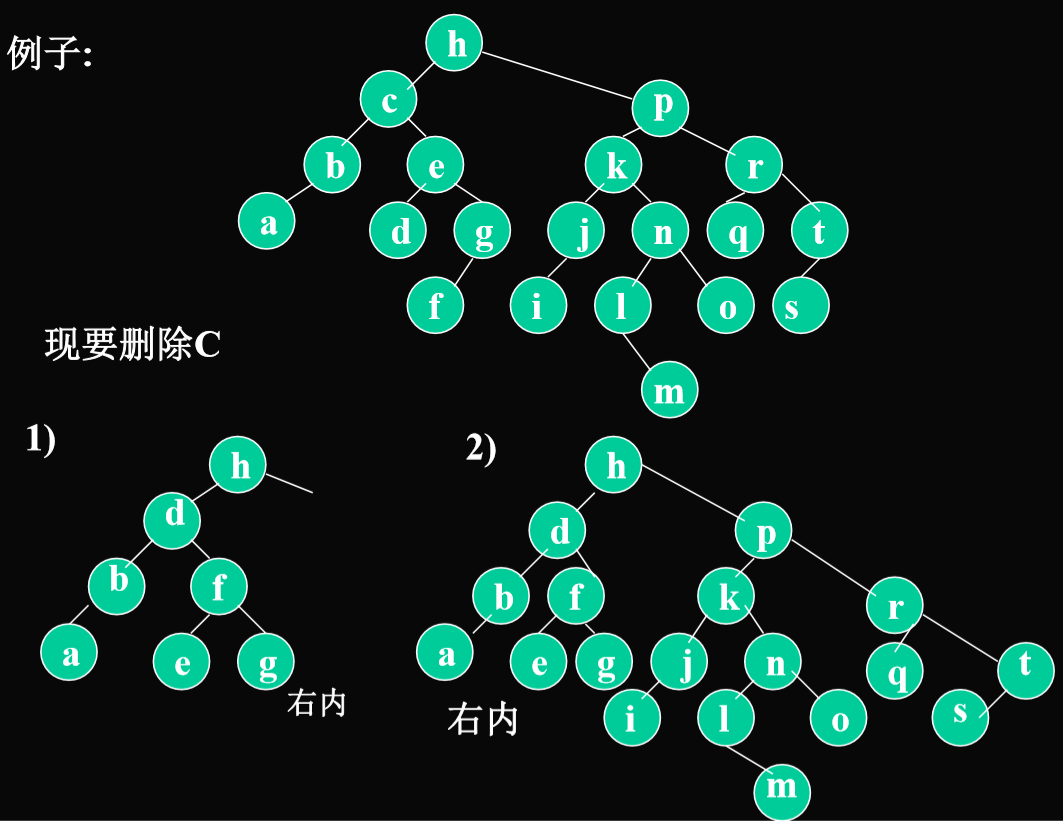
2.5.3. AVL树的删除
- 方法和二叉搜索树的删除方法一样

- 需要找到被删除顶点的中序后继。
- 等待再看一下。
例子

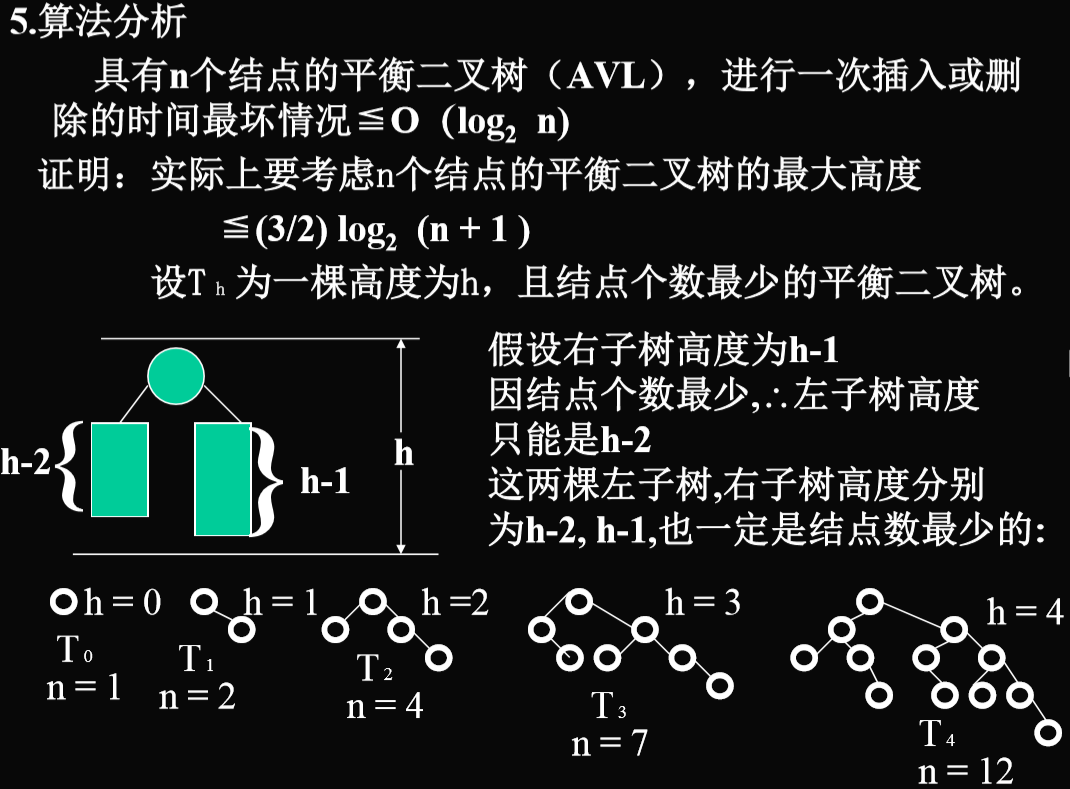
2.5.4. 算法复杂度分析(不做要求)


3. B-TREES
3.1. m叉搜索树
3.1.1. m叉搜索树的定义
- Definition: An m-way search tree may be empty. If it is not empty, it is a tree that satisfies the following properties: m-way搜索树可能为空。如果是一个非空的树,则为满足以下属性的树:
- In the corresponding extended search tree(obtained by replacing zero pointer with external nodes), each internal node has up to m children and between 1 and m-1 elements.(在相应的扩展搜索树(用外部节点替换零指针获得)中,每个内部节点最多有m个子节点,在1和m-1元素之间。)
- Every node with p elements has exactly p+1 children.(每个具有p元素的节点正好有p+1子节点。)
- Consider any node with p elements:
 k1 < k2 <……< kp, c0,c1,……,cp be the p+1 children of the node 假设任何节点都有p个元素,那么C0 - Cp是他们对应的p+1个子元素。
k1 < k2 <……< kp, c0,c1,……,cp be the p+1 children of the node 假设任何节点都有p个元素,那么C0 - Cp是他们对应的p+1个子元素。
- 对于中的节点:
- C0: The elements in the subtree with root c0 have keys smaller than k1(在以C0为根的所有子树中的结点的值都小于k1)
- Cp: Elements in the subtree with root cp have keys larger than kp(在以Cp为根的子树中的所有子树的值都大于Kp)
- Ci: Elements in the subtree with root ci have keys larger than ki but smaller than ki+1, 1<=i<=p.
- m叉搜索树的例子:
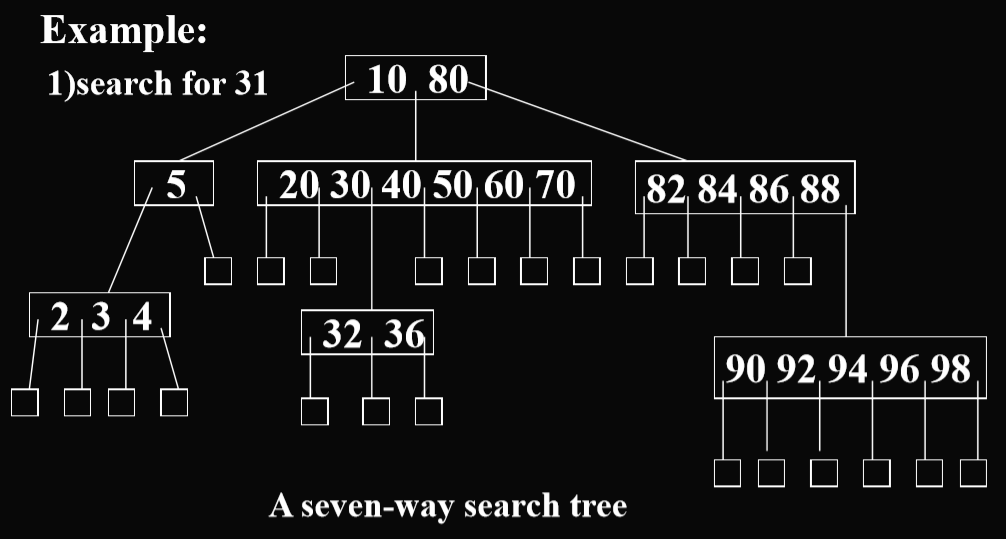
- m叉搜索树是可以存入磁盘的。
3.1.2. 操作
插入操作
- 如果一层没有满,就在同一级进行插入。(针对的是m叉的情况)
- 如果这一层已经满了,那么在下一层进行插入。
- 例子

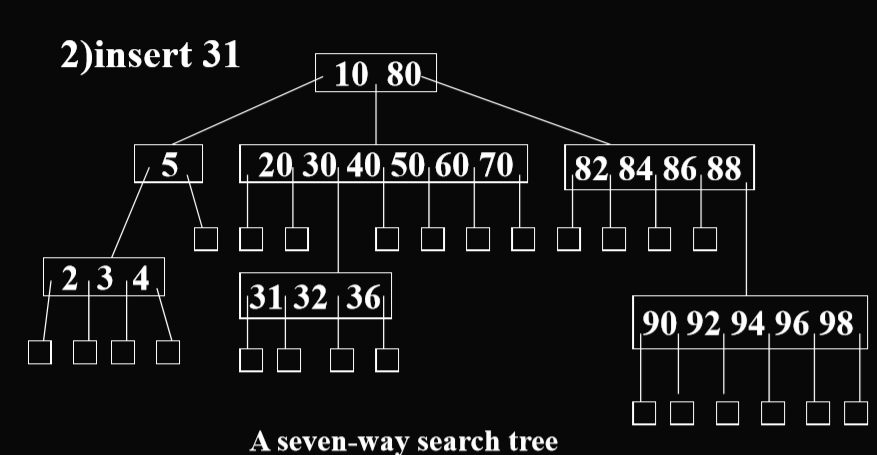
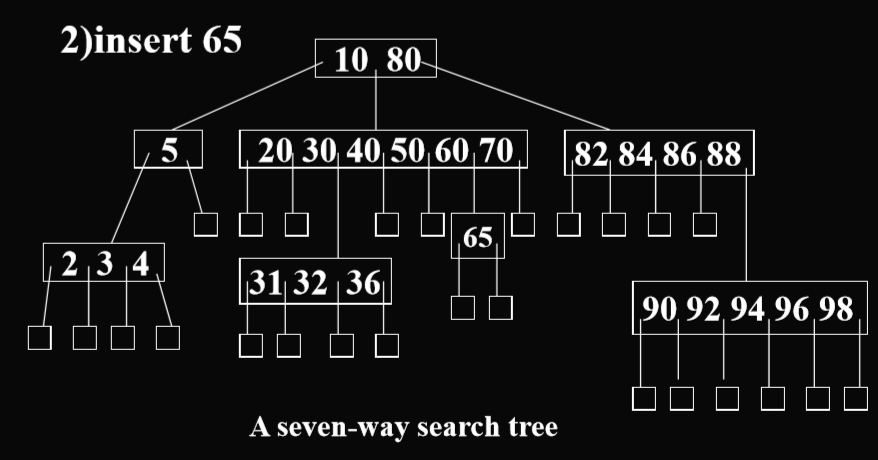
- 注:n叉搜索树,每一层一个结点最多有n-1个元素
删除操作
-
删除元素不会影响树的叉数,物理层次影响叉数。
-
类型一:同一层还有节点,直接删除没有影响

-
类型二:本层删除后没有节点,所以需要把底下能合适的最大(最小)的进行提升

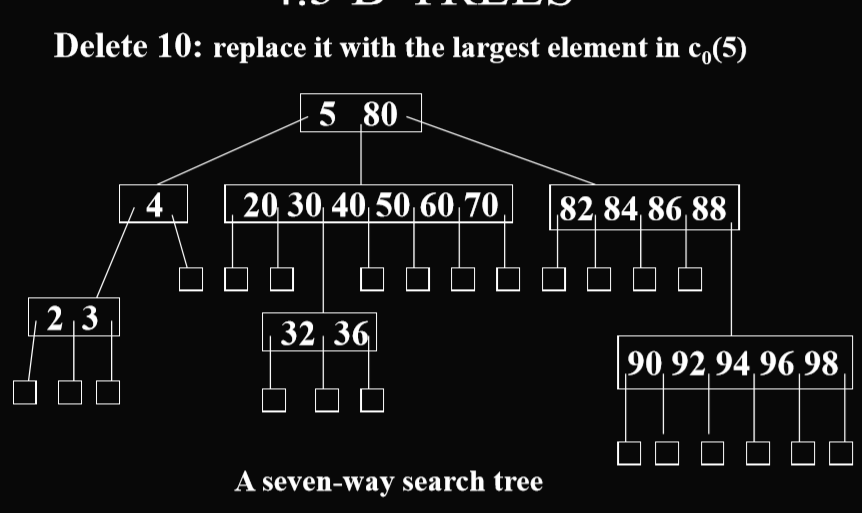

查找m叉搜索树的行高
- Height of an m-way search tree(m叉二叉树的行高)
- An m-way search tree of height h may have as few as h elements(one node per level), as many as mh-1 elements.(一个高为h的m路搜索树最少有h个结点(每一层只有一个结点),最多有mh-1个结点)
- The height of a m-way search tree with n elements is between logm(n+1) and n
- n: 2005-1 =32*1010-1
3.2. 平衡的m路搜索树——B树
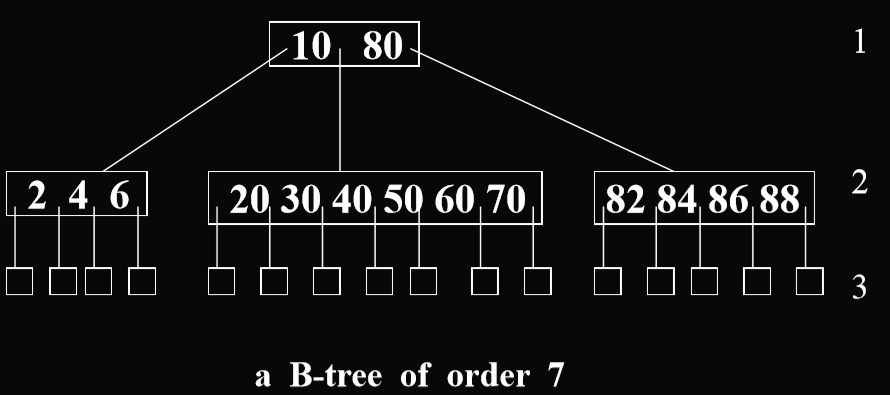
- Definition : A Btree of order m is an m-way search tree. If the Btree is not empty, the corresponding extended tree satisfies the following properties:m阶的B树是一个m叉搜索树。如果B树不为空,则B树有相应的扩展属性:
- the root has at least two children(每个根结点至少有两个子女)
- all internal nodes other than the root have at least m/2(向上取整) children(所有内节点都至少有m/2(向上取整)个子结点)
- all external nodes are at the same level(所有的外节点必须都在同一层)
- Eg.
- 早一点的数据库用的是B树,现在大数据数据库是B+树。
- Eg1. In a Btree of order 2, each internal node has at least 2 children, and all external nodes must be on the same level, so a Btree of order 2 is full binary trees (在二阶B树中,每一个内部节点都有至少2个子女,并且所有的外部节点都必须在同一级上,所以2阶B树是满阶二叉树)
- Eg2. In a Btree of order 3(sometimes also called 2-3 tree), each internal node has 2 or 3 children(在三阶B树中(通常被我们叫做2-3树),每一个内部节点有2个或者3个子女)
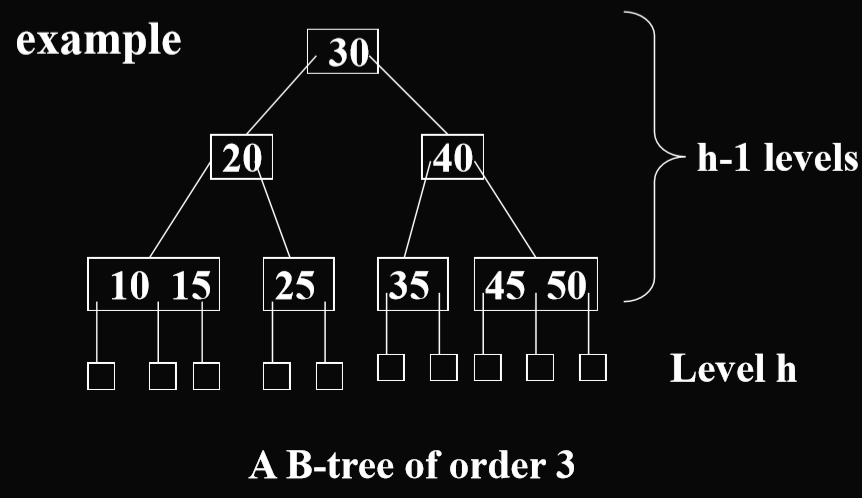
3.2.1. B树性质
- 外节点个数是总共的k值加一
- all external nodes are on the same level(所有的外部结点都有相同的层数)
- number of external nodes = number of keywords + 1(外部节点的个数等于关键字个数+1)
- 证明:b1(第一层节点数,不分内外) = k0 + 1, b2 = k1 + b1,b3 = k2 + b2, …… , 外部结点=kh-1+kh-2+…+k1+k0+1=n+1
- 总的来说就是使用归纳的方法来做
3.2.2. B树搜索算法
- A Btree is searched using the same algorithm as used for an m-way search tree. B树的搜索算法和m叉搜索树的搜索算法是一样的。
- Algorithm analysis:(算法分析)
- the number of disk access is at most h(h is the height of the BTree).(对于高度为h的B树,访问磁盘的次数最多为h次)
- proof: T is a BTree of order m with height h, number of elements in T is n, each time we read a node into memory. The n+1 external nodes are on level h.(T是m阶高度为h的B树,在T中的结点个数为n,每一次我们把一个结点读入内存。那么n+1个外部结点在第h层)
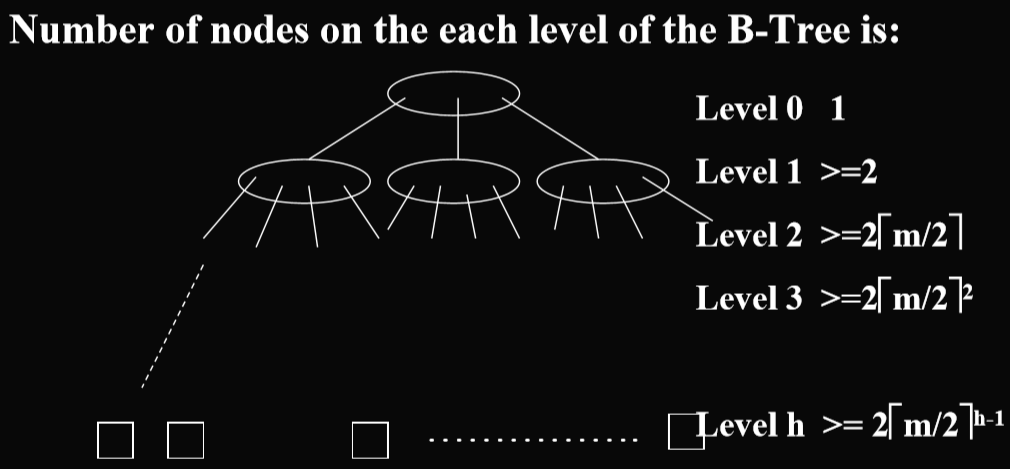
- 考虑最坏情况下的B树的搜索算法

3.2.3. B树插入算法
- B树的插入问题经常发生在外部结点的上一层
算法思想
- 做插入的时候优先插入叶节点:
- 如果叶节点还没有满的时候,直接插入即可
- 如果叶节点已经满了的时候,会进行分类,将中间节点的一个值拉到上级结点(这个结点在中间)。
- Insert into a node with m children (also called a full node), like insert 25 into the BTree in the last example, the full node is split into two nodes.(插入到一个有m个子结点的节点中,比如25插入上面那个例子中,满了的节点会分裂成两个节点,就是把中间的提升,将剩下的裂开)
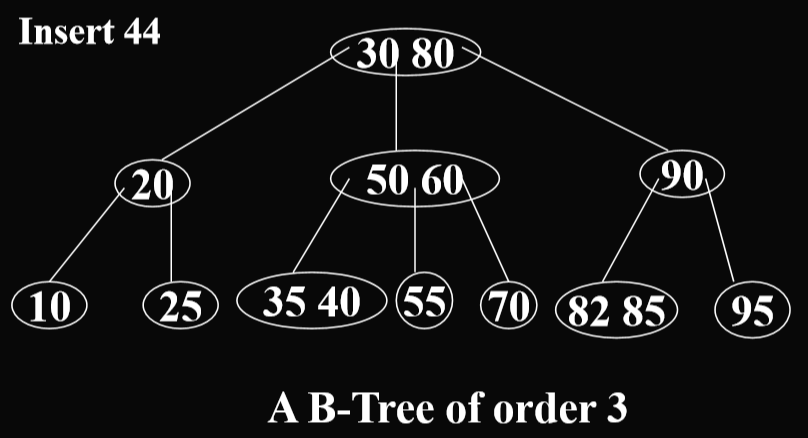
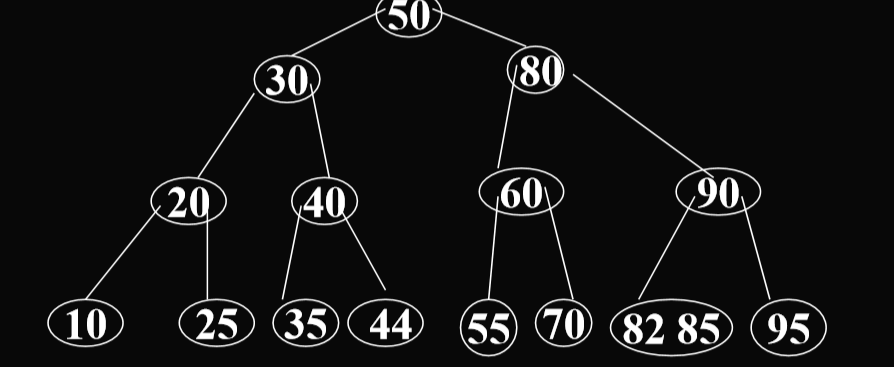
- A new pointer will be added to the parent of the full node.(一个新的指针会被添加指向满了的结点的父结点)
- Because km/2(向上取整) is inserted into parent node, it may cause new split. If the root is split,the height of the tree will increased by 1.(因为km/2(向上取整))
算法分析
- If the insert operation causes s node to split, the number of disk access is h (to read in the nodes on the search path) +2s (to write out the two split parts of each node that is split) +1 (to write the new node).
- 如果插入操作会导致s个结点进行分裂,那么磁盘查找次数为 树高h(在搜索路径上读,查找)+2s(写入2s次的分裂)+1(有可能是创建新的结点,也可能是修改一个节点)
3.2.4. B树的删除算法
- 首先判断删除的关键码是否都在B树中,不在的话直接退出。
- case1:The element to be deleted is in a node whose children are external nodes(i.e.the element is in a leaf)(将要被删除的元素的关键码的子节点是外部结点[小正方形])
- 如果有超过(m/2)(向上取整)个关键码,直接删除
- 如果关键码个数不足(m/2)(向上取整)个,那么向邻居借关键码,如果够借,那么进行调整。如果不够借,那么合并邻居与此节点(还要拉下来一个上级节点的关键码),这样子也可能会导致上级节点的关键码不足,如果根节点合并,则其高度被减少1。
- case2: The element is to be deleted from a nonleaf. (要被删除的结点是一个非叶节点)
- 删除这个节点
- 把这个节点替换成右子树中的最小关键码(或者左子树中的最大关键码)
- 因为相当于删除了右子树的最小关键码(或者左子树中的最大关键码),所以重复删除叶结点关键码的操作。
- 找邻居借关键码的例子:
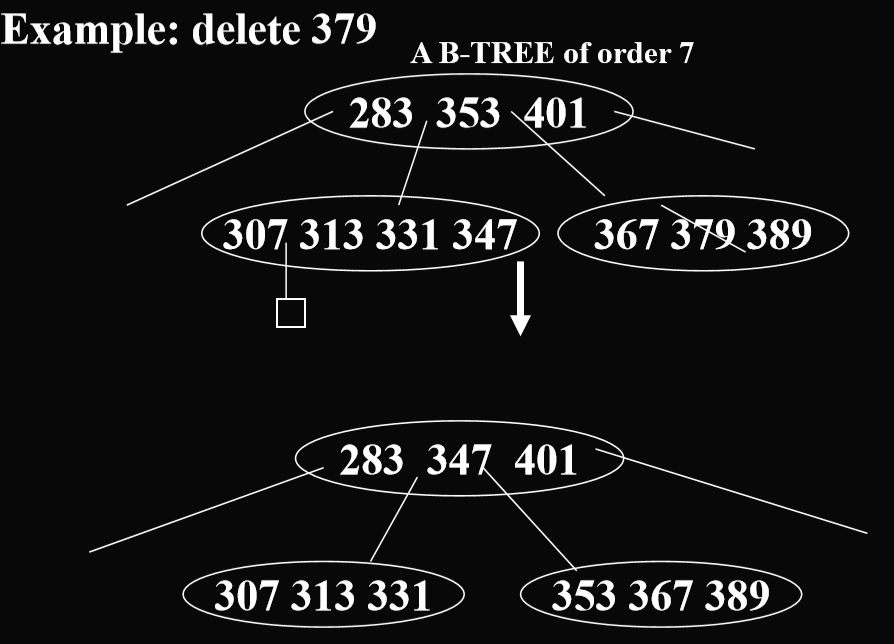
- 删除后两部分合并的例子:
- 向邻居借关键码,347 -> 353,353 -> 下面
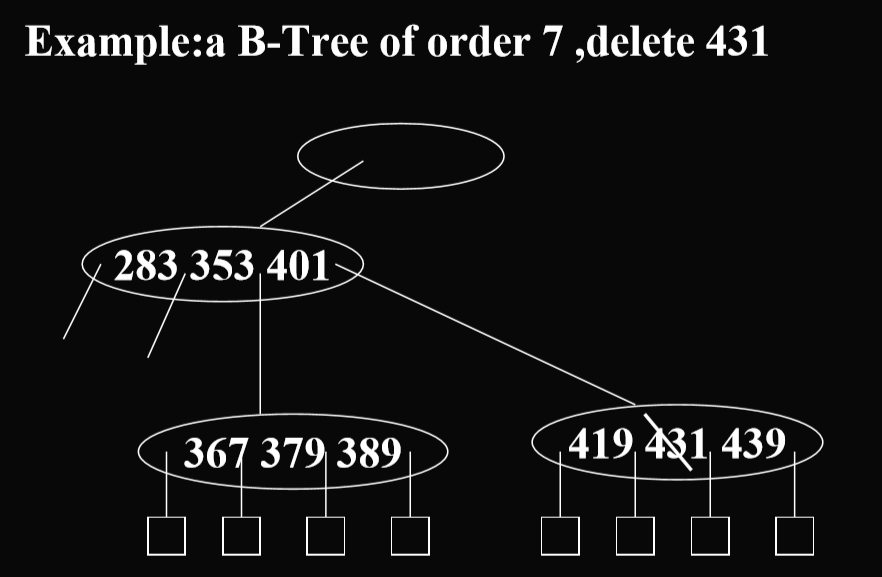
3.3. B树的实现

- S is the number of elements in the node(是节点的元素的个数)
- ei are the elements in ascending order of key(将元素按照键值升序排列)
- Ci are children pointers(子树结点)
4. B+ tree
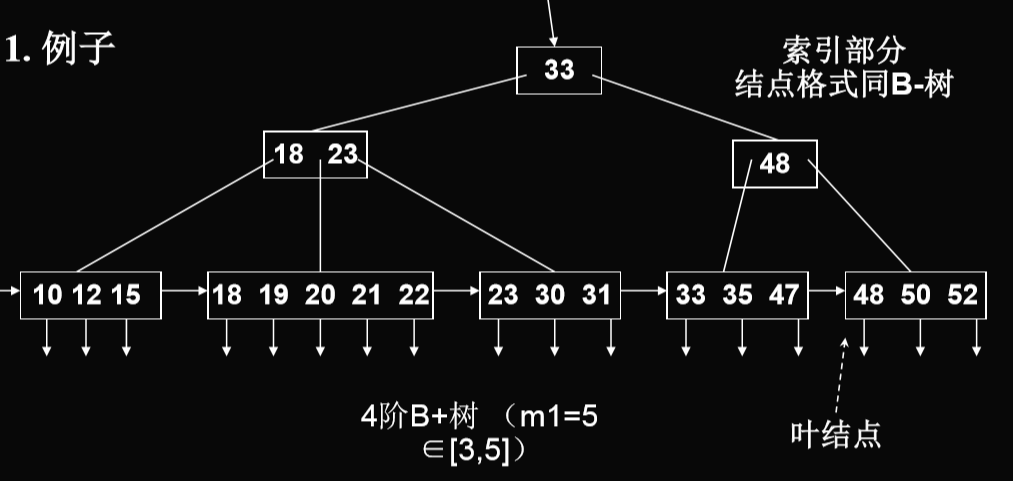
- 和B树不同的地方:
- 关键码的分布,只分布在叶结点上
- 叶结点的定义,不一定符合m阶,它依赖于关键码字节数与指针字节数而为m1
4.1. B+ tree的定义
- 树中每个非叶结点最多有m棵子树
- 根结点(非叶结点)至少有2棵子树
- 除根结点外,每个非叶结点至少有(m/2)(向上取整)棵子树;有n棵子树的非叶结点有n-1个关键码
- 所有叶结点都处于同一层次上,包含了全部关键码及指向相应数据对象存放地址,关键码按关键码从小到大顺序链接
- 每个叶结点中子树棵树n可以>m,也可以<m。 假设叶结点可容纳的最大关键码数为m1,则指向对象的指针数也有m1,这时子树棵数n应满足((m1/2)(向上取整),m1)
- 根结点本身又是叶结点,则结点格式同叶结点
4.2. B+ tree的特点
- 有两个头指针
- 一个指向B+树的根结点,可以进行自顶向下的随机搜索
- 一个指向关键码最小的叶结点,进行顺序搜索;
- 保证树过深,用来进行平衡
4.3. B+ tree的运算
搜索算法
基本上同B树,所不同的是一直查到叶结点上的这个关键码为止
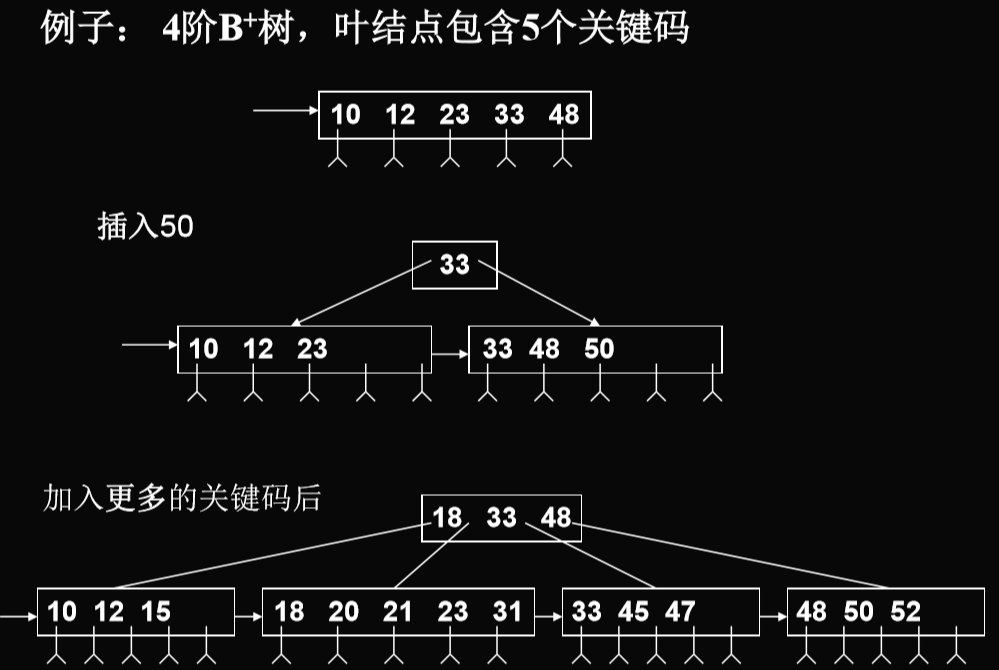
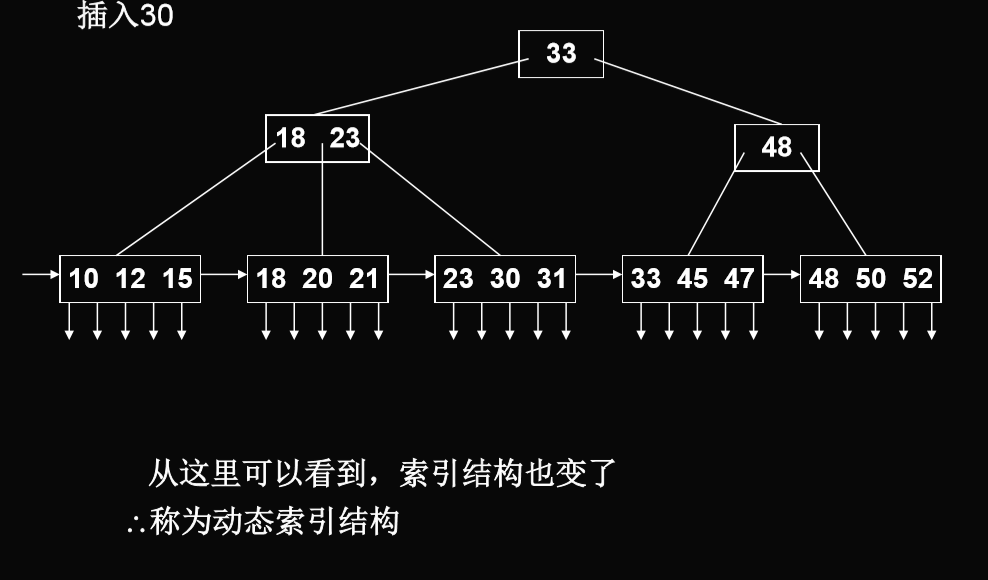
插入算法
- 仅在叶结点上进行。每插入一关键码,判别子树棵树>m1,如果大于,则将该结点分裂:((m1+1)/2)(向上取整),((m1+1)/2)(向上取整)
- 问题变为传递到索引结点上可能的分裂,这时上限以m来确定(同B-树)
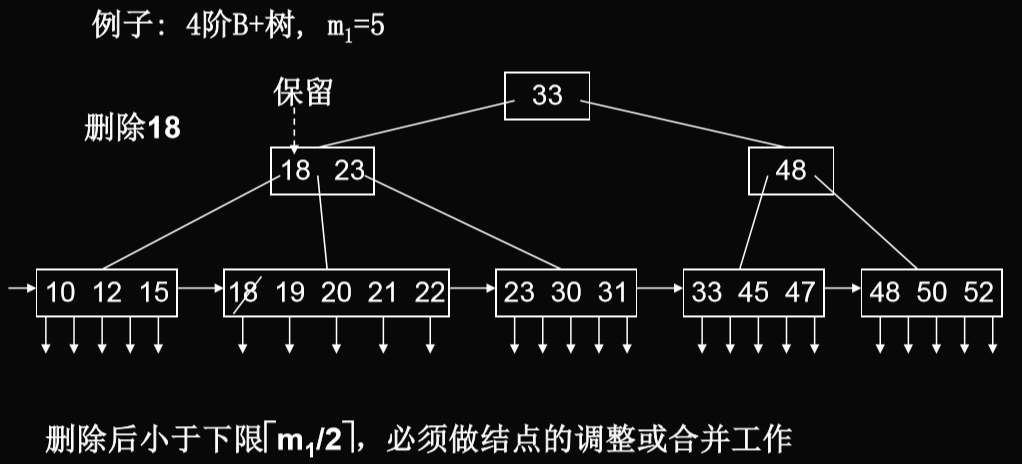
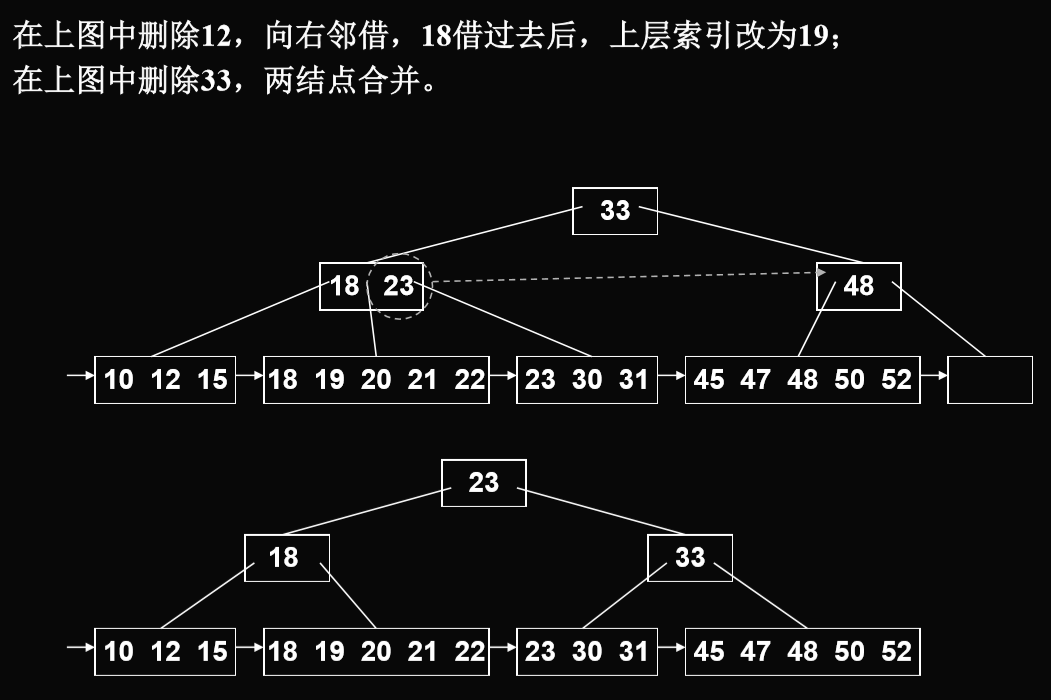
删除算法
- 在叶结点上删除一个关键码后要保证结点中的子树棵数仍然不小 于(m1/2)(向上取整).
- 删除操作与B树类似,但上层索引中的关键码可保留,作为引导搜索的"分界关键码"的作用.
5. 题目
- 第9题:
- 邻居的60及它左侧的55被一同借过去
- 20和30成为一个节点,同级的有55,上层50
- 直接删除40,60((50((20,30),55)),80(70,95))
6. 其他参考以及扩展学习
2019-数据结构-数据结构4.1-specific Tree
https://spricoder.github.io/2020/01/17/2019-Data-Structure/2019-Data-Structure-%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%844.1-specific%20Tree/